Простий вступ до вдосконалення машинного навчання
Більшість керованих алгоритмів машинного навчання засновані на використанні єдиної прогностичної моделі, наприклад лінійної регресії , логістичної регресії , хребтової регресії тощо.
Однак такі методи, як пакетування та випадкові ліси, створюють багато різних моделей на основі повторюваних початкових зразків вихідного набору даних. Прогнози на основі нових даних робляться на основі середнього значення прогнозів, зроблених окремими моделями.
Ці методи, як правило, пропонують покращення точності передбачення порівняно з методами, які використовують лише одну прогностичну модель, оскільки вони використовують такий процес:
- По-перше, побудуйте індивідуальні моделі з високою дисперсією та низьким зміщенням (наприклад, глибоко вирощені дерева рішень ).
- Потім усередніть прогнози, зроблені окремими моделями, щоб зменшити дисперсію.
Інший метод, який, як правило, пропонує ще більше покращення точності прогнозування, відомий як підвищення .
Що таке бустінг?
Підвищення — це метод, який можна використовувати з будь-яким типом моделі, але найчастіше він використовується з деревами рішень.
Ідея посилення проста:
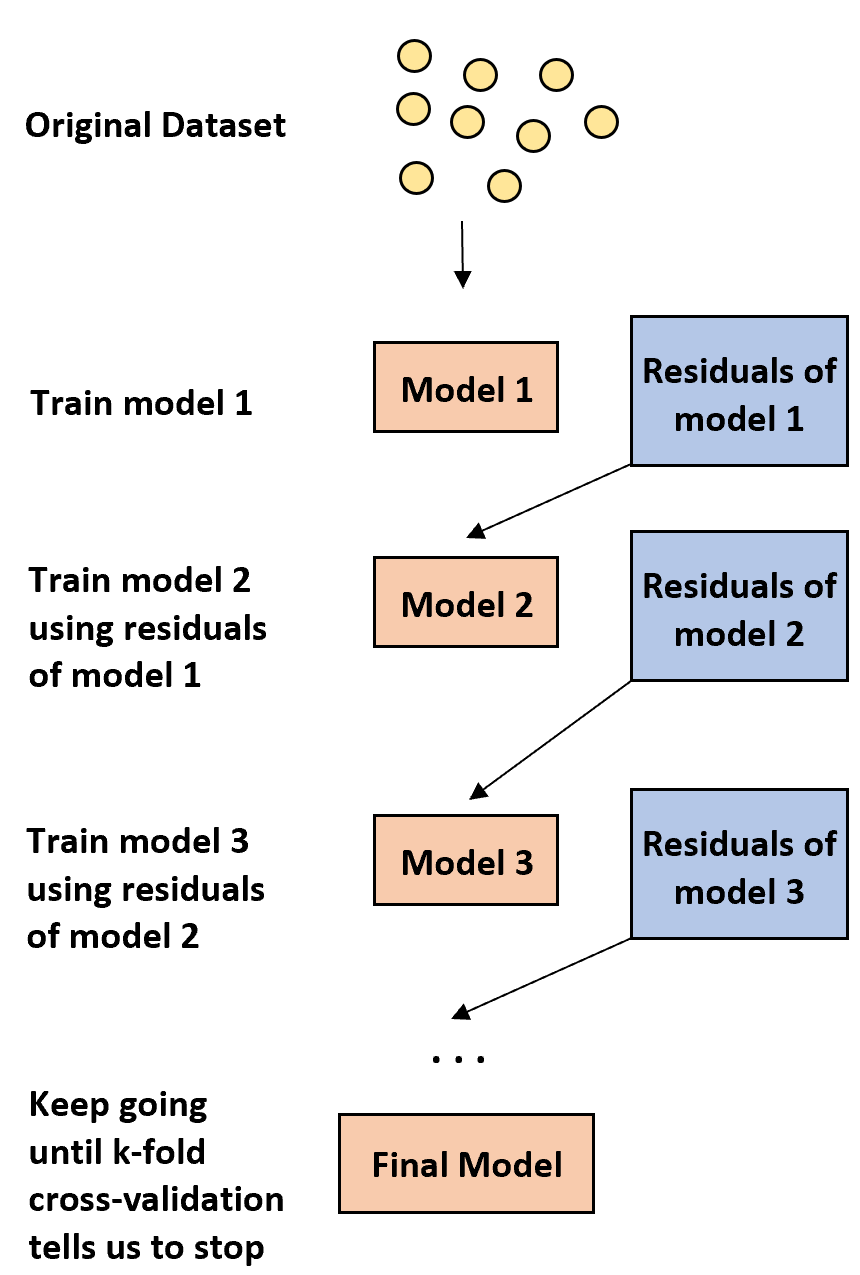
1. Спочатку побудуйте слабку модель.
- «Слабка» модель — це модель, рівень помилок якої лише трохи кращий за випадкову оцінку.
- На практиці це зазвичай дерево рішень лише з одним або двома розділами.
2. Далі побудуйте ще одну слабку модель на основі залишків попередньої моделі.
- На практиці ми використовуємо залишки попередньої моделі (тобто помилки наших прогнозів), щоб підібрати нову модель, яка трохи покращує загальний рівень помилок.
3. Продовжуйте цей процес, доки k-кратна перехресна перевірка не скаже нам зупинитися.
- На практиці ми використовуємо k-кратну перехресну перевірку , щоб визначити, коли нам слід припинити розробку посиленої моделі.
Використовуючи цей метод, ми можемо почати зі слабкої моделі та продовжувати «покращувати» її продуктивність, послідовно будуючи нові дерева, які покращують продуктивність попереднього дерева, поки не отримаємо остаточну модель з високою точністю прогнозування.
Чому посилення працює?
Виявилося, що прискорення здатне створювати одні з найпотужніших моделей у всьому машинному навчанні.
У багатьох галузях промисловості форсовані моделі використовуються як еталонні моделі у виробництві, оскільки вони, як правило, перевершують усі інші моделі.
Причина, чому розширені шаблони працюють так добре, полягає в розумінні простої ідеї:
1. По-перше, вдосконалені моделі будують слабке дерево рішень, яке має низьку точність прогнозування. Кажуть, що це дерево рішень має низьку дисперсію та високе зміщення.
2. Оскільки вдосконалені моделі слідують послідовному процесу вдосконалення попередніх дерев рішень, загальна модель здатна повільно зменшувати зміщення на кожному кроці без значного збільшення дисперсії.
3. Остаточна підібрана модель, як правило, має достатньо низькі зміщення та дисперсію, що призводить до моделі, здатної створювати низькі рівні помилок тестування на нових даних.
Переваги та недоліки форсування
Очевидною перевагою бустингу є те, що він здатний створювати моделі з високою точністю прогнозування порівняно з майже всіма іншими типами моделей.
Потенційним недоліком є те, що підігнану покращену модель дуже важко інтерпретувати. Хоча він може запропонувати надзвичайну здатність передбачати значення відповіді нових даних, важко пояснити точний процес, який він використовує для досягнення цього.
На практиці більшість спеціалістів із обробки даних і машинного навчання створюють вдосконалені моделі, оскільки хочуть мати можливість точно передбачити значення відповіді нових даних. Таким чином, той факт, що вдосконалені моделі важко інтерпретувати, як правило, не є проблемою.
Бустер на практиці
На практиці існує багато типів алгоритмів, які використовуються для посилення, зокрема:
Залежно від розміру вашого набору даних і потужності обробки вашої машини, один із цих методів може бути кращим за інший.
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше