Коли використовувати регресію ridge & lasso
У звичайній множинній лінійній регресії ми використовуємо набір із p предикторних змінних і змінну відповіді, щоб відповідати моделі такого вигляду:
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p
Значення β 0 , β 1 , B 2 , …, β p вибираються методом найменших квадратів, який мінімізує суму квадратів нев’язок (RSS):
RSS = Σ(y i – ŷ i ) 2
золото:
- Σ : символ, що означає «сума»
- y i : фактичне значення відповіді для i-го спостереження
- ŷ i : прогнозоване значення відповіді для i- го спостереження
Проблема мультиколінеарності в регресії
Проблемою, яка часто виникає на практиці з множинною лінійною регресією, є мультиколінеарність – коли дві або більше змінних предикторів сильно корельовані одна з одною, так що вони не надають унікальної чи незалежної інформації в моделі регресії.
Це може зробити оцінки коефіцієнтів моделі ненадійними та мати високу дисперсію. Тобто, коли модель застосовується до нового набору даних, який вона ніколи раніше не бачила, вона, ймовірно, працюватиме погано.
Уникнення мультиколінеарності: регресія Ridge & Lasso
Два методи, які ми можемо використати, щоб обійти цю проблему мультиколінеарності, це хребтова регресія та ласо-регресія .
Регресія хребта прагне мінімізувати наступне:
- RSS + λΣβ j 2
Регресія ласо прагне мінімізувати наступне:
- RSS + λΣ|β j |
В обох рівняннях другий член називається штрафом за вилучення .
Коли λ = 0, цей штрафний термін не має ефекту, і хребтова регресія та регресія ласо дають ті самі оцінки коефіцієнта, що й найменші квадрати.
Однак, коли λ наближається до нескінченності, штраф за скорочення стає більш впливовим, і прогнозні змінні, які не можна імпортувати в модель, зменшуються до нуля.
За допомогою регресії Ласо деякі коефіцієнти можуть стати повністю нульовими , коли λ стає достатньо великим.
Переваги та недоліки регресії Ridge & Lasso
Перевага регресії Ріджа та Ласо перед регресією найменших квадратів полягає в компромісі зміщення та дисперсії .
Пам’ятайте, що середня квадратична помилка (MSE) – це показник, який ми можемо використовувати для вимірювання точності даної моделі, і він обчислюється таким чином:
MSE = Var( f̂( x 0 )) + [Зміщення( f̂( x 0 ))] 2 + Var(ε)
MSE = дисперсія + зсув 2 + незнижувана помилка
Основна ідея хребтової регресії та ласо-регресії полягає в тому, щоб ввести невелике зміщення, щоб дисперсію можна було значно зменшити, що призводить до нижчого загального середнього квадратичного значення.
Щоб проілюструвати це, розглянемо наступний графік:

Зверніть увагу, що зі збільшенням λ дисперсія значно зменшується з дуже невеликим збільшенням зміщення. Однак після певної точки дисперсія зменшується менш швидко і зменшення коефіцієнтів призводить до їх значного недооцінювання, що призводить до різкого збільшення зміщення.
З графіка ми бачимо, що MSE тесту є найнижчим, коли ми вибираємо значення для λ, яке забезпечує оптимальний компроміс між упередженням і дисперсією.
Коли λ = 0, штрафний термін у ласо-регресії не має ефекту, тому дає ті самі оцінки коефіцієнта, що й метод найменших квадратів. Однак, збільшивши λ до певної точки, ми можемо зменшити загальну MSE тесту.
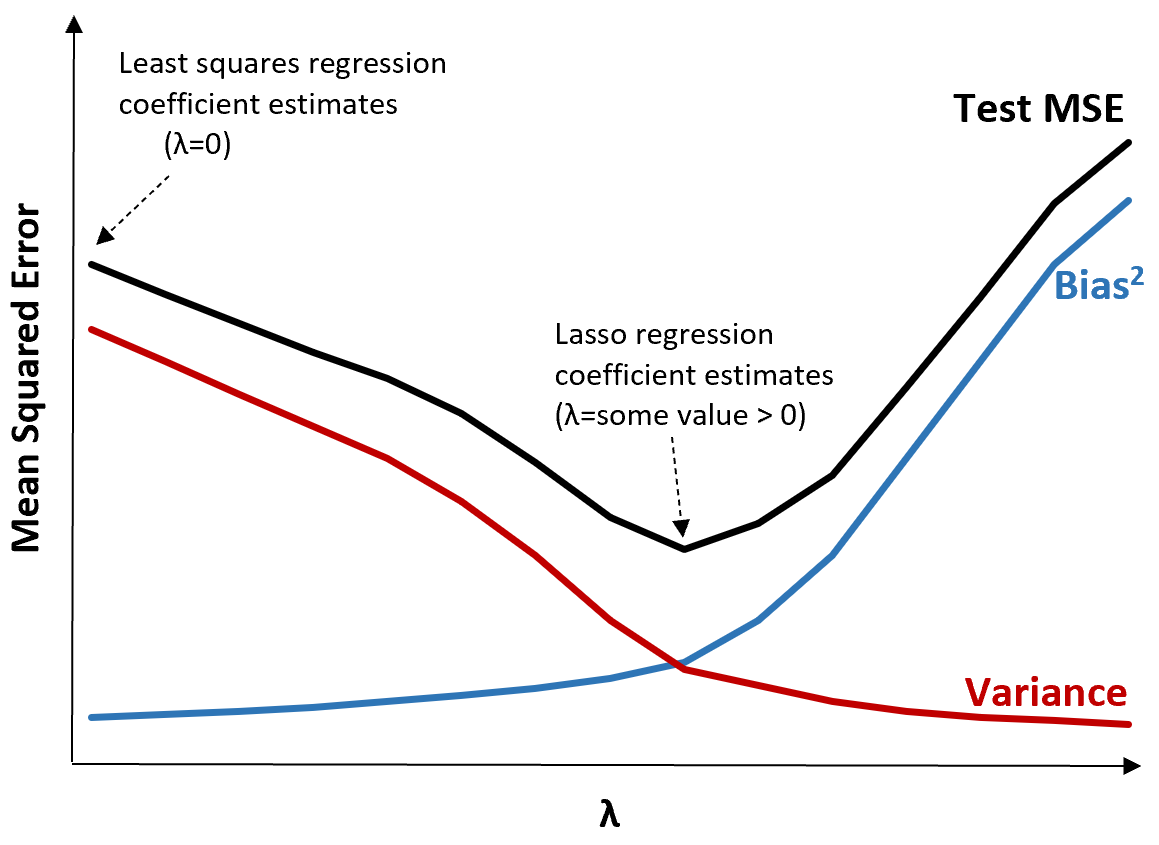
Це означає, що підгонка моделі за допомогою регресії хребта та ласо потенційно може призвести до менших помилок тестування, ніж підгонка моделі за допомогою регресії найменших квадратів.
Недоліком регресії Ріджа та Ласо є те, що стає важко інтерпретувати коефіцієнти в кінцевій моделі, оскільки вони зменшуються до нуля.
Таким чином, регресію Ріджа та Ласо слід використовувати, коли ви хочете оптимізувати здатність передбачити, а не робити висновки.
Хребет vs. Регресія ласо: коли використовувати кожен варіант
Регресія Лассо та гребенева регресія відомі як методи регуляризації , оскільки вони обидва намагаються мінімізувати залишкову суму квадратів (RSS), а також певний термін штрафу.
Іншими словами, вони обмежують або регуляризують оцінки коефіцієнтів моделі.
У зв’язку з цим виникає питання: що краще – регресія хребта чи ласо?
У випадках, коли лише невелика кількість змінних предиктора є значущою, ласо-регресія, як правило, працює краще, оскільки вона здатна повністю звести незначущі змінні до нуля та видалити їх із моделі.
Однак, коли багато змінних предикторів є значущими в моделі, а їхні коефіцієнти приблизно рівні, гребенева регресія, як правило, працює краще, оскільки вона зберігає всі предиктори в моделі.
Щоб визначити, яка модель є найкращою для прогнозування, ми зазвичай виконуємо k-кратну перехресну перевірку та вибираємо модель, яка дає найменшу тестову середньоквадратичну помилку.
Додаткові ресурси
Наступні навчальні посібники містять вступ до регресії Ridge і регресії Lasso:
У наступних посібниках пояснюється, як виконувати обидва типи регресії в R і Python:
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше