Повний посібник із набору даних iris у r
Набір даних ірису — це інтегрований набір даних у R, який містить вимірювання 4 різних атрибутів (у сантиметрах) для 50 квітів 3 різних видів.
У цьому посібнику пояснюється, як досліджувати та узагальнювати набір даних у R, використовуючи як приклад набір даних райдужної оболонки ока.
За темою: Повний посібник із набору даних mtcars у R
Завантажте набір даних Iris
Оскільки набір даних райдужної оболонки є вбудованим набором даних у R, ми можемо завантажити його за допомогою такої команди:
data(iris)
Ми можемо поглянути на перші шість рядків набору даних за допомогою функції head() :
#view first six rows of iris dataset
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
Узагальніть набір даних Iris
Ми можемо використовувати функцію summary() , щоб швидко підсумувати кожну змінну в наборі даних:
#summarize iris dataset
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4,300 Min. :2,000 Min. :1,000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median: 5,800 Median: 3,000 Median: 4,350 Median: 1,300
Mean:5.843 Mean:3.057 Mean:3.758 Mean:1.199
3rd Qu.:6,400 3rd Qu.:3,300 3rd Qu.:5,100 3rd Qu.:1,800
Max. :7,900 Max. :4,400 Max. :6,900 Max. :2,500
Species
setosa:50
versicolor:50
virginica :50
Для кожної з числових змінних ми можемо побачити таку інформацію:
- Min : мінімальне значення.
- 1st Qu : значення першого квартиля (25-й процентиль).
- Медіана : середнє значення.
- Середнє : Середнє значення.
- 3rd Qu : значення третього квартиля (75-й процентиль).
- Max : максимальне значення.
Для єдиної категоріальної змінної в наборі даних (Species) ми бачимо кількість частот кожного значення:
- setosa : Цей вид присутній 50 разів.
- versicolor : Цей вид зустрічається 50 разів.
- virginica : Цей вид присутній 50 разів.
Ми можемо використовувати функцію dim() , щоб отримати розміри набору даних у термінах кількості рядків і стовпців:
#display rows and columns
dim(iris)
[1] 150 5
Ми бачимо, що набір даних містить 150 рядків і 5 стовпців.
Ми також можемо використовувати функцію names() для відображення імен стовпців кадру даних:
#display column names
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
Візуалізуйте набір даних Iris
Ми також можемо створювати графіки для візуалізації значень набору даних.
Наприклад, ми можемо використовувати функцію hist() для створення гістограми значень певної змінної:
#create histogram of values for sepal length
hist(iris$Sepal.Length,
col=' steelblue ',
main=' Histogram ',
xlab=' Length ',
ylab=' Frequency ')
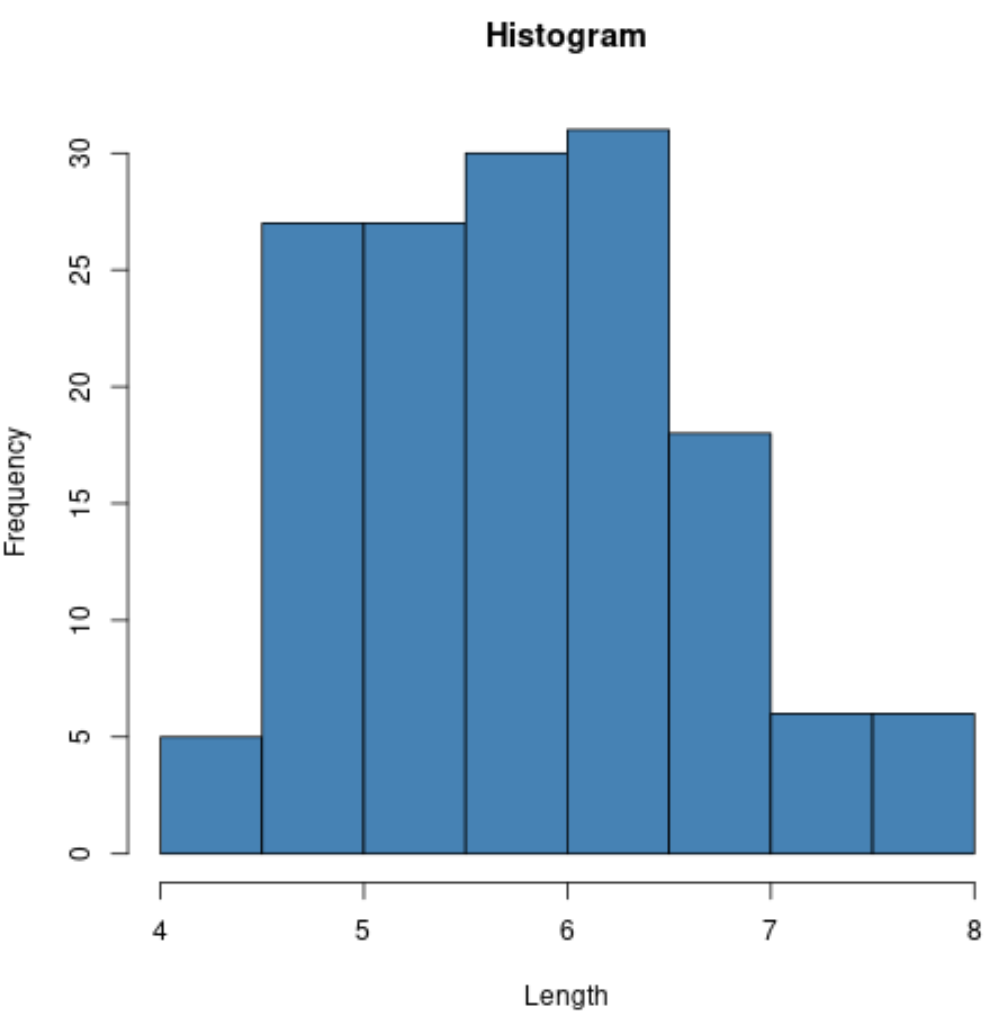
Ми також можемо використовувати функцію plot() для створення діаграми розсіювання будь-якої попарної комбінації змінних:
#create scatterplot of sepal width vs. sepal length
plot(iris$Sepal.Width, iris$Sepal.Length,
col=' steelblue ',
main=' Scatterplot ',
xlab=' Sepal Width ',
ylab=' Sepal Length ',
pch= 19 )
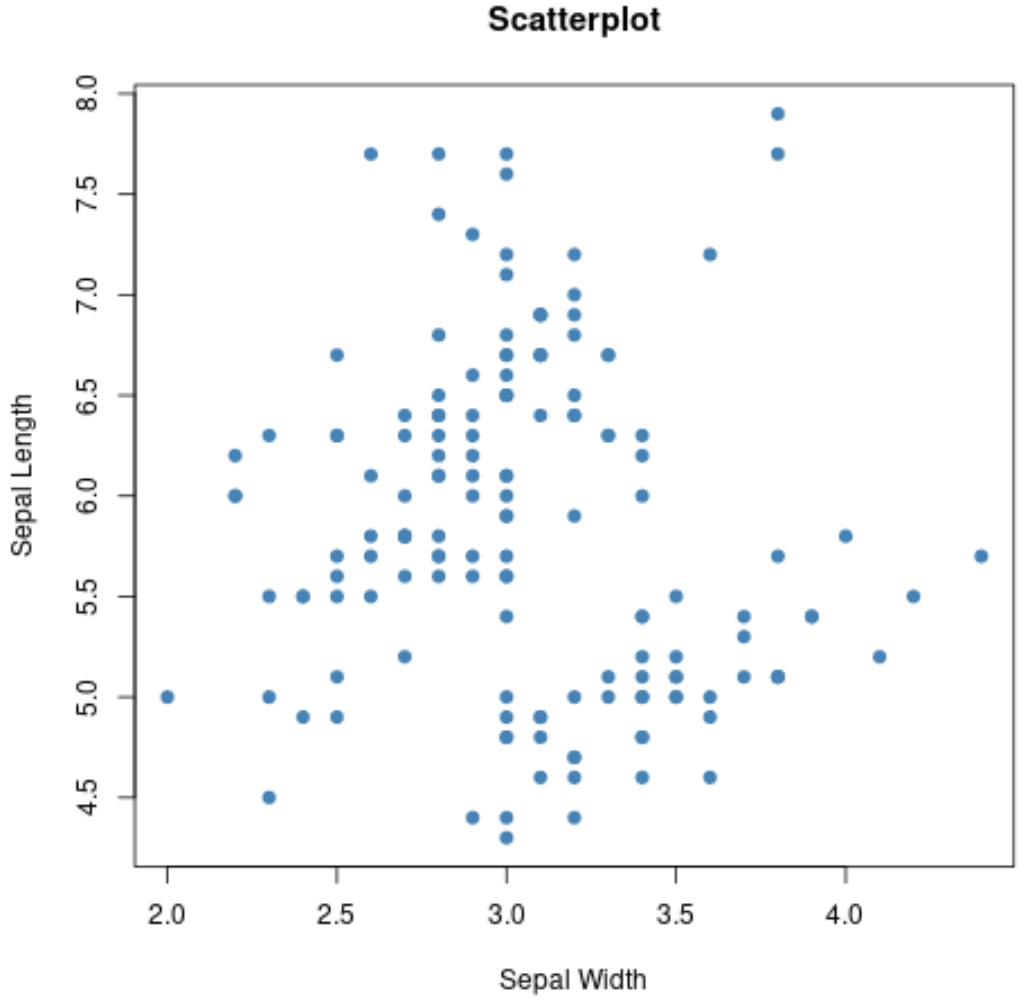
Ми також можемо використовувати функцію boxplot() , щоб створити boxplot для кожної групи:
#create scatterplot of sepal width vs. sepal length
boxplot(Sepal.Length~Species,
data=iris,
main=' Sepal Length by Species ',
xlab=' Species ',
ylab=' Sepal Length ',
col=' steelblue ',
border=' black ')
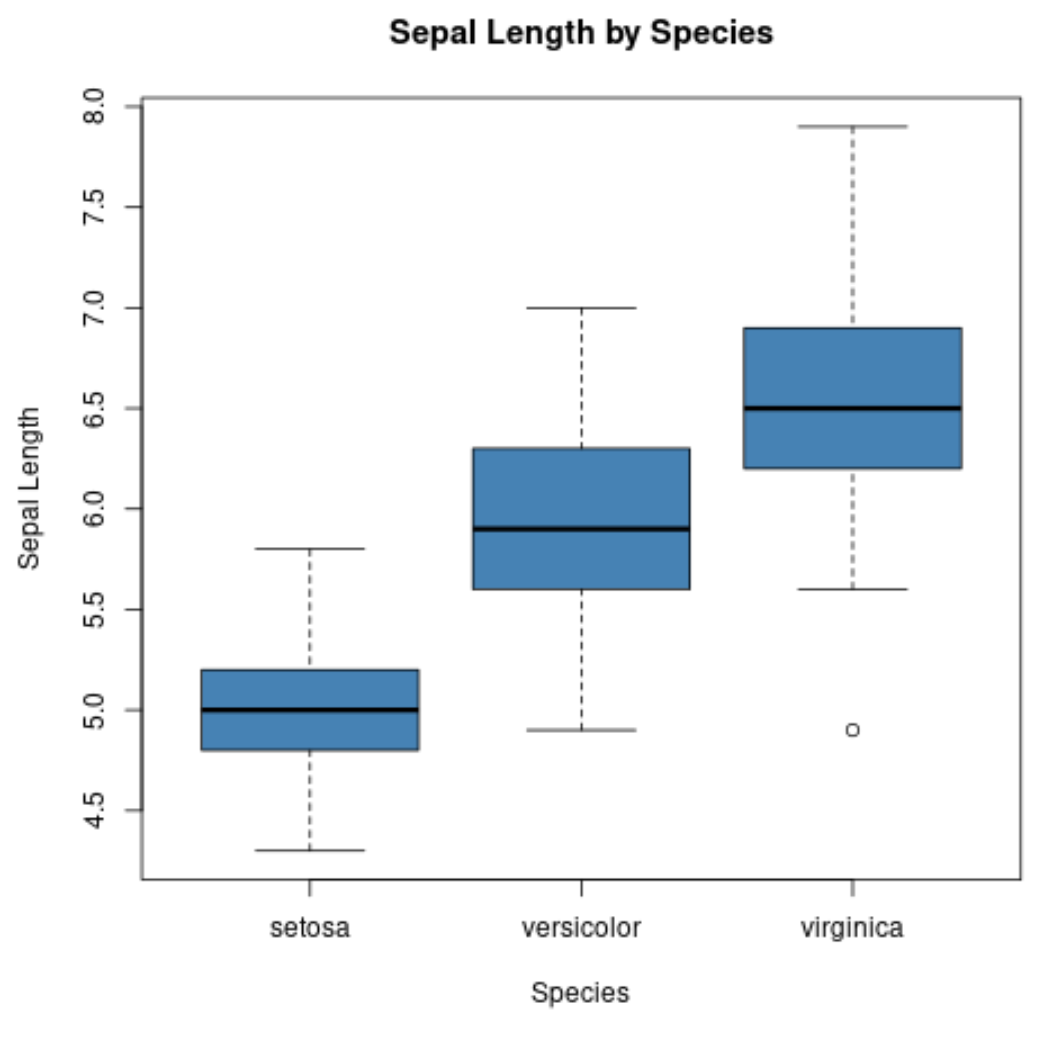
На осі абсцис відображаються три види, а на осі у – розподіл значень довжини чашолистка для кожного виду.
Цей тип графіка дозволяє нам швидко побачити, що довжина чашолистків має тенденцію бути найбільшою для видів virginica та найменшою для видів setosa.
Додаткові ресурси
У наступних посібниках докладніше пояснюється, як узагальнювати набори даних у R:
Найпростіший спосіб створити зведені таблиці в R
Як обчислити підсумок п’яти чисел у R
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше