Підгонка кривої в python (з прикладами)
Часто вам може знадобитися підігнати криву до набору даних у Python.
У наступному покроковому прикладі пояснюється, як підігнати криві до даних у Python за допомогою функції numpy.polyfit() і як визначити, яка крива найкраще відповідає даним.
Крок 1: Створення та візуалізація даних
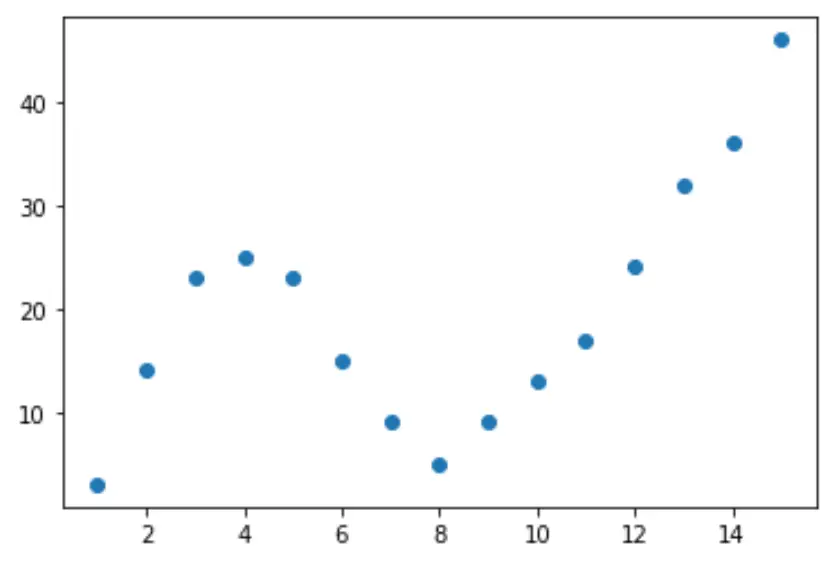
Давайте почнемо зі створення підробленого набору даних, а потім створимо діаграму розсіювання для візуалізації даних:
import pandas as pd import matplotlib. pyplot as plt #createDataFrame df = pd. DataFrame ({' x ': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15], ' y ': [3, 14, 23, 25, 23, 15, 9, 5, 9, 13, 17, 24, 32, 36, 46]}) #create scatterplot of x vs. y plt. scatter (df. x , df. y )
Крок 2: Налаштуйте кілька кривих
Тоді давайте підберемо кілька моделей поліноміальної регресії до даних і візуалізуємо криву кожної моделі на одному графіку:
import numpy as np
#fit polynomial models up to degree 5
model1 = np. poly1d (np. polyfit (df. x , df. y , 1))
model2 = np. poly1d (np. polyfit (df. x , df. y , 2))
model3 = np. poly1d (np. polyfit (df. x , df. y , 3))
model4 = np. poly1d (np. polyfit (df. x , df. y , 4))
model5 = np. poly1d (np. polyfit (df. x , df. y , 5))
#create scatterplot
polyline = np. linspace (1, 15, 50)
plt. scatter (df. x , df. y )
#add fitted polynomial lines to scatterplot
plt. plot (polyline, model1(polyline), color=' green ')
plt. plot (polyline, model2(polyline), color=' red ')
plt. plot (polyline, model3(polyline), color=' purple ')
plt. plot (polyline, model4(polyline), color=' blue ')
plt. plot (polyline, model5(polyline), color=' orange ')
plt. show ()
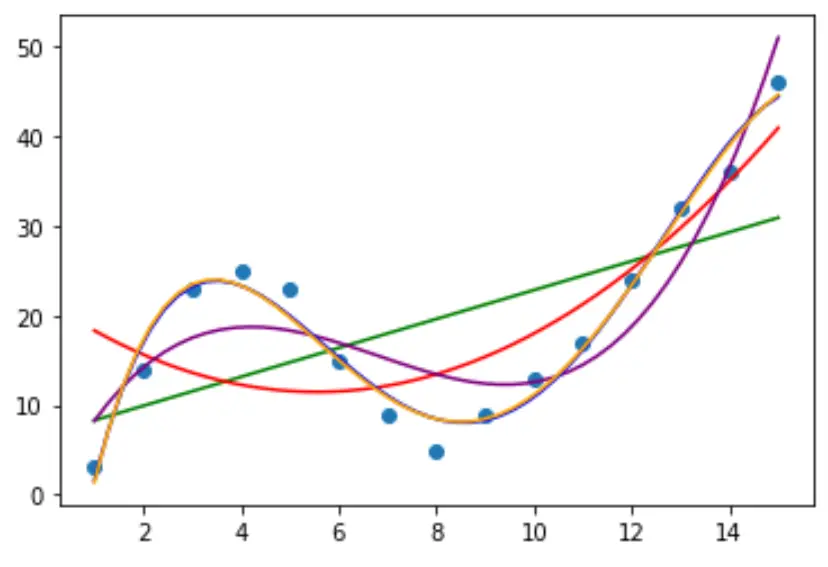
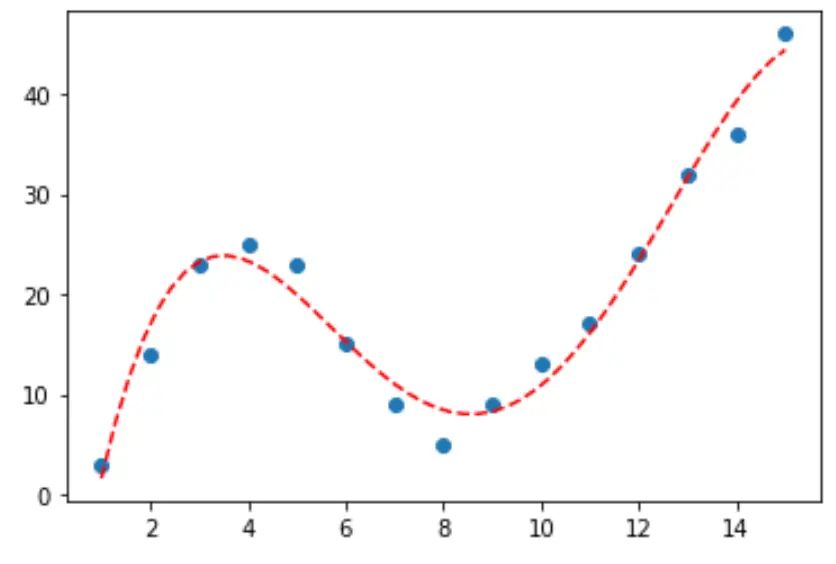
Щоб визначити, яка крива найкраще відповідає даним, ми можемо подивитися на скоригований R-квадрат кожної моделі.
Це значення повідомляє нам про відсоток варіації змінної відповіді, який можна пояснити змінною(ями) предиктора в моделі, скоригованою на кількість змінних предиктора.
#define function to calculate adjusted r-squared def adjR(x, y, degree): results = {} coeffs = np. polyfit (x, y, degree) p = np. poly1d (coeffs) yhat = p(x) ybar = np. sum (y)/len(y) ssreg = np. sum ((yhat-ybar)**2) sstot = np. sum ((y - ybar)**2) results[' r_squared '] = 1- (((1-(ssreg/sstot))*(len(y)-1))/(len(y)-degree-1)) return results #calculated adjusted R-squared of each model adjR(df. x , df. y , 1) adjR(df. x , df. y , 2) adjR(df. x , df. y , 3) adjR(df. x , df. y , 4) adjR(df. x , df. y , 5) {'r_squared': 0.3144819} {'r_squared': 0.5186706} {'r_squared': 0.7842864} {'r_squared': 0.9590276} {'r_squared': 0.9549709}
З результату ми бачимо, що модель з найвищим скоригованим R-квадратом є поліномом четвертого ступеня, який має скоригований R-квадрат 0,959 .
Крок 3: Візуалізуйте остаточну криву
Нарешті, ми можемо створити діаграму розсіювання з кривою поліноміальної моделі четвертого ступеня:
#fit fourth-degree polynomial model4 = np. poly1d (np. polyfit (df. x , df. y , 4)) #define scatterplot polyline = np. linspace (1, 15, 50) plt. scatter (df. x , df. y ) #add fitted polynomial curve to scatterplot plt. plot (polyline, model4(polyline), ' -- ', color=' red ') plt. show ()
Ми також можемо отримати рівняння для цього рядка за допомогою функції print() :
print (model4)
4 3 2
-0.01924x + 0.7081x - 8.365x + 35.82x - 26.52
Рівняння кривої виглядає наступним чином:
y = -0,01924x 4 + 0,7081x 3 – 8,365x 2 + 35,82x – 26,52
Ми можемо використовувати це рівняння, щоб передбачити значення змінної відповіді на основі змінних предиктора в моделі. Наприклад, якщо x = 4, ми передбачимо, що y = 23,32 :
y = -0,0192(4) 4 + 0,7081(4) 3 – 8,365(4) 2 + 35,82(4) – 26,52 = 23,32
Додаткові ресурси
Вступ до поліноміальної регресії
Як виконати поліноміальну регресію в Python
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше