Як побудувати лінію регресії за групою за допомогою ggplot2
Ми можемо використати такий синтаксис, щоб побудувати лінію групової регресії за допомогою пакета візуалізації R ggplot2 :
ggplot(df, aes (x = x_variable, y = y_variable, color = group_variable)) + geom_point() + geom_smooth(method = " lm ", fill = NA )
Цей підручник містить короткий приклад використання цієї функції на практиці.
Приклад: побудова ліній регресії за групою за допомогою ggplot2
Припустімо, що ми маємо наступний набір даних, який показує такі три змінні для 15 різних студентів:
- Кількість вивчених годин
- Отримано оцінку за іспит
- Використана методика дослідження (А, В або С)
#create dataset df <- data.frame(hours=c(1, 2, 3, 3, 4, 1, 2, 2, 3, 4, 1, 2, 3, 4, 4), score=c(84, 86, 85, 87, 94, 74, 76, 75, 77, 79, 65, 67, 69, 72, 80), technique= rep (c(' A ', ' B ', ' C '), each = 5 )) #view dataset df hours technical score 1 1 84 A 2 2 86 A 3 3 85 A 4 3 87 A 5 4 94 A 6 1 74 B 7 2 76 B 8 2 75 B 9 3 77 B 10 4 79 B 11 1 65 C 12 2 67 C 13 3 69 C 14 4 72 C 15 4 80 C
У наведеному нижче коді показано, як побудувати лінію регресії, яка відображає зв’язок між витраченими годинами та результатом іспиту для кожного з трьох методів навчання:
#load ggplot2 library (ggplot2) #create regression lines for all three groups ggplot(df, aes (x = hours, y = score, color = technique)) + geom_point() + geom_smooth(method = " lm ", fill = NA )
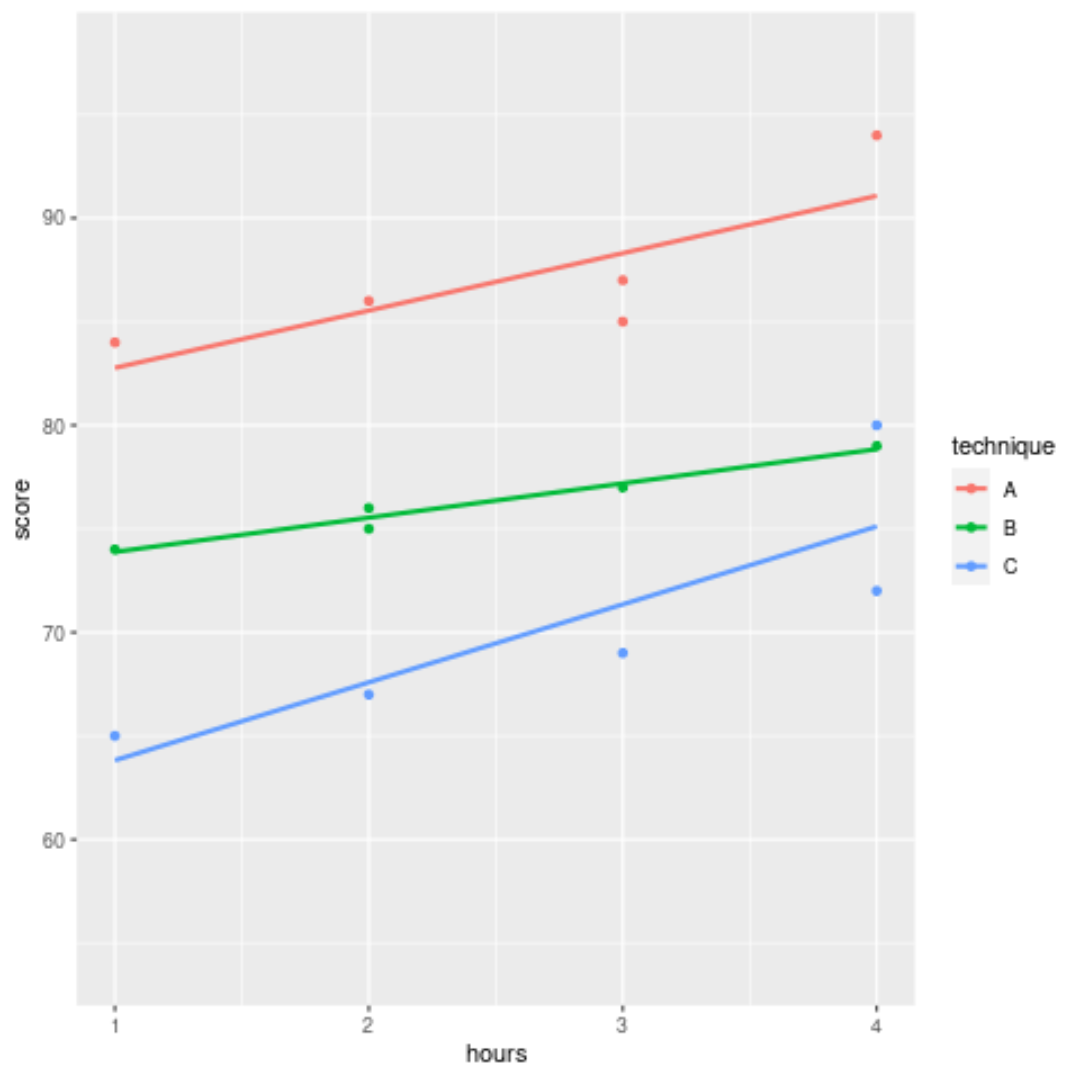
Зверніть увагу, що в geom_smooth() ми використовували method = ‘lm” для визначення лінійного тренду.
Ми також можемо використовувати інші методи згладжування, такі як “glm”, “loess” або “gam”, щоб зафіксувати нелінійні тенденції в даних. Ви можете знайти повну документацію для geom_smooth() тут .
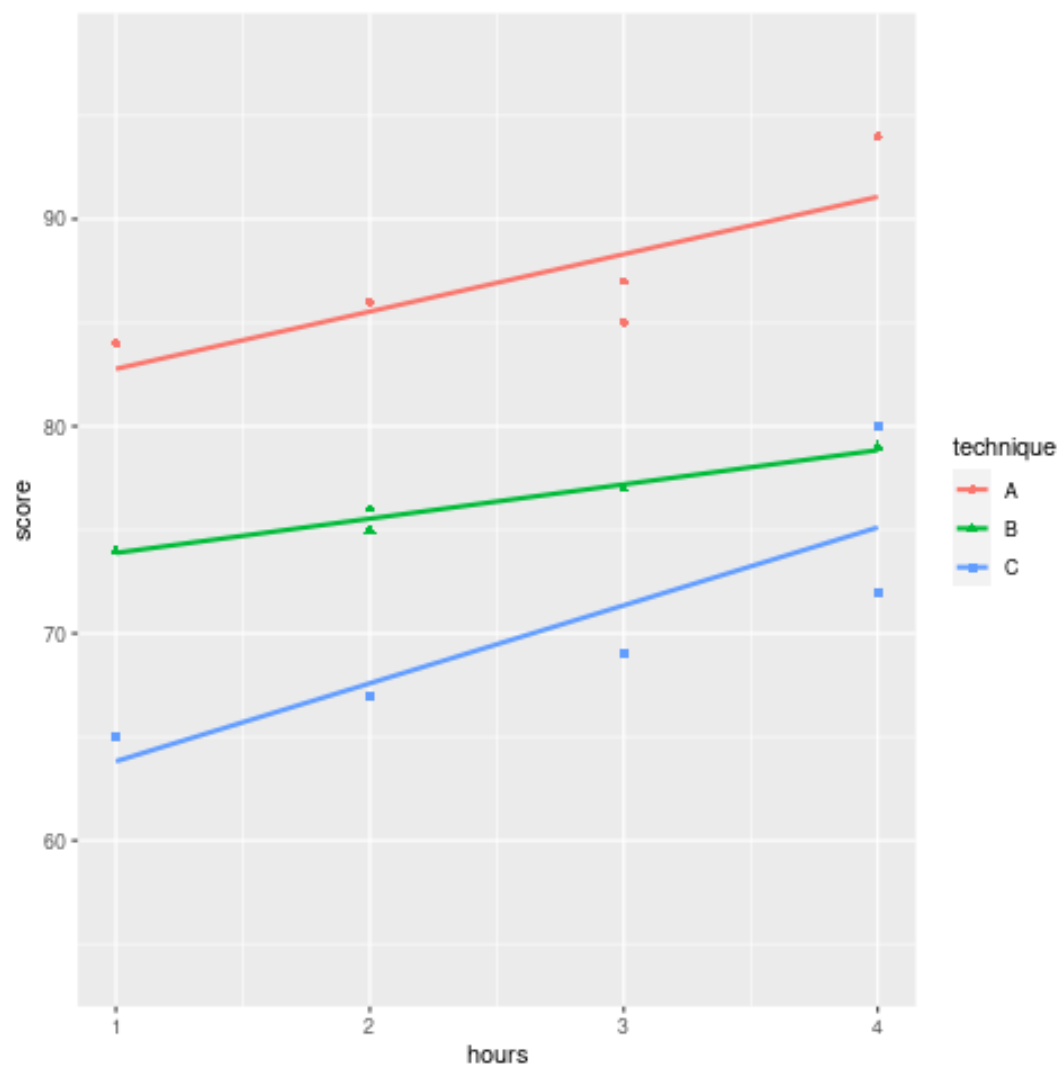
Зауважте, що ми також можемо використовувати різні форми для відображення результатів іспитів для кожної з трьох груп:
ggplot(df, aes (x = hours, y = score, color = technique, shape = technique)) +
geom_point() +
geom_smooth(method = " lm ", fill = NA )
Ви можете знайти більше посібників з ggplot2 тут .
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше