Як використовувати найменш значущу різницю фішера (lsd) у r
Односторонній дисперсійний аналіз використовується, щоб визначити, чи існує статистично значуща різниця між середніми значеннями трьох або більше незалежних груп.
Припущення, які використовуються в односторонньому дисперсійному аналізі:
- H 0 : Середні значення рівні для кожної групи.
- H A : Принаймні один із способів відрізняється від інших.
Якщо p-значення ANOVA нижче певного рівня значущості (наприклад, α = 0,05), ми можемо відхилити нульову гіпотезу та зробити висновок, що принаймні одне з групових середніх відрізняється від інших.
Але щоб точно знати, які групи відрізняються одна від одної, нам потрібно провести ретельний тест.
Зазвичай використовуваним ретроспективним тестом є тест найменшої значущої різниці (LSD) Фішера .
Ви можете використовувати функцію LSD.test() з пакету agricolae , щоб виконати цей тест у R.
У наступному прикладі показано, як використовувати цю функцію на практиці.
Приклад: ЛСД-тест Фішера в R
Припустімо, професор хоче знати, чи призводять три різні методи навчання до різних результатів тестів серед студентів.
Щоб перевірити це, вона випадковим чином призначає 10 студентів для використання кожної методики навчання та записує їхні результати іспитів.
У наведеній нижче таблиці наведено результати іспиту кожного студента на основі використаної методики навчання:
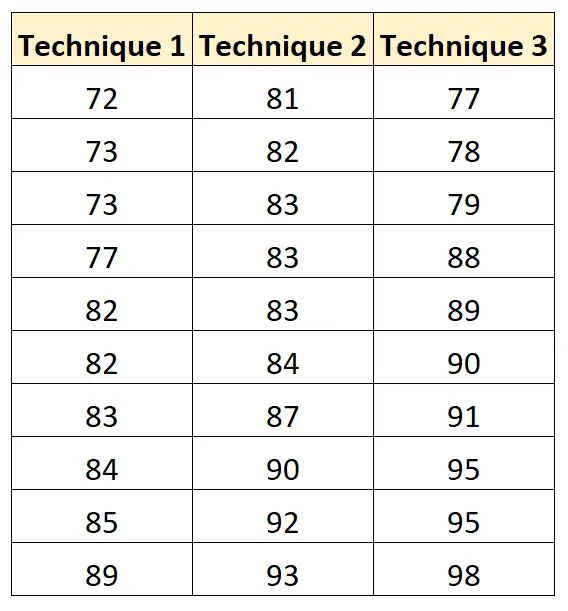
Ми можемо використати наступний код, щоб створити цей набір даних і виконати односторонній дисперсійний аналіз на ньому в R:
#create data frame
df <- data. frame (technique = rep(c("tech1", "tech2", "tech3"), each = 10 ),
score = c(72, 73, 73, 77, 82, 82, 83, 84, 85, 89,
81, 82, 83, 83, 83, 84, 87, 90, 92, 93,
77, 78, 79, 88, 89, 90, 91, 95, 95, 98))
#view first six rows of data frame
head(df)
technical score
1 tech1 72
2 tech1 73
3 tech1 73
4 tech1 77
5 tech1 82
6 tech1 82
#fit one-way ANOVA
model <- aov(score ~ technique, data = df)
#view summary of one-way ANOVA
summary(model)
Df Sum Sq Mean Sq F value Pr(>F)
technical 2 341.6 170.80 4.623 0.0188 *
Residuals 27,997.6 36.95
---
Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Оскільки p-значення в таблиці ANOVA (0,0188) менше 0,05, ми можемо зробити висновок, що всі середні результати іспитів у трьох групах не однакові.
Таким чином, ми можемо виконати ЛСД-тест Фішера, щоб визначити, які середні групи відрізняються.
Наступний код показує, як це зробити:
library (agricolae)
#perform Fisher's LSD
print( LSD.test (model," technic "))
$statistics
MSerror Df Mean CV t.value LSD
36.94815 27 84.6 7.184987 2.051831 5.57767
$parameters
test p.adjusted name.t ntr alpha
Fisher-LSD none technical 3 0.05
$means
std score r LCL UCL Min Max Q25 Q50 Q75
tech1 80.0 5.868939 10 76.05599 83.94401 72 89 74.00 82.0 83.75
tech2 85.8 4.391912 10 81.85599 89.74401 81 93 83.00 83.5 89.25
tech3 88.0 7.557189 10 84.05599 91.94401 77 98 81.25 89.5 94.00
$comparison
NULL
$groups
score groups
tech3 88.0 a
tech2 85.8a
tech1 80.0 b
attr(,"class")
[1] “group”
Частина результату, яка нас цікавить найбільше, це розділ під назвою $groups . Техніки, які мають різні персонажі в колонці груп , дуже відрізняються.
З результату ми бачимо:
- Техніка 1 і Техніка 3 мають суттєво різні середні оцінки іспитів (оскільки техніка 1 має значення «b», а техніка 3 — «a»).
- Техніка 1 і Техніка 2 мають суттєво різні середні оцінки за іспит (оскільки техніка 1 має значення «b», а техніка 2 — «а»).
- Техніка 2 і Техніка 3 не мають суттєво різних середніх балів за іспит (оскільки вони обидва мають значення «а»)
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в R:
Як виконати односторонній дисперсійний аналіз у R
Як виконати тест Bonferroni post hoc у R
Як виконати пост-тест Шеффе в R
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше