Регресія чи класифікація: в чому різниця?
Алгоритми машинного навчання можна розділити на два типи: контрольовані та неконтрольовані алгоритми навчання .

Алгоритми навчання під наглядом можна класифікувати на два типи:
1. Регресія: змінна відповіді є безперервною.
Наприклад, змінна відповіді може бути такою:
- вага
- Висота
- Ціна
- час
- Всього одиниць
У кожному випадку регресійна модель прагне передбачити безперервну величину.
Приклад регресії:
Скажімо, у нас є набір даних, що містить три змінні для 100 різних будинків: квадратні метри, кількість ванних кімнат і ціну продажу.
Ми могли б застосувати регресійну модель, яка використовує квадратні метри та кількість ванних кімнат як пояснювальні змінні, а ціну продажу – як змінну відповіді.
Потім ми могли б використати цю модель для прогнозування ціни продажу будинку на основі його квадратних метрів і кількості ванних кімнат.
Це приклад регресійної моделі, оскільки змінна відповіді (ціна продажу) є безперервною.
Найпоширенішим способом вимірювання точності регресійної моделі є обчислення середньоквадратичної помилки (RMSE), метрики, яка повідомляє нам, наскільки далекі наші прогнозовані значення від наших спостережуваних значень у моделі в середньому. Він розраховується таким чином:
RMSE = √ Σ(P i – O i ) 2 / n
золото:
- Σ – химерний символ, який означає «сума»
- P i – прогнозоване значення для i-го спостереження
- O i – спостережене значення для i-го спостереження
- n – розмір вибірки
Чим менший RMSE, тим краще регресійна модель відповідає даним.
2. Класифікація: Змінна відповіді є категоричною.
Наприклад, змінна відповіді може приймати такі значення:
- Чоловік чи жінка
- Успіх чи невдача
- Низький, середній або високий
У кожному випадку модель класифікації прагне передбачити мітку класу.
Приклад класифікації:
Скажімо, у нас є набір даних, що містить три змінні для 100 різних студентських баскетболістів: середня кількість очок за гру, рівень дивізіону та те, чи були вони задрафтовані в НБА.
Ми могли б адаптувати модель класифікації, яка використовує середні очки за гру та за рівень дивізіону як пояснювальні змінні та «проектований» як змінну відповіді.
Потім ми могли б використати цю модель, щоб передбачити, чи буде даний гравець задрафтований до НБА, на основі його середнього рівня очок за гру та рівня дивізіону.
Це приклад моделі класифікації, оскільки змінна відповіді («написана») є категоричною. Іншими словами, він може приймати значення лише у двох різних категоріях: «Письмовий» або «Ненаписаний».
Найпоширенішим способом вимірювання точності моделі класифікації є просто обчислення відсотка правильних класифікацій, зроблених моделлю:
Точність = класифікація виправлення / загальна кількість спроб класифікації * 100%
Наприклад, якщо модель правильно визначає, чи буде задрафтований гравець до НБА 88 разів із 100 можливих, то точність моделі дорівнює:
Точність = (88/100) * 100% = 88%
Чим вища точність, тим краще модель класифікації здатна передбачити результати.
Подібності між регресією та класифікацією
Алгоритми регресії та класифікації схожі в наступному:
- Обидва є контрольованими алгоритмами навчання, тобто обидва включають змінну відповіді.
- Обидва використовують одну або кілька пояснювальних змінних для створення моделей для прогнозування відповіді.
- Обидва можна використовувати, щоб зрозуміти, як зміни в значеннях пояснювальних змінних впливають на значення змінної відповіді.
Відмінності між регресією та класифікацією
Алгоритми регресії та класифікації відрізняються за такими ознаками:
- Алгоритми регресії прагнуть передбачити безперервну кількість, а алгоритми класифікації прагнуть передбачити мітку класу.
- Те, як ми вимірюємо точність моделей регресії та класифікації, відрізняється.
Перетворення регресії в класифікацію
Слід зазначити, що задачу регресії можна перетворити на проблему класифікації, просто дискретизуючи змінну відповіді на відсіки.
Наприклад, скажімо, у нас є набір даних, який містить три змінні: квадратні метри, кількість ванних кімнат і ціну продажу.
Ми могли б створити регресійну модель, використовуючи квадратні метри та кількість ванних кімнат, щоб передбачити ціни продажу.
Однак ми можемо розділити ціну продажу на три різні класи:
- $80 000 – $160 000: «Низька ціна продажу»
- $161 000 – $240 000: «Середня ціна продажу»
- $241 000 – $320 000: «Висока ціна продажу»
Тоді ми могли б використовувати квадратні метри та кількість ванних кімнат як пояснювальні змінні, щоб передбачити, до якого класу (низького, середнього чи високого) потрапить ціна продажу даного будинку.
Це був би приклад моделі класифікації, оскільки ми намагаємося помістити кожен будинок у клас.
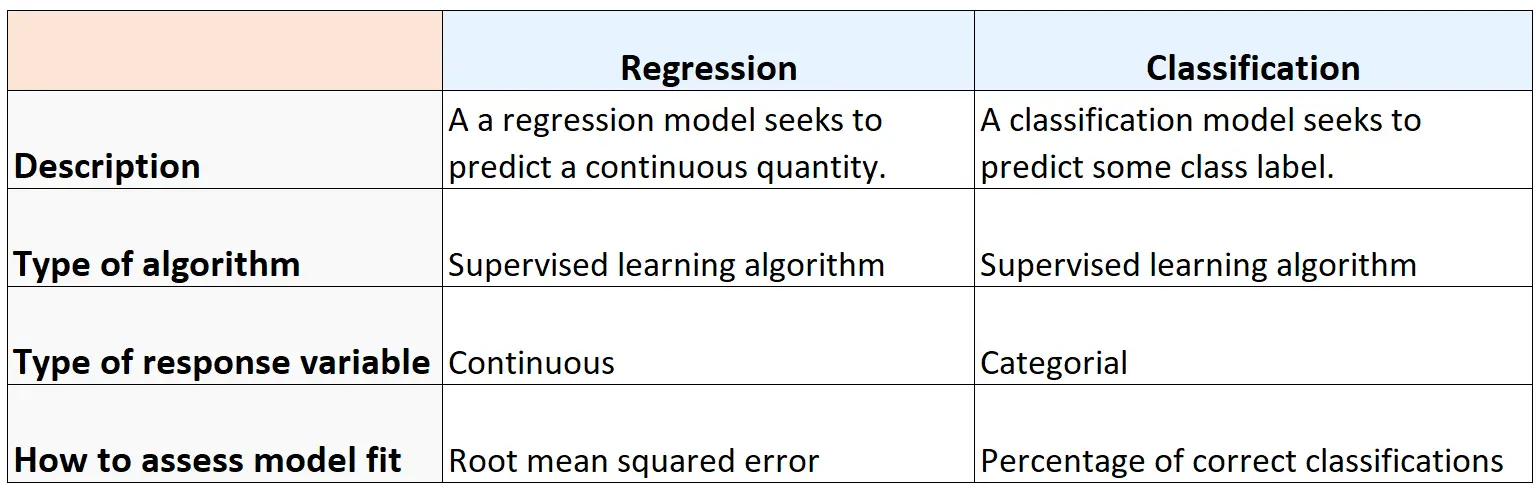
Резюме
У наведеній нижче таблиці підсумовано подібності та відмінності між алгоритмами регресії та класифікації:
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше