Як розрахувати статистику кредитного плеча в r
У статистиці спостереження вважається викидом , якщо його значення для змінної відповіді набагато більше, ніж інші спостереження в наборі даних.
Подібним чином, спостереження вважається високим левериджем , якщо воно має одне або кілька значень для змінних предикторів, які є набагато більш екстремальними порівняно з рештою спостережень у наборі даних.
Одним із перших кроків у будь-якому типі аналізу є більш уважний розгляд спостережень, які мають високий важіль, оскільки вони можуть мати великий вплив на результати даної моделі.
Цей підручник демонструє покроковий приклад того, як обчислити та візуалізувати кредитне плече для кожного спостереження в моделі в R.
Крок 1: Створіть регресійну модель
Спочатку ми створимо модель множинної лінійної регресії, використовуючи набір даних mtcars , вбудований у R:
#load the dataset data(mtcars) #fit a regression model model <- lm(mpg~disp+hp, data=mtcars) #view model summary summary(model) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 30.735904 1.331566 23.083 < 2nd-16 *** available -0.030346 0.007405 -4.098 0.000306 *** hp -0.024840 0.013385 -1.856 0.073679 . --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.127 on 29 degrees of freedom Multiple R-squared: 0.7482, Adjusted R-squared: 0.7309 F-statistic: 43.09 on 2 and 29 DF, p-value: 2.062e-09
Крок 2: Розрахуйте кредитне плече для кожного спостереження
Далі ми використаємо функцію hatvalues() , щоб обчислити кредитне плече для кожного спостереження в моделі:
#calculate leverage for each observation in the model hats <- as . data . frame (hatvalues(model)) #display leverage stats for each observation hats hatvalues(model) Mazda RX4 0.04235795 Mazda RX4 Wag 0.04235795 Datsun 710 0.06287776 Hornet 4 Drive 0.07614472 Hornet Sportabout 0.08097817 Valiant 0.05945972 Duster 360 0.09828955 Merc 240D 0.08816960 Merc 230 0.05102253 Merc 280 0.03990060 Merc 280C 0.03990060 Merc 450SE 0.03890159 Merc 450SL 0.03890159 Merc 450SLC 0.03890159 Cadillac Fleetwood 0.19443875 Lincoln Continental 0.16042361 Chrysler Imperial 0.12447530 Fiat 128 0.08346304 Honda Civic 0.09493784 Toyota Corolla 0.08732818 Toyota Corona 0.05697867 Dodge Challenger 0.06954069 AMC Javelin 0.05767659 Camaro Z28 0.10011654 Pontiac Firebird 0.12979822 Fiat X1-9 0.08334018 Porsche 914-2 0.05785170 Lotus Europa 0.08193899 Ford Pantera L 0.13831817 Ferrari Dino 0.12608583 Maserati Bora 0.49663919 Volvo 142E 0.05848459
Як правило, ми уважніше розглядаємо спостереження зі значенням кредитного плеча більше 2.
Простий спосіб зробити це — відсортувати спостереження за значенням кредитного плеча в порядку спадання:
#sort observations by leverage, descending hats[ order (-hats[' hatvalues(model) ']), ] [1] 0.49663919 0.19443875 0.16042361 0.13831817 0.12979822 0.12608583 [7] 0.12447530 0.10011654 0.09828955 0.09493784 0.08816960 0.08732818 [13] 0.08346304 0.08334018 0.08193899 0.08097817 0.07614472 0.06954069 [19] 0.06287776 0.05945972 0.05848459 0.05785170 0.05767659 0.05697867 [25] 0.05102253 0.04235795 0.04235795 0.03990060 0.03990060 0.03890159 [31] 0.03890159 0.03890159
Ми бачимо, що найвище значення кредитного плеча становить 0,4966 . Оскільки це число не перевищує 2, ми знаємо, що жодне зі спостережень у нашому наборі даних не має високого левериджу.
Крок 3: Візуалізуйте важелі для кожного спостереження
Нарешті, ми можемо створити швидку діаграму для візуалізації важелів для кожного спостереження:
#plot leverage values for each observation plot(hatvalues(model), type = ' h ')
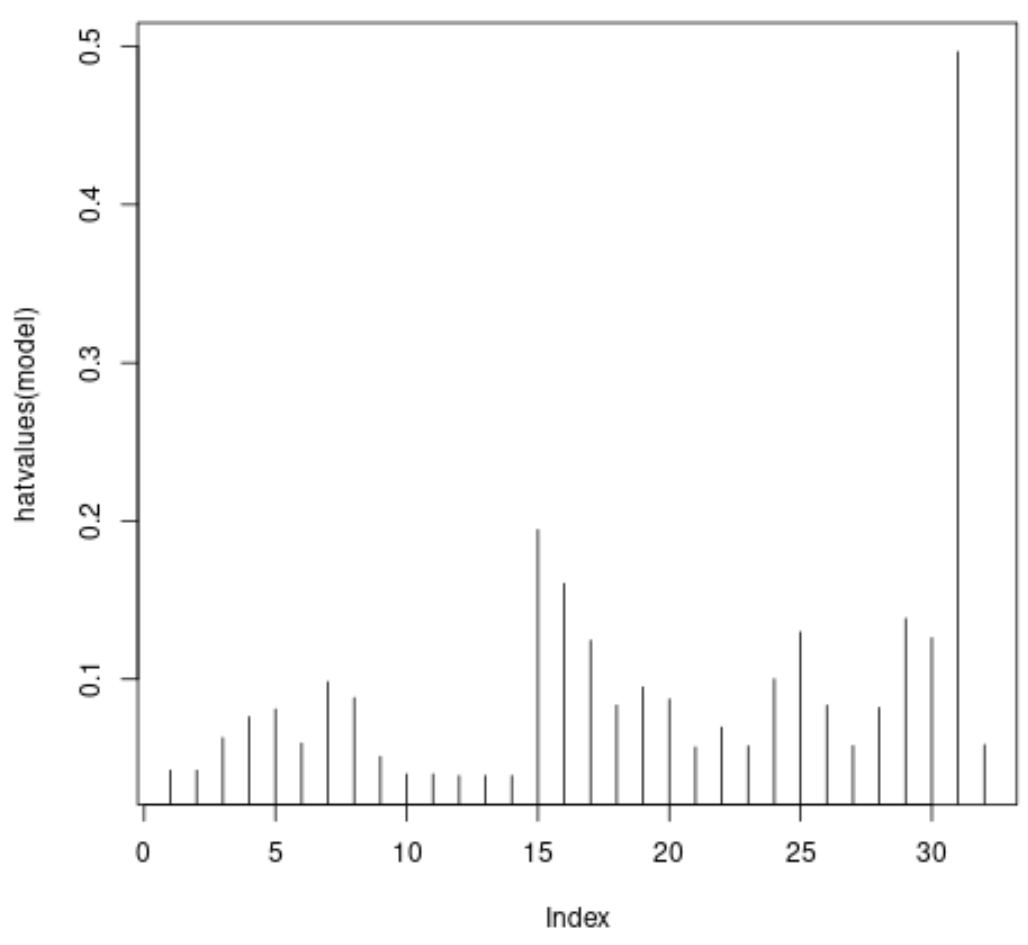
На осі X відображається індекс кожного спостереження в наборі даних, а на y-значенні відображається відповідна статистика кредитного плеча для кожного спостереження.
Додаткові ресурси
Як виконати просту лінійну регресію в R
Як виконати множинну лінійну регресію в R
Як створити ділянку залишків у R
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше