Як обчислити описову статистику для змінних у spss
Найкращий спосіб зрозуміти набір даних — обчислити описову статистику для змінних у наборі даних. Існує три поширені форми описової статистики:
1. Зведена статистика – числа, які підсумовують змінну за допомогою одного числа. Приклади включають середнє значення, медіану, стандартне відхилення та діапазон.
2. Таблиці . Таблиці можуть допомогти нам зрозуміти, як розподіляються дані. Прикладом є таблиця частот, яка повідомляє нам, скільки значень даних потрапляє в певні діапазони.
3. Діаграми – вони допомагають нам візуалізувати дані. Прикладом може бути гістограма .
У цьому посібнику пояснюється, як обчислити описову статистику для змінних у SPSS.
Приклад: описова статистика в SPSS
Припустимо, що ми маємо наступний набір даних, що містить чотири змінні для 20 учнів у певному класі:
- Результат іспиту
- Години, витрачені на навчання
- Підготовчі іспити складено
- Поточна оцінка в класі
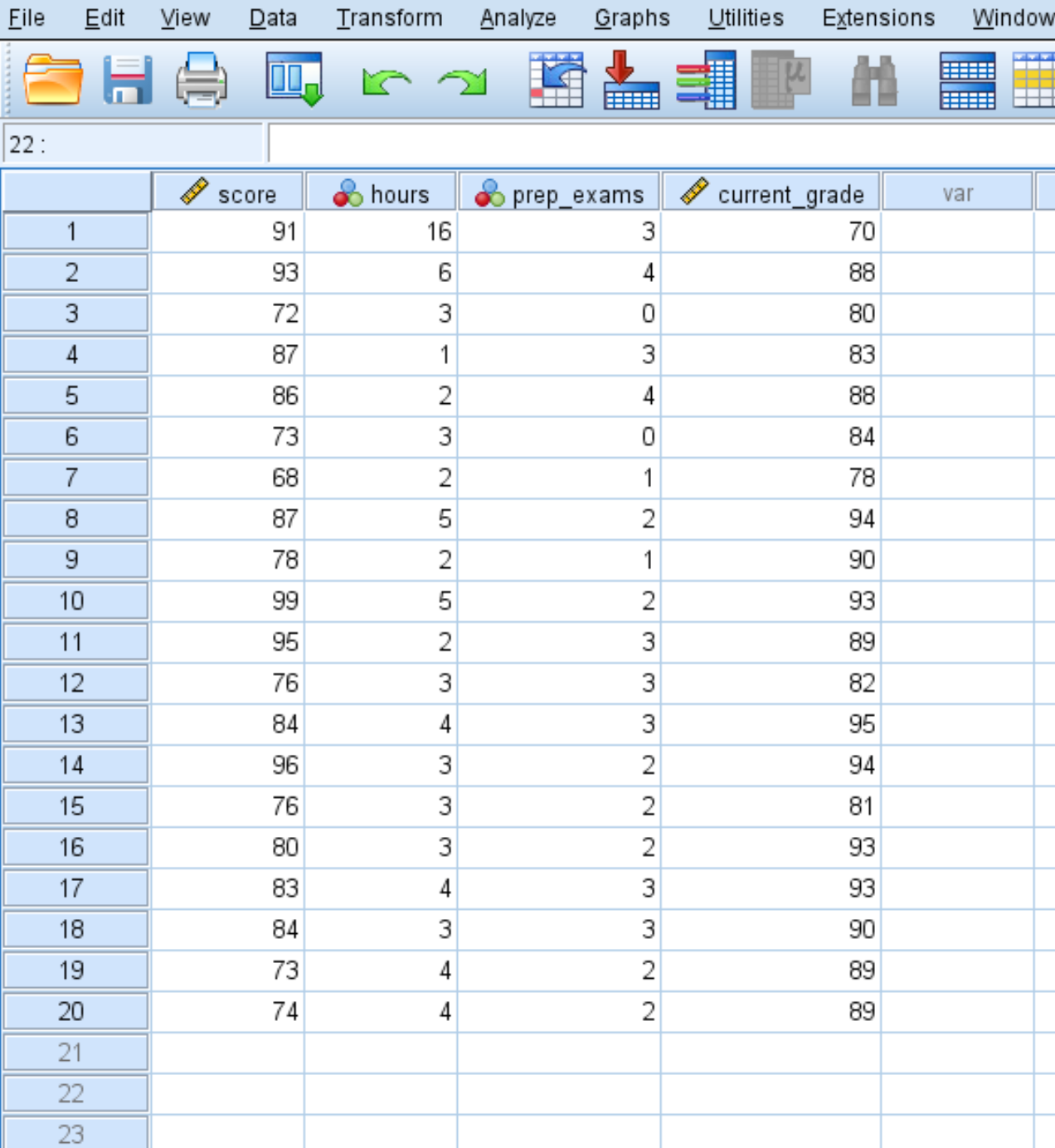
Ось як обчислити описову статистику для кожної з цих чотирьох змінних:
Зведена статистика
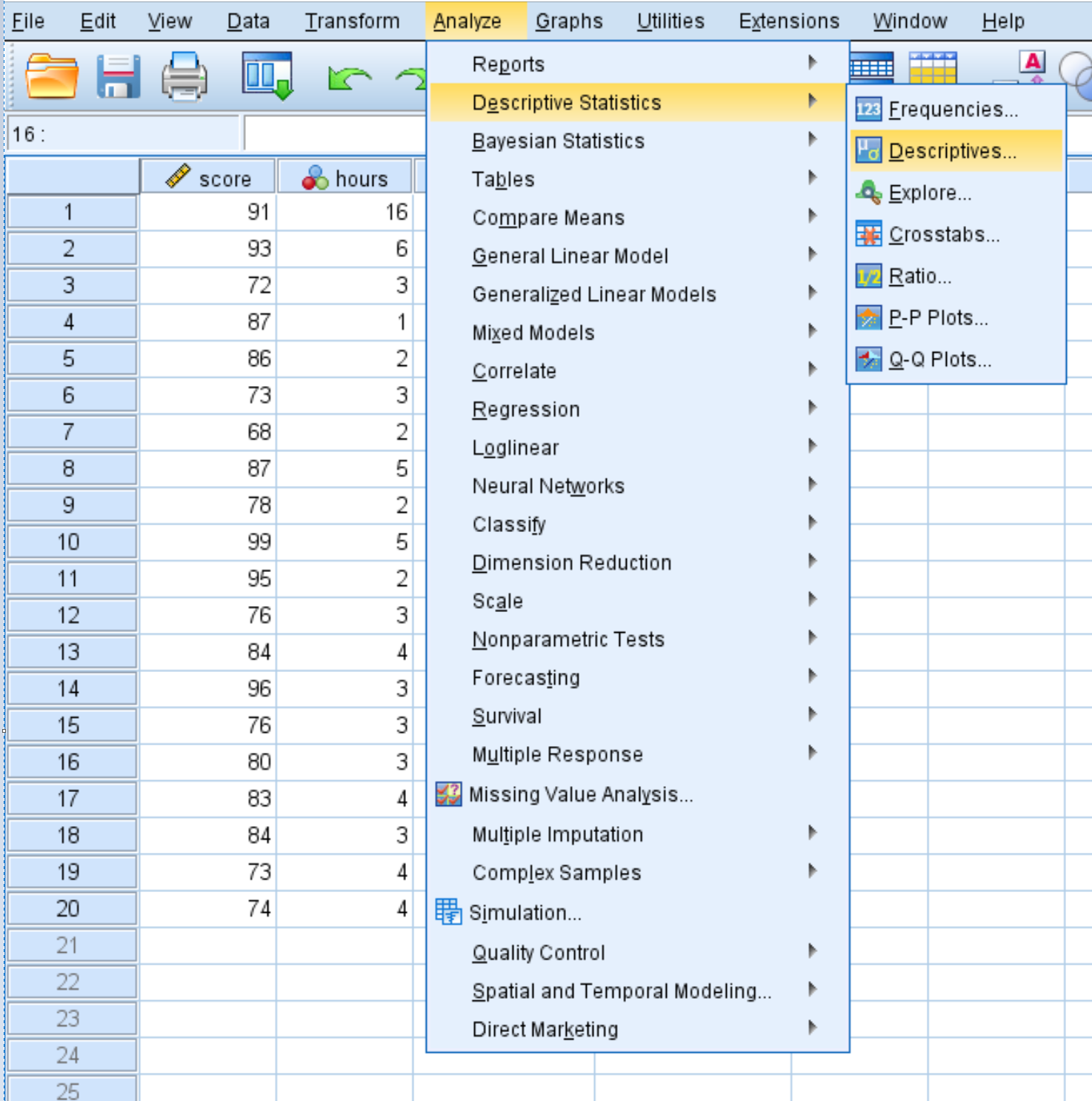
Щоб обчислити підсумкову статистику для кожної змінної, клацніть вкладку «Аналіз» , потім «Описова статистика» , потім «Описова статистика» :
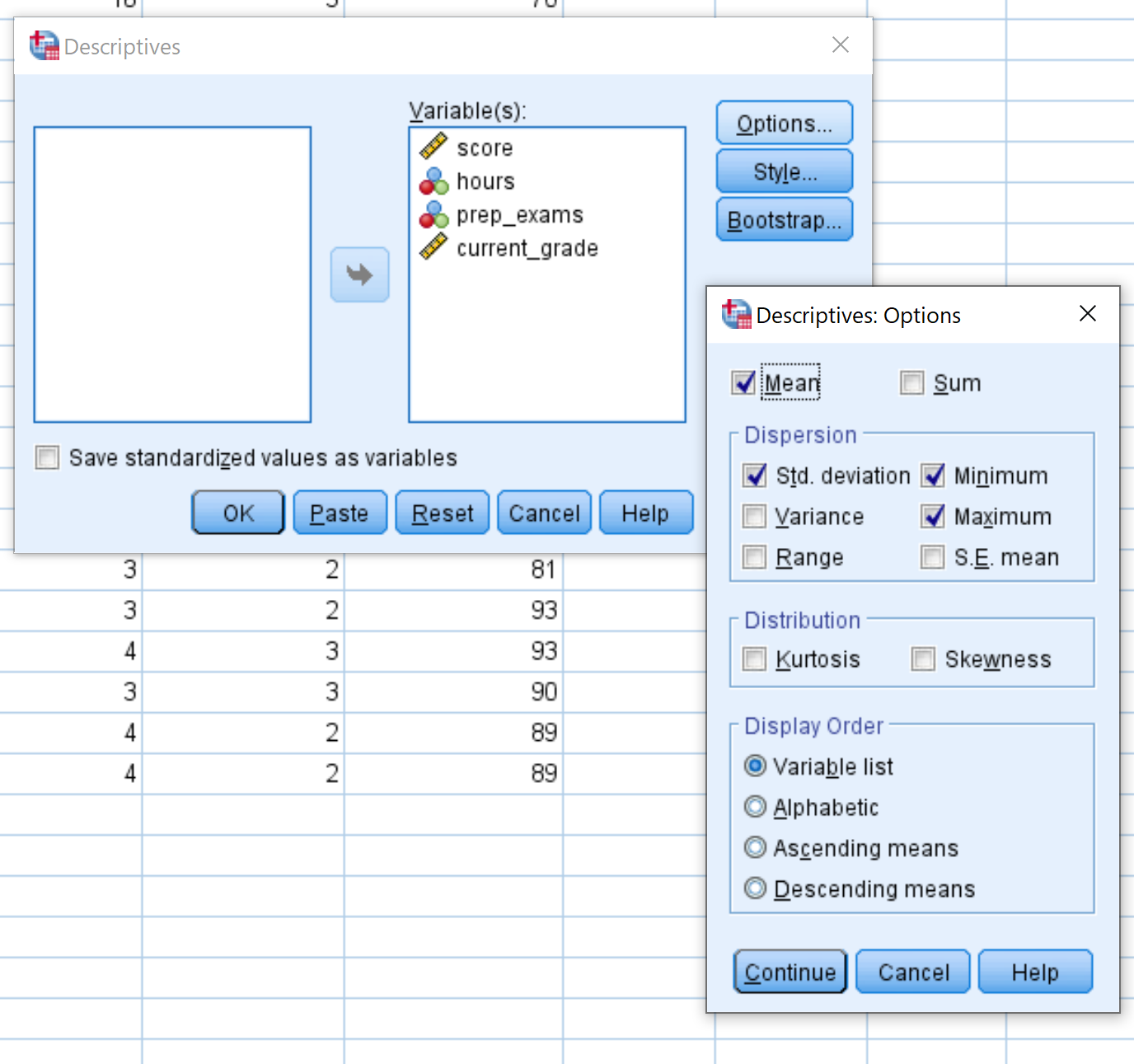
У новому вікні, що з’явиться, перетягніть кожну з чотирьох змінних у область, позначену як Змінна(и). За бажанням ви можете натиснути кнопку «Параметри» та вибрати конкретну описову статистику, яку SPSS має обчислити. Потім натисніть Продовжити . Потім натисніть OK .
Після того, як ви натиснете OK , з’явиться таблиця з описовою статистикою для кожної змінної:
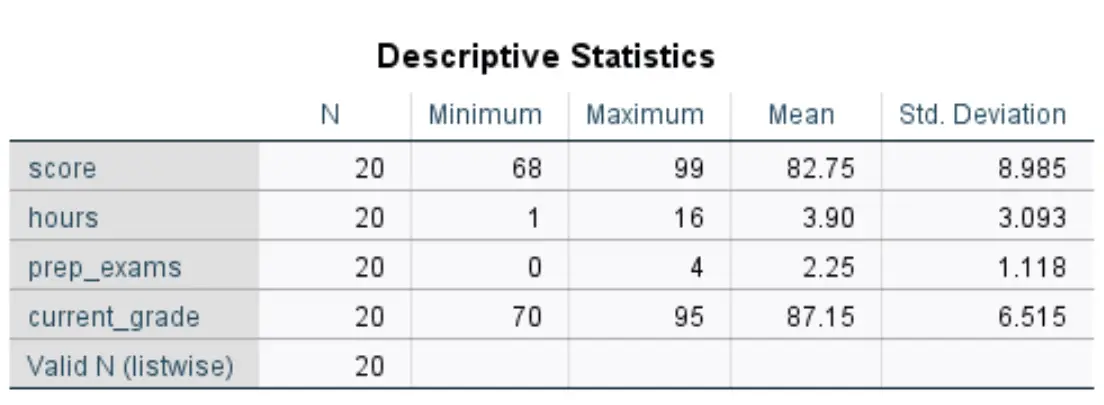
Ось як інтерпретувати числа в цій таблиці для змінної оцінки :
- N: Загальна кількість спостережень. У цьому випадку їх 20.
- Мінімум: Мінімальне значення оцінки за іспит. У цьому випадку це 68.
- Максимум: максимальне значення оцінки за іспит. У цьому випадку це 99.
- Середній: середній бал на іспиті. У цьому випадку це 82,75.
- Стандартний. Відхилення: стандартне відхилення результатів іспиту. У цьому випадку це 8985.
Ця таблиця дозволяє нам швидко зрозуміти діапазон кожної змінної (використовуючи мінімум і максимум), центральне розташування кожної змінної (використовуючи середнє значення) і розподіл значень для кожної змінної (використовуючи стандартне відхилення).
таблиці
Щоб створити таблицю частот для кожної змінної, клацніть вкладку «Аналіз» , потім «Описова статистика» , потім «Частоти» .
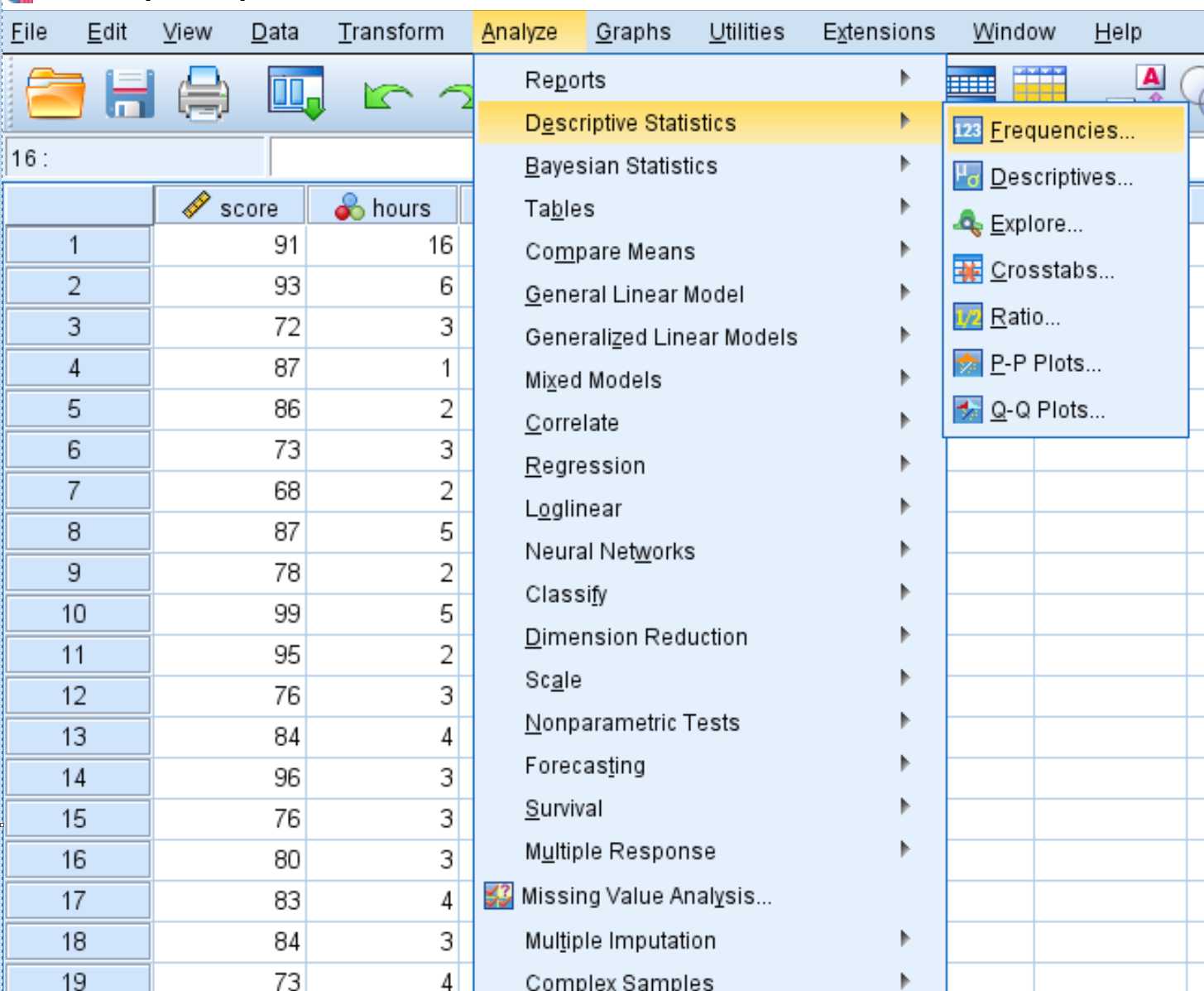
У новому вікні, що з’явиться, перетягніть кожну змінну в поле з написом «Змінні». Потім натисніть OK .
З’явиться частотна таблиця для кожної змінної. Наприклад, ось один для змінних годин :
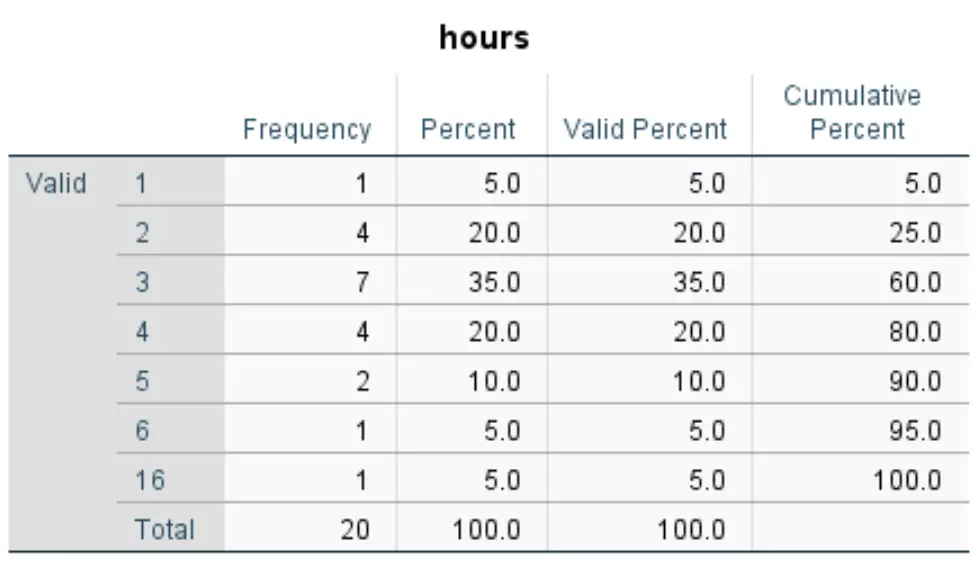
Спосіб інтерпретації таблиці такий:
- Перший стовпець відображає кожне унікальне значення для змінної годин . У цьому випадку унікальними значеннями є 1, 2, 3, 4, 5, 6 і 16.
- Другий стовпець відображає частоту кожного значення. Наприклад, значення 1 з’являється 1 раз, значення 2 — 4 рази і так далі.
- У третьому стовпці відображається відсоток для кожного значення. Наприклад, значення 1 представляє 5% усіх значень у наборі даних. Значення 2 представляє 20% усіх значень у наборі даних і так далі.
- Останній стовпець відображає кумулятивний відсоток. Наприклад, значення 1 і 2 разом представляють 25% від загального набору даних. Значення 1, 2 і 3 представляють загалом 60% набору даних і так далі.
Ця таблиця дає нам гарне уявлення про розподіл значень даних для кожної змінної.
Графіка
Графіки також допомагають нам зрозуміти розподіл значень даних для кожної змінної в наборі даних. Однією з найпопулярніших діаграм для цього є гістограма.
Щоб створити гістограму для певної змінної в наборі даних, клацніть вкладку «Діаграми» , а потім клацніть «Конструктор діаграм» .
У новому вікні, що з’явиться, виберіть Гістограма на панелі «Вибрати з». Потім перетягніть перший параметр гістограми в головне вікно редагування. Потім перетягніть змінну, яка вас цікавить, на вісь х. Для цього прикладу ми використаємо бал . Потім натисніть OK .
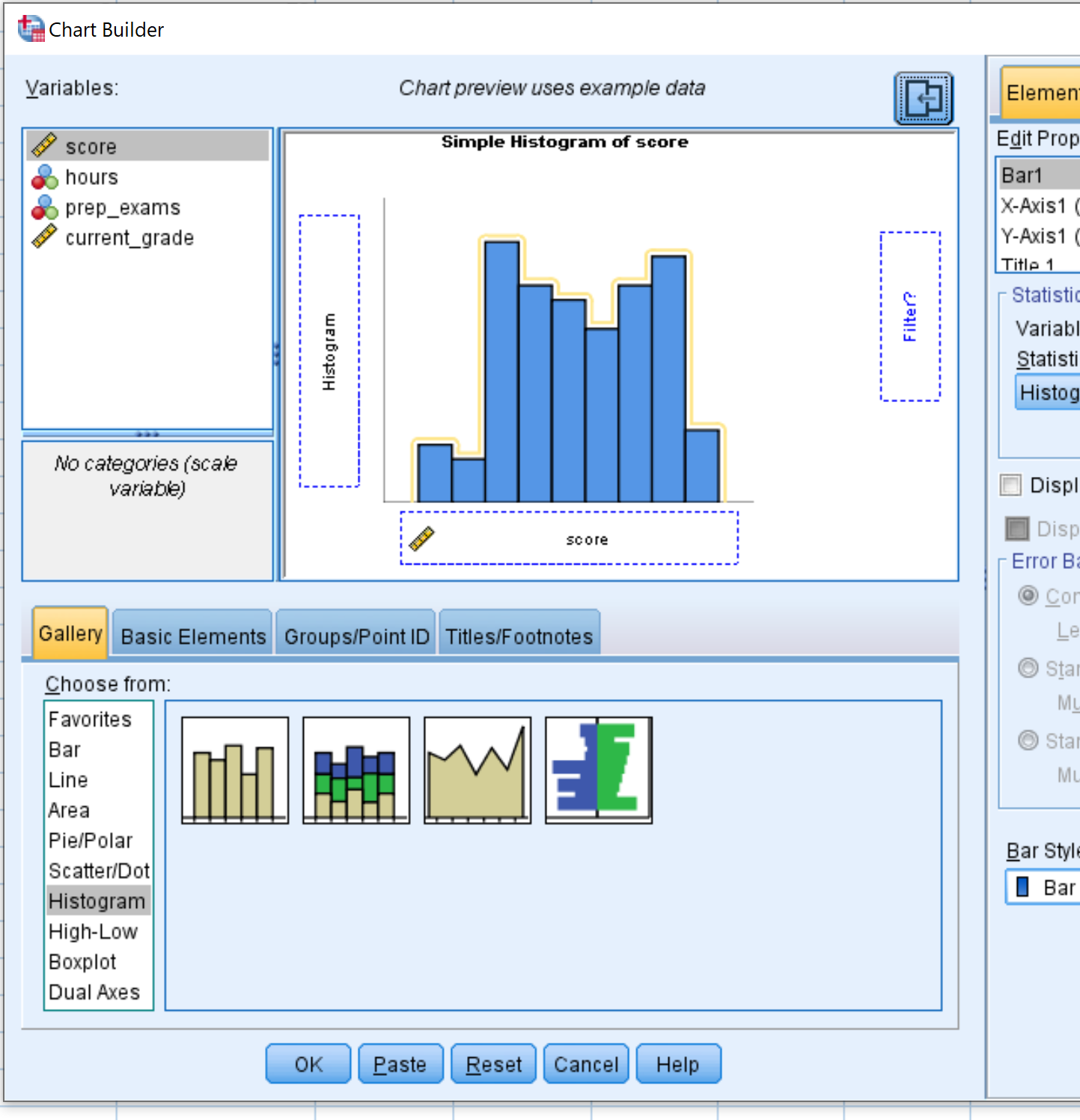
Після того, як ви натиснете OK , з’явиться гістограма, яка відображає розподіл значень для оцінки змінної:
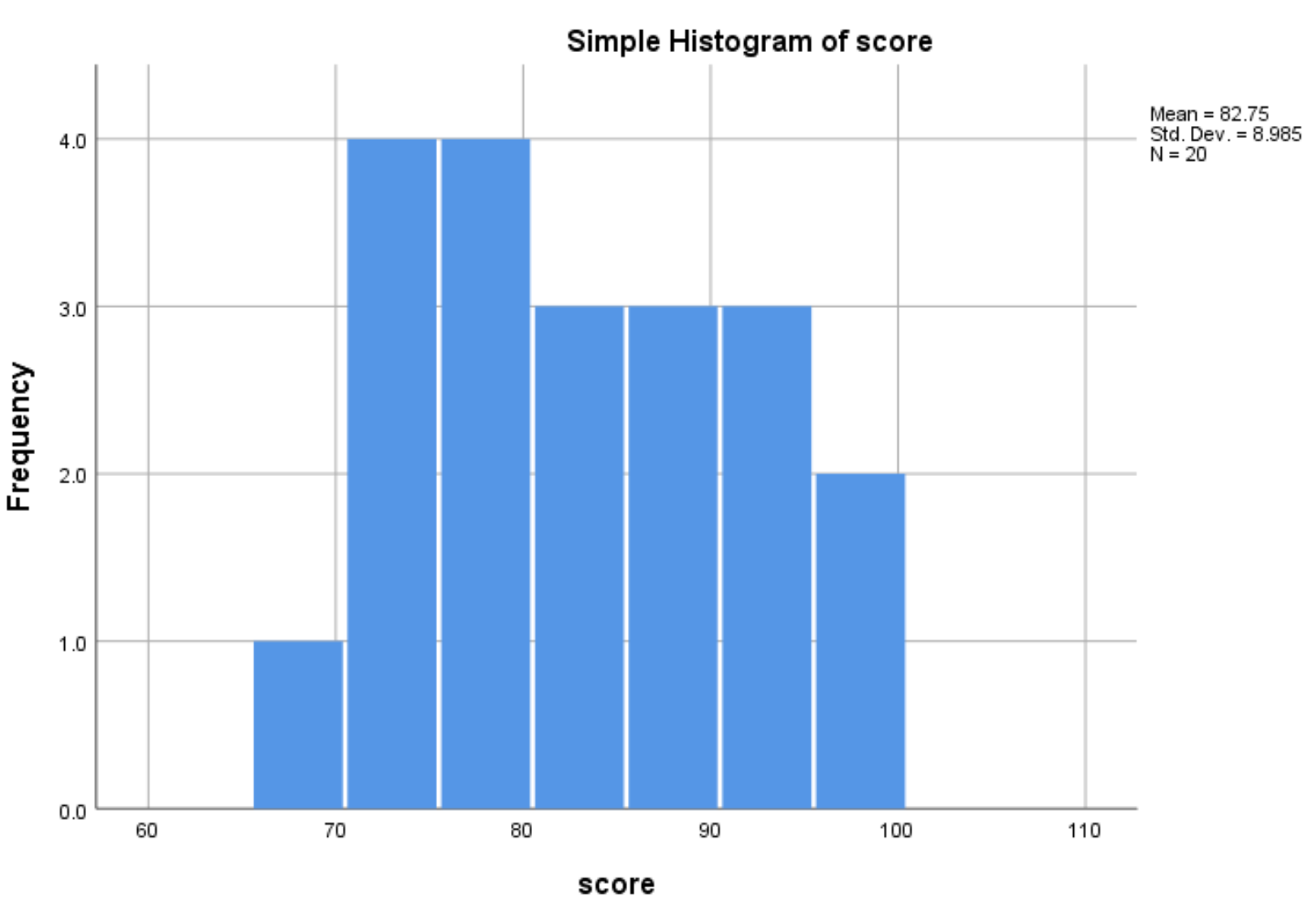
Гістограма показує нам, що діапазон іспитових балів коливається від 65 до 100, причому більшість балів падає від 70 до 90.
Ми також можемо повторити цей процес, щоб створити гістограму для кожної з інших змінних у наборі даних.
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше