Як виконати однофакторний аналіз у r (з прикладами)
Термін однофакторний аналіз відноситься до аналізу однієї змінної. Ви можете запам’ятати це, оскільки префікс «uni» означає «один».
Існує три поширених способи виконання однофакторного аналізу змінної:
1. Підсумкова статистика – вимірює центр і розподіл значень.
2. Таблиця частот – описує, як часто з’являються різні значення.
3. Діаграми – використовуються для візуалізації розподілу значень.
Цей підручник містить приклад виконання однофакторного аналізу для наступної змінної:
#create variable with 15 values
x <- c(1, 1, 2, 3.5, 4, 4, 4, 5, 5, 6.5, 7, 7.4, 8, 13, 14.2)
Зведена статистика
Ми можемо використовувати наступний синтаксис для обчислення різних підсумкових статистичних даних для нашої змінної:
#find means mean(x) [1] 5.706667 #find median median(x) [1] 5 #find range max(x) - min(x) [1] 13.2 #find interquartile range (spread of middle 50% of values) IQR(x) [1] 3.45 #find standard deviation sd(x) [1] 3.858287
Таблиця частот
Ми можемо використати такий синтаксис, щоб створити таблицю частот для нашої змінної:
#produce frequency table
table(s)
1 2 3.5 4 5 6.5 7 7.4 8 13 14.2
2 1 1 3 2 1 1 1 1 1 1
Це говорить нам про те, що:
- Значення 1 з’являється двічі
- Значення 2 з’являється 1 раз
- Значення 3,5 з’являється 1 раз
І так далі.
Графіка
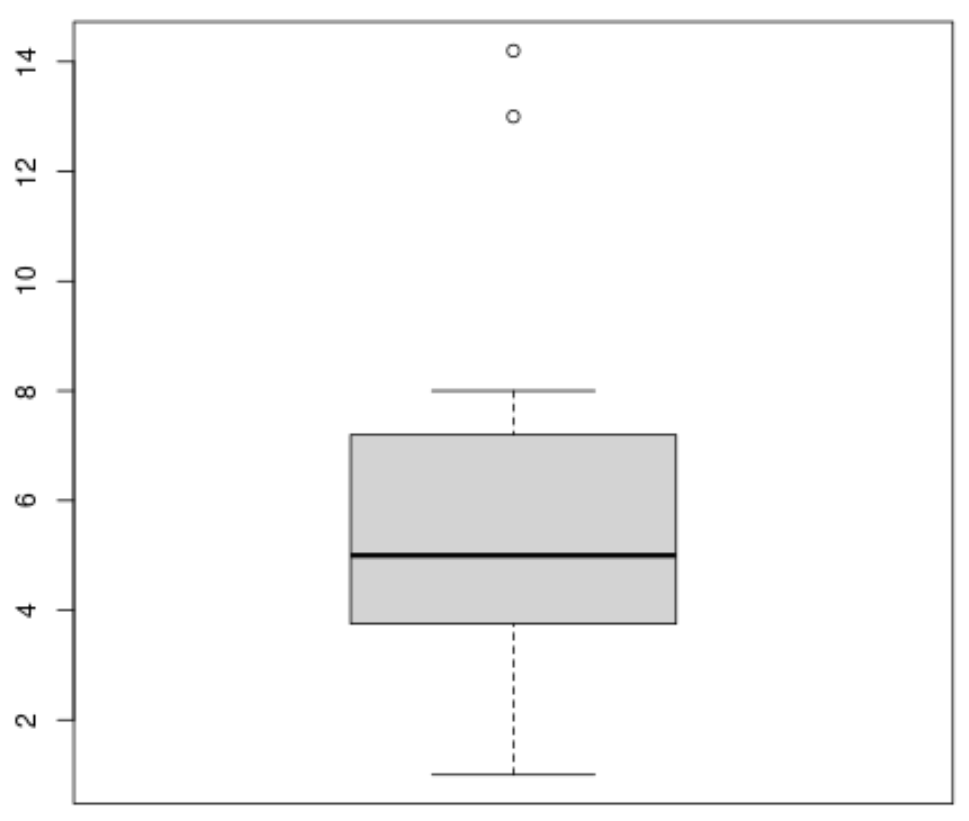
Ми можемо створити коробковий графік , використовуючи такий синтаксис:
#produce boxplot
boxplot(x)
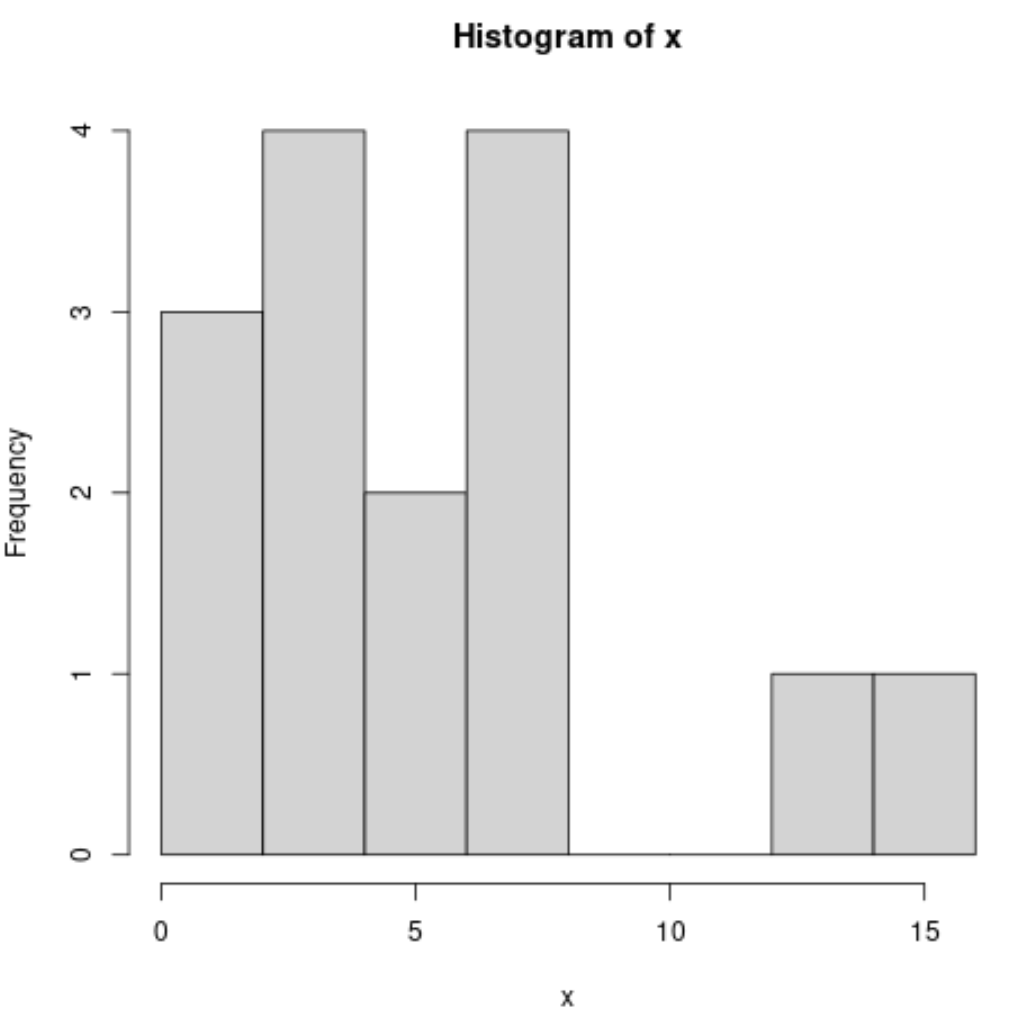
Ми можемо створити гістограму за допомогою такого синтаксису:
#produce histogram
hist(x)
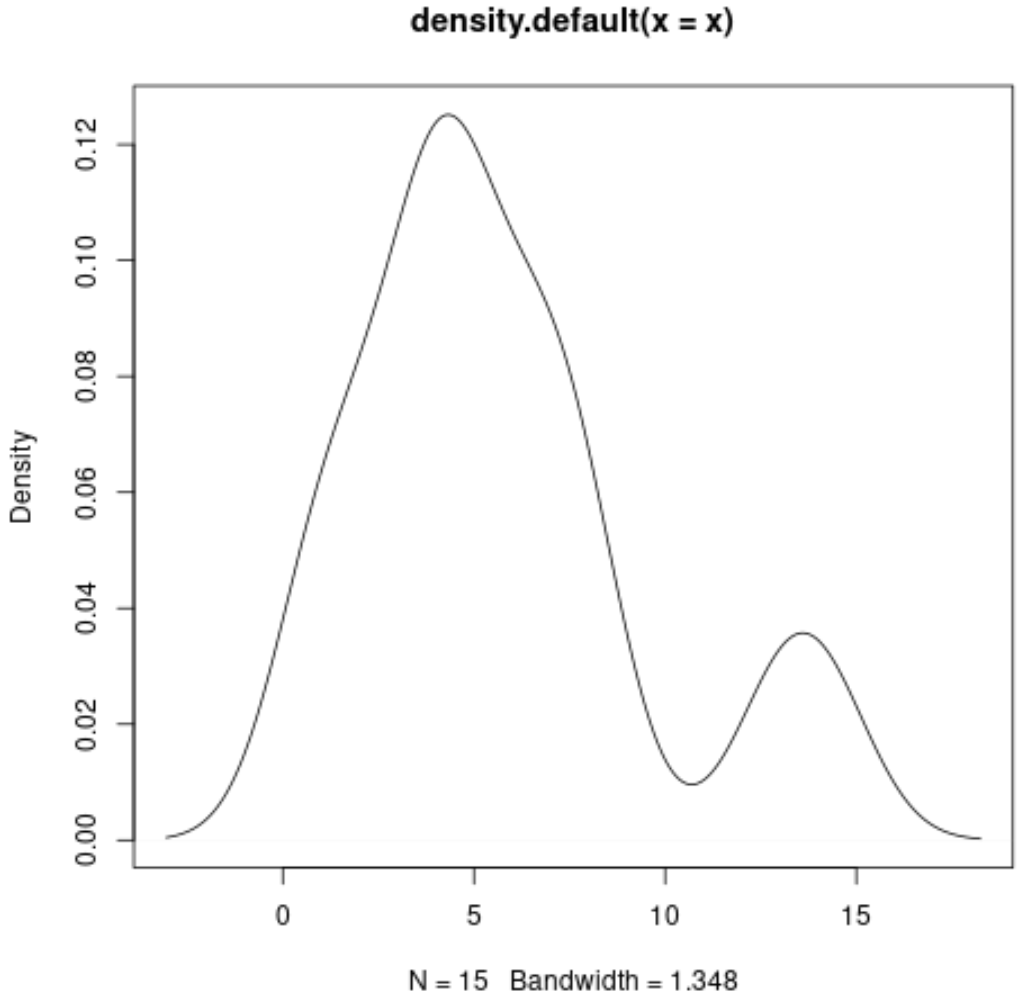
Ми можемо побудувати криву щільності за допомогою наступного синтаксису:
#produce density curve
plot(density(x))
Кожен із цих графіків дає нам унікальний спосіб візуалізації розподілу значень нашої змінної.
Ви можете знайти більше посібників з R на цій сторінці .
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше