Як побудувати графік розподілу значень стовпців у pandas
Ви можете використовувати наступні методи, щоб побудувати графік розподілу значень стовпців у pandas DataFrame:
Спосіб 1: побудуйте графік розподілу значень у стовпці
df[' my_column ']. plot (kind=' kde ')
Спосіб 2: побудуйте графік розподілу значень в одному стовпці, згрупованих в іншому стовпці
df. groupby (' group_column ')[' values_column ']. plot (kind=' kde ')
Наступні приклади показують, як використовувати кожен метод на практиці з такими pandas DataFrame:
import pandas as pd #createDataFrame df = pd. DataFrame ({' team ': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B'], ' points ': [3, 3, 4, 5, 4, 7, 7, 7, 10, 11, 8, 7, 8, 9, 12, 12, 12, 14, 15, 17]}) #view DataFrame print (df) team points 0 to 3 1 to 3 2 to 4 3 to 5 4 to 4 5 TO 7 6 to 7 7 to 7 8 to 10 9 to 11 10 B 8 11 B 7 12 B 8 13 B 9 14 B 12 15 B 12 16 B 12 17 B 14 18 B 15 19 B 17
Приклад 1: побудуйте графік розподілу значень у стовпці
Наступний код показує, як побудувати графік розподілу значень у стовпці балів :
#plot distribution of values in points column df[' points ']. plot (kind=' kde ')
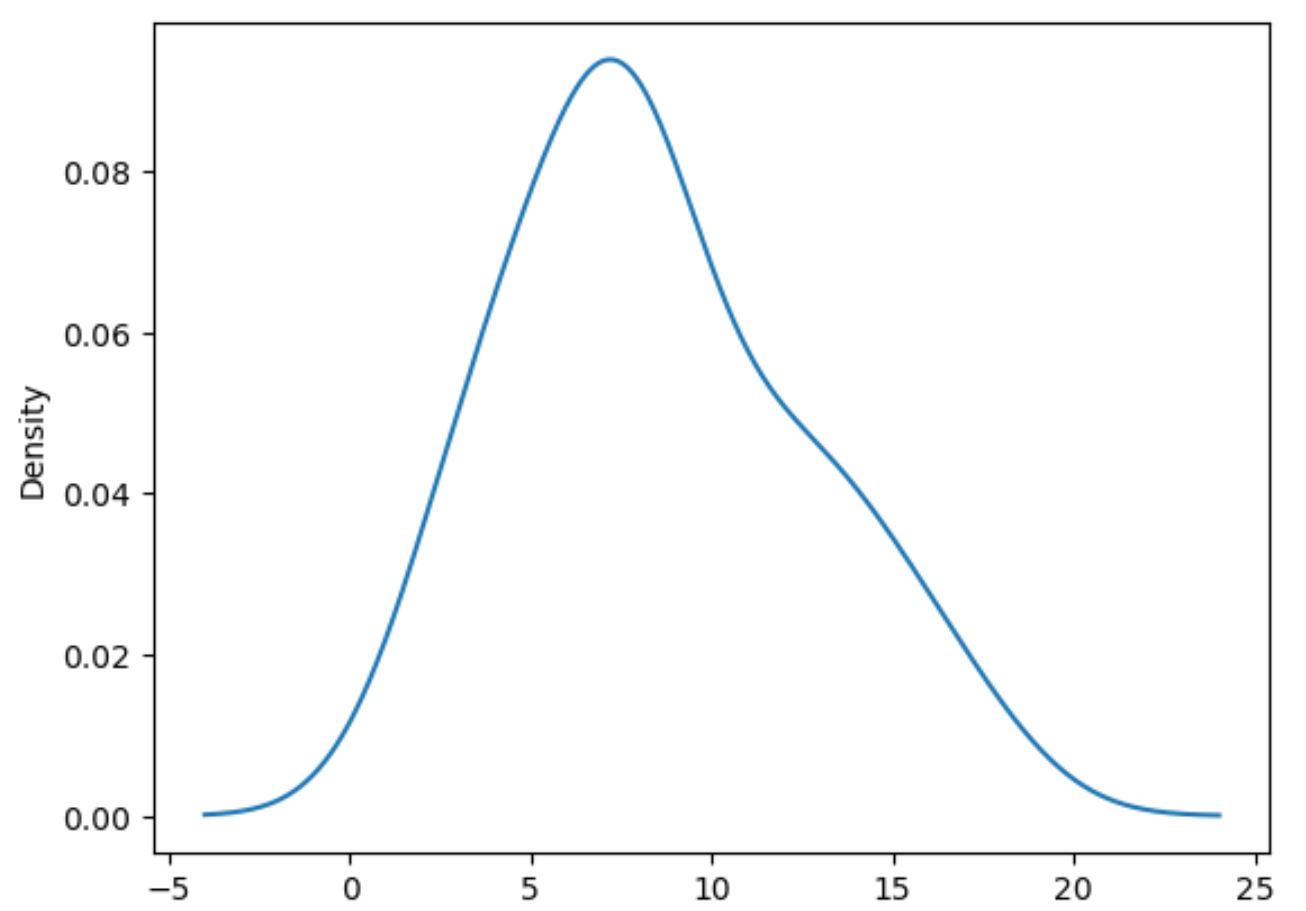
Зверніть увагу, що kind=’kde’ вказує pandas використовувати оцінку щільності ядра , яка створює плавну криву, яка підсумовує розподіл значень змінної.
Якщо замість цього ви хочете створити гістограму, ви можете вказати kind=’hist’ таким чином:
#plot distribution of values in points column using histogram df[' points ']. plot (kind=' hist ', edgecolor=' black ')
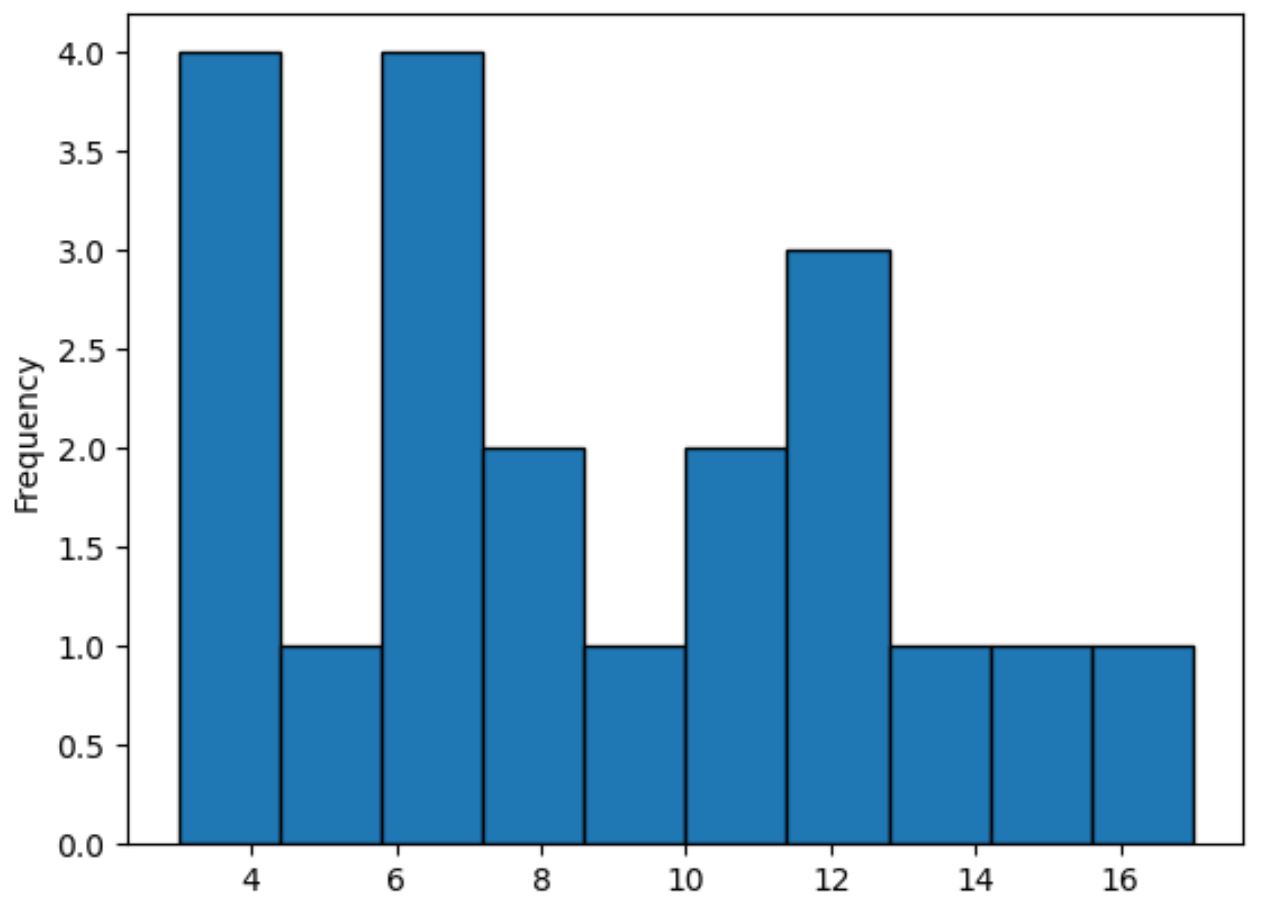
Цей метод використовує стовпчики для представлення частот значень у стовпчику точок , на відміну від плавної лінії, яка підсумовує форму розподілу.
Приклад 2: побудуйте графік розподілу значень в одному стовпці, згрупованих в іншому стовпці
Наступний код показує, як побудувати графік розподілу значень у стовпці балів , згрупованих за стовпцем команди :
import matplotlib.pyplot as plt #plot distribution of points by team df. groupby (' team ')[' points ']. plot (kind=' kde ') #add legend plt. legend ([' A ',' B '], title=' Team ') #add x-axis label plt. xlabel (' Points ')
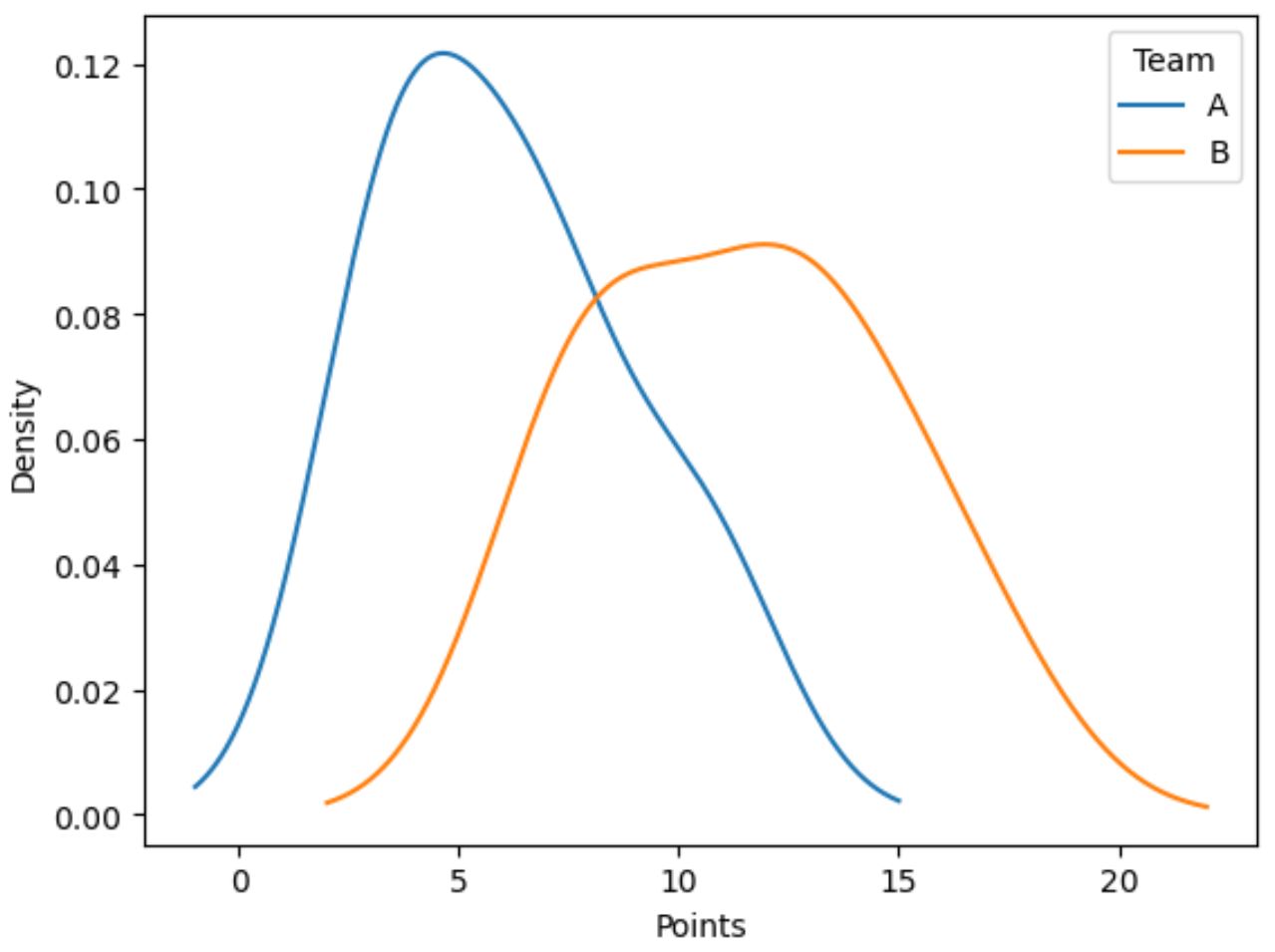
Синя лінія показує розподіл очок гравців команди А, а помаранчева лінія показує розподіл очок гравців команди Б.
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в pandas:
Як додати заголовки до сюжетів у Pandas
Як скоригувати розмір фігури панди сюжет
Як побудувати декілька Pandas DataFrames у підсхемах
Як створити та налаштувати сюжетні легенди в Pandas
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше