Як виконувати однофакторний аналіз у python: із прикладами
Термін однофакторний аналіз відноситься до аналізу однієї змінної. Ви можете запам’ятати це, оскільки префікс «uni» означає «один».
Існує три поширених способи виконання однофакторного аналізу змінної:
1. Підсумкова статистика – вимірює центр і розподіл значень.
2. Таблиця частот – описує, як часто з’являються різні значення.
3. Діаграми – використовуються для візуалізації розподілу значень.
У цьому підручнику наведено приклад того, як виконати однофакторний аналіз за допомогою наступного pandas DataFrame:
import pandas as pd #createDataFrame df = pd. DataFrame ({' points ': [1, 1, 2, 3.5, 4, 4, 4, 5, 5, 6.5, 7, 7.4, 8, 13, 14.2], ' assists ': [5, 7, 7, 9, 12, 9, 9, 4, 6, 8, 8, 9, 3, 2, 6], ' rebounds ': [11, 8, 10, 6, 6, 5, 9, 12, 6, 6, 7, 8, 7, 9, 15]}) #view first five rows of DataFrame df. head () points assists rebounds 0 1.0 5 11 1 1.0 7 8 2 2.0 7 10 3 3.5 9 6 4 4.0 12 6
1. Розрахувати зведену статистику
Ми можемо використовувати наступний синтаксис для обчислення різноманітних підсумкових статистичних даних для змінної «points» у DataFrame:
#calculate mean of 'points' df[' points ']. mean () 5.706666666666667 #calculate median of 'points' df[' points ']. median () 5.0 #calculate standard deviation of 'points' df[' points ']. std () 3.858287308169384
2. Створіть частотну таблицю
Ми можемо використати такий синтаксис, щоб створити таблицю частот для змінної ‘points’:
#create frequency table for 'points' df[' points ']. value_counts () 4.0 3 1.0 2 5.0 2 2.0 1 3.5 1 6.5 1 7.0 1 7.4 1 8.0 1 13.0 1 14.2 1 Name: points, dtype: int64
Це говорить нам про те, що:
- Значення 4 з’являється 3 рази
- Значення 1 з’являється двічі
- Значення 5 з’являється двічі
- Значення 2 з’являється 1 раз
І так далі.
Пов’язане: Як створити таблиці частот у Python
3. Створення діаграм
Ми можемо використати наступний синтаксис, щоб створити коробковий графік для змінної ‘points’:
import matplotlib. pyplot as plt df. boxplot (column=[' points '], grid= False , color=' black ')
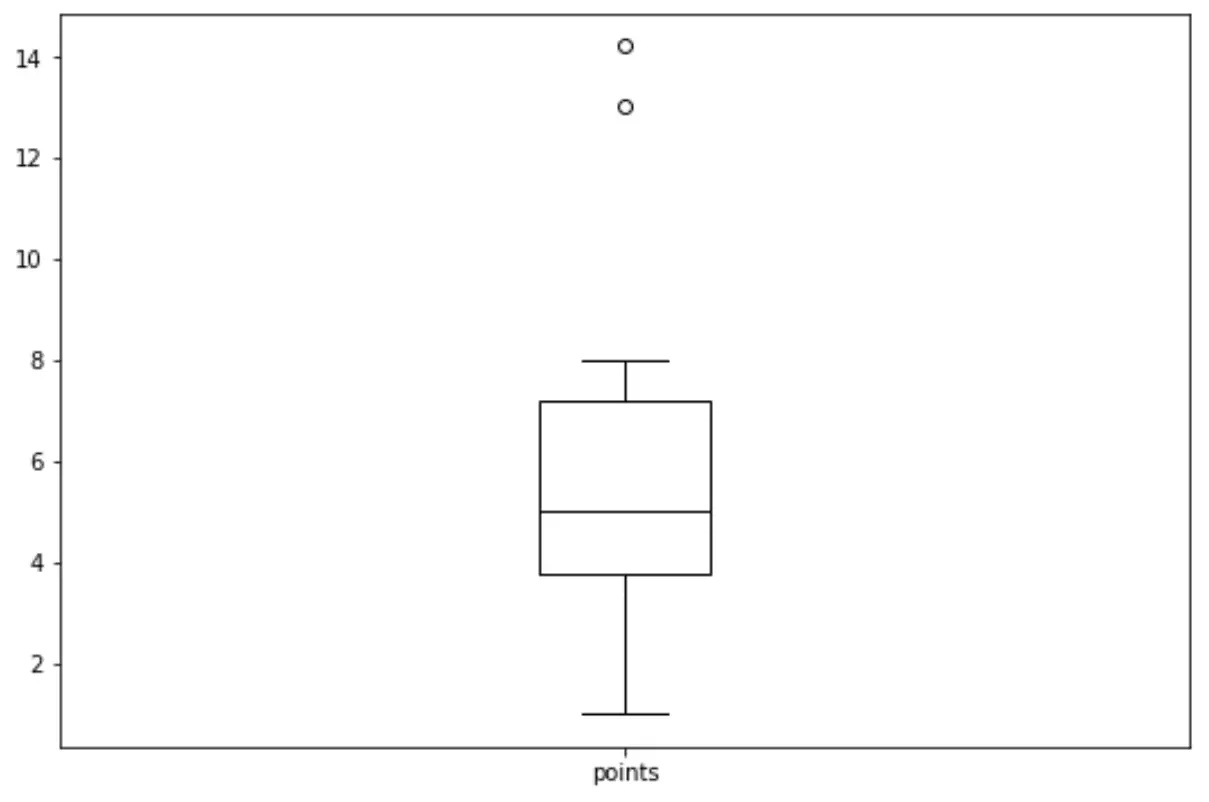
Пов’язане: Як створити Boxplot з Pandas DataFrame
Ми можемо використати такий синтаксис, щоб створити гістограму для змінної ‘points’:
import matplotlib. pyplot as plt df. hist (column=' points ', grid= False , edgecolor=' black ')
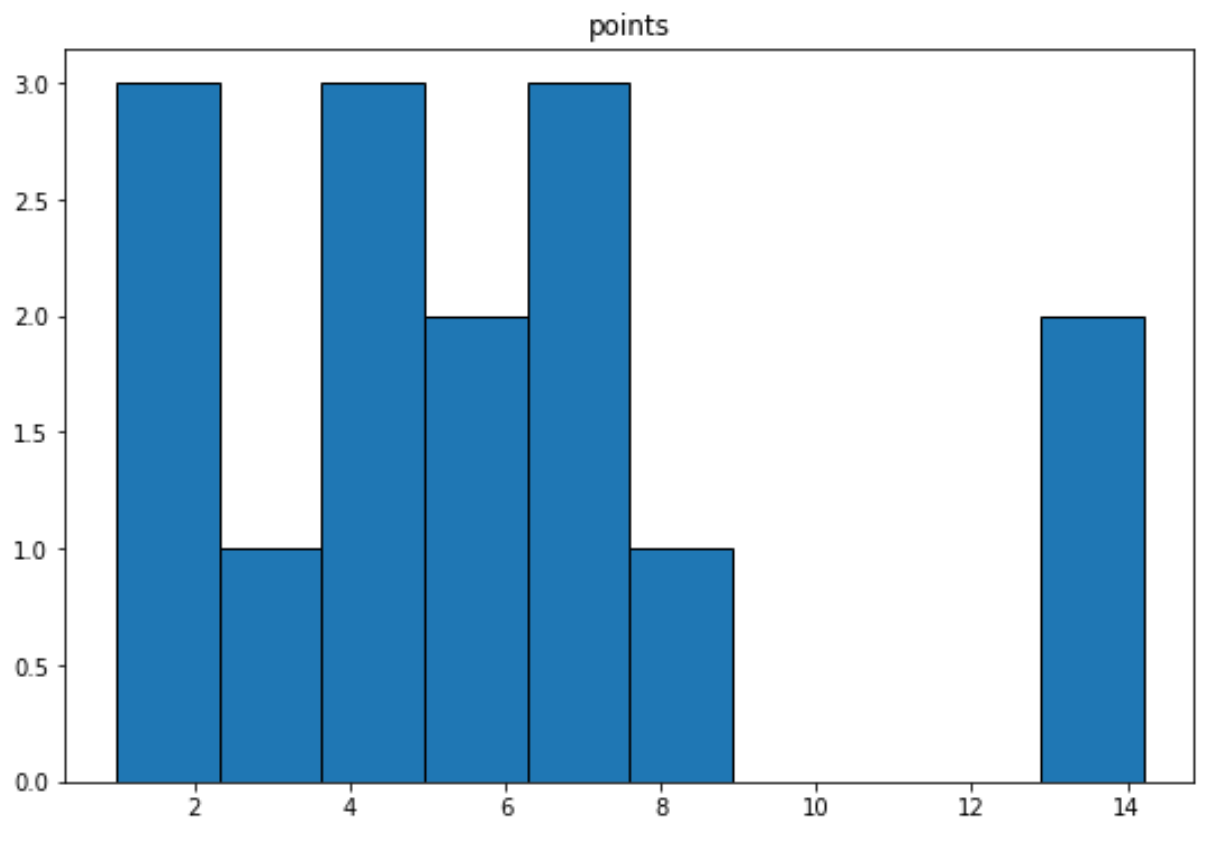
Пов’язане:Як створити гістограму з Pandas DataFrame
Ми можемо використати такий синтаксис, щоб створити криву щільності для змінної «points»:
import seaborn as sns sns. kdeplot (df[' points '])
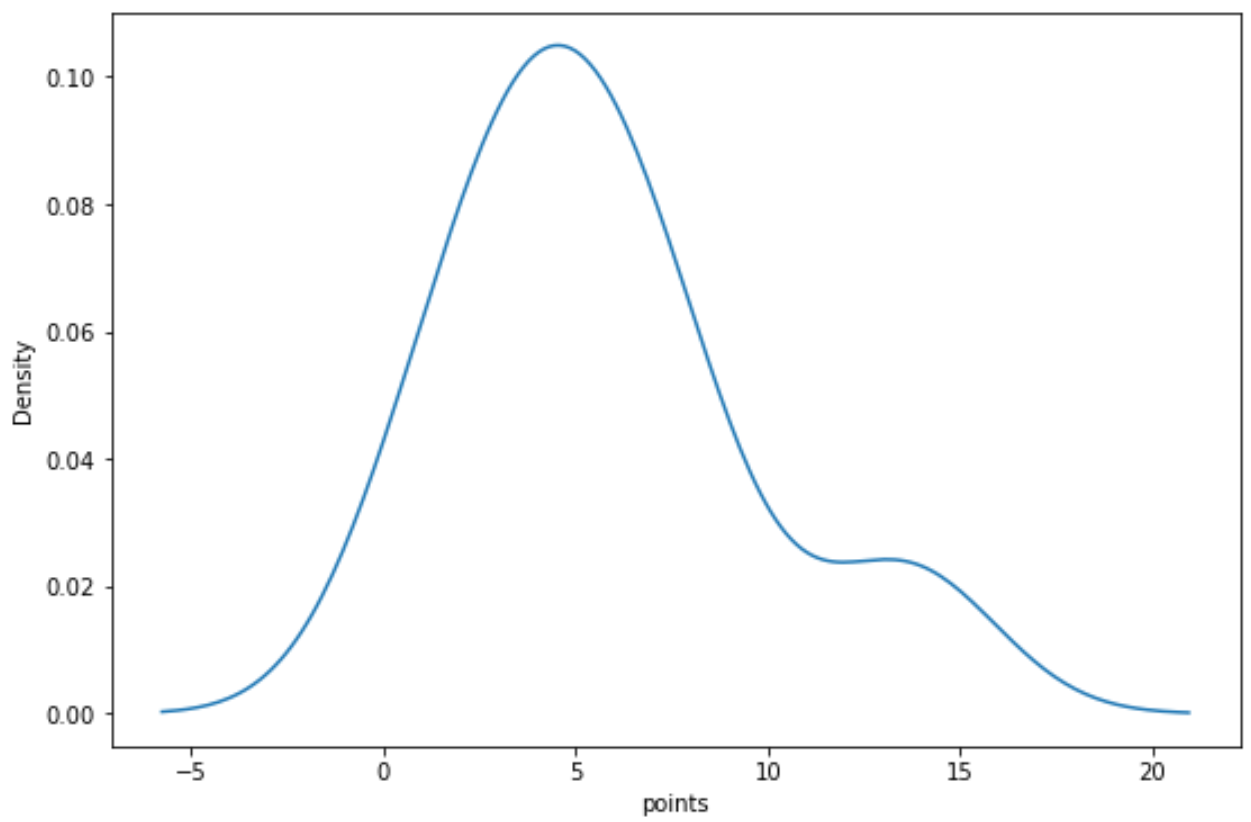
Пов’язане: Як створити графік щільності в Matplotlib
Кожен з цих графіків дає нам унікальний спосіб візуалізації розподілу значень змінної «точок».
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше