Що таке припущення рівної дисперсії в статистиці?
Багато статистичних тестів роблять припущення рівної дисперсії . Якщо це припущення не виконується, результати тесту стають ненадійними.
Найпоширеніші статистичні тести та процедури, які роблять це припущення рівної дисперсії, включають:
1. ANOVA
2. t-тести
3. Лінійна регресія
У цьому посібнику пояснюється припущення, зроблене для кожного тесту, як визначити, чи виконується це припущення, і що робити, якщо воно порушується.
Припущення про рівність дисперсії в ANOVA
Дисперсійний аналіз (дисперсійний аналіз) використовується, щоб визначити, чи існує значна різниця між середніми значеннями трьох або більше незалежних груп.
Ось приклад того, коли ми можемо використовувати ANOVA:
Скажімо, ми набираємо 90 людей для участі в експерименті зі схуднення. Ми випадковим чином призначаємо 30 осіб для використання програм A, B або C протягом місяця.
Щоб перевірити, чи програма впливає на втрату ваги, ми можемо виконати односторонній дисперсійний аналіз .
Дисперсійний аналіз припускає, що кожна з груп має однакову дисперсію. Існує два способи перевірити, чи вірна ця гіпотеза:
1. Створіть коробкові діаграми.
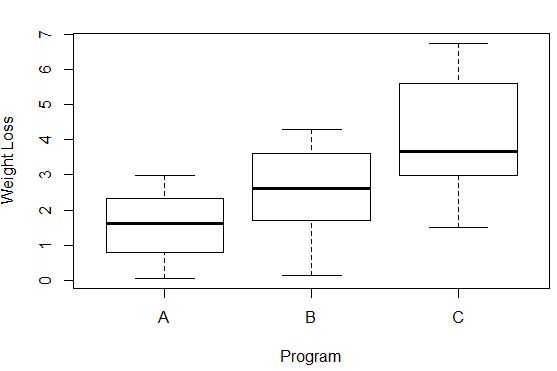
Коробкові діаграми надають візуальний спосіб перевірити припущення про рівність дисперсій.
Розбіжність у втраті ваги в кожній групі можна спостерігати за довжиною кожного бокс-плота. Чим довша коробка, тим вища дисперсія. Наприклад, ми бачимо, що дисперсія трохи вища для учасників програми C порівняно з програмами A та B.
2. Виконайте пробу Бартлетта.
Тест Бартлетта перевіряє нульову гіпотезу про те, що вибірки мають однакові дисперсії, проти альтернативної гіпотези про те, що вибірки не мають рівних дисперсій.
Якщо p-значення тесту нижче певного рівня значущості (наприклад, 0,05), то ми маємо докази того, що не всі зразки мають однакові дисперсії.
Що станеться, якщо припущення рівної дисперсії не виконується?
Загалом дисперсійний аналіз вважається достатньо надійним проти порушень припущення рівних дисперсій, якщо кожна група має однаковий розмір вибірки.
Однак, якщо розміри вибірки не однакові, і це припущення серйозно порушено, ви можете натомість запустити тест Крускала-Уолліса , який є непараметричною версією одностороннього дисперсійного аналізу.
Припущення рівної дисперсії в t-тестах
Двовибірковий t-критерій використовується, щоб перевірити, чи рівні середні дві сукупності чи ні.
Тест передбачає, що дисперсії між двома групами рівні. Існує два способи перевірити, чи вірна ця гіпотеза:
1. Використовуйте емпіричне правило співвідношення.
Як правило, якщо відношення найбільшої дисперсії до найменшої дисперсії менше ніж 4, тоді ми можемо припустити, що дисперсії приблизно однакові, і використовувати двовибірковий t-критерій.
Наприклад, припустимо, що зразок 1 має дисперсію 24,5, а зразок 2 має дисперсію 15,2. Відношення найбільшої дисперсії вибірки до найменшої дисперсії вибірки буде розраховано як: 24,5 / 15,2 = 1,61.
Оскільки це співвідношення менше 4, можна припустити, що відмінності між двома групами приблизно рівні.
2. Виконайте F-тест.
F-тест перевіряє нульову гіпотезу про те, що вибірки мають однакові дисперсії, проти альтернативної гіпотези про те, що вибірки не мають рівних дисперсій.
Якщо p-значення тесту нижче певного рівня значущості (наприклад, 0,05), то ми маємо докази того, що не всі зразки мають однакові дисперсії.
Що станеться, якщо припущення рівної дисперсії не виконується?
Якщо це припущення порушується, ми можемо виконати t-критерій Велча , який є непараметричною версією t-критерію двох вибірок і не передбачає, що дві вибірки мають однакові дисперсії.
Припущення рівної дисперсії в лінійній регресії
Лінійна регресія використовується для кількісного визначення зв’язку між однією або декількома змінними предиктора та змінною відповіді.
Лінійна регресія передбачає, що залишки мають постійну дисперсію на кожному рівні змінної (змінних) предиктора. Це називається гомоскедастичністю . Якщо це не так, залишки страждають від гетероскедастичності , а результати регресійного аналізу стають ненадійними.
Найпоширеніший спосіб визначити, чи виконується це припущення, — створити графік залежності залишків від підігнаних значень. Якщо залишки на цьому графіку випадково розкидані навколо нуля, то, ймовірно, виконується припущення про гомоскедастичність.
Однак, якщо є систематична тенденція в залишках, наприклад форма «конуса» на наступному графіку, то гетероскедастичність є проблемою:
Що станеться, якщо припущення рівної дисперсії не виконується?
Якщо це припущення порушується, найпоширенішим способом вирішення проблеми є перетворення змінної відповіді за допомогою одного з трьох перетворень:
1. Перетворення журналу: перетворення змінної відповіді з y на log(y) .
2. Перетворення квадратного кореня: перетворення змінної відповіді з y на √y .
3. Перетворення кубічного кореня: перетворення змінної відповіді з y на y 1/3 .
Виконуючи ці перетворення, проблема гетероскедастичності взагалі зникає.
Інший спосіб виправлення гетероскедастичності полягає в застосуванні зваженої регресії найменших квадратів . Цей тип регресії призначає вагу кожній точці даних на основі дисперсії її підігнаного значення.
По суті, це дає низькі ваги точкам даних, які мають більшу дисперсію, зменшуючи їхні залишкові квадрати. Якщо використовуються відповідні ваги, це може усунути проблему гетероскедастичності.
Додаткові ресурси
Три гіпотези, сформульовані в ANOVA
Чотири гіпотези, сформульовані в тесті T
Чотири припущення лінійної регресії
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше