Розподіл вибірки
У цій статті пояснюється, що таке розподіл вибірки в статистиці та для чого він використовується. Отже, ви знайдете значення вибіркового розподілу, конкретний приклад вибіркового розподілу та, крім того, формули для найпоширеніших типів вибіркового розподілу.
Що таке розподіл вибірки?
Вибірковий розподіл або вибірковий розподіл — це розподіл, який є результатом розгляду всіх можливих вибірок сукупності. Іншими словами, вибірковий розподіл — це розподіл, отриманий шляхом обчислення параметра вибірки всіх можливих вибірок із сукупності.
Наприклад, якщо ми витягнемо всі можливі вибірки зі статистичної сукупності та обчислимо середнє значення кожної вибірки, набір вибіркових середніх утворить розподіл вибірки. Точніше, оскільки обчислений параметр є середнім арифметичним, він є вибірковим розподілом середнього.
У статистиці вибірковий розподіл використовується для обчислення ймовірності наближення до значення параметра сукупності при дослідженні однієї вибірки. Подібним чином розподіл вибірки дозволяє нам оцінити похибку вибірки для заданого розміру вибірки.
Приклад розподілу вибірки
Тепер, коли ми знаємо визначення розподілу вибірки, давайте розглянемо простий приклад, щоб повністю зрозуміти концепцію.
- У ящик ми кладемо три кулі, на кожній з яких записане число від одного до трьох, так що одна кулька має номер 1, інша кулька — 2, а остання — 3. Для зразка розміром n = 2, розраховує ймовірності вибіркового розподілу середнього, якщо відібрано вибірки із заміною.
Зразки відбираються із заміщенням, тобто кулька, взята для відбору першого елемента зразка, повертається в коробку і може бути відібрана знову під час другого вилучення. Отже, всі можливі вибірки з сукупності:
1,1 1,2 1,3
2.1 2.2 2.3
3.1 3.2 3.3
Таким чином, обчислюємо середнє арифметичне кожної можливої вибірки:









Отже, ймовірності отримання кожного значення вибіркового середнього при відборі випадкової вибірки з сукупності наступні:
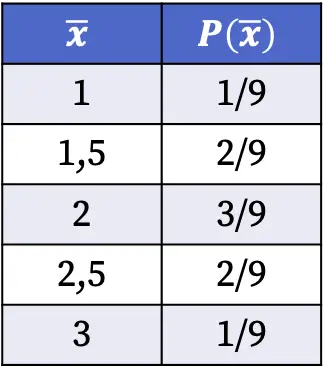
Імовірності розподілу вибірки, наведені в таблиці вище, були розраховані шляхом ділення кількості вибірок із вказаним середнім значенням на загальну кількість можливих випадків. Наприклад: середнє значення вибірки дорівнює 1,5 у двох випадках із дев’яти можливих, тому P(1,5)=2/9.
Види вибіркових розподілів
Вибіркові розподіли (або вибіркові розподіли) можна класифікувати на основі параметра вибірки, з якого вони були отримані. Отже, найпоширенішими типами розподілів є:
- Вибірковий розподіл середнього : це вибірковий розподіл, який є результатом обчислення середнього арифметичного кожного зразка.
- Пропорційний вибірковий розподіл : це вибірковий розподіл, отриманий шляхом обчислення частки всіх вибірок.
- Вибірковий розподіл дисперсії : це вибірковий розподіл, який утворює набір усіх дисперсій у вибірці.
- Різниця середніх вибіркового розподілу : це вибірковий розподіл, який є результатом обчислення різниці між середніми значеннями всіх можливих вибірок із двох різних сукупностей.
- Різниця в пропорціях. Розподіл вибірки : це розподіл вибірки, отриманий шляхом віднімання всіх можливих пропорцій вибірки з двох сукупностей.
Кожен тип розподілу вибірки пояснюється більш детально нижче.
Вибірковий розподіл середнього
Дано генеральну сукупність, яка відповідає нормальному розподілу ймовірностей із середнім

і стандартне відхилення

і витягуються зразки розміру

, вибірковий розподіл середнього також буде визначено нормальним розподілом, що має такі характеристики:
![\begin{array}{c}\mu_{\overline{x}}=\mu \qquad \sigma_{\overline{x}}=\cfrac{\sigma}{\sqrt{n}}\\[4ex]\displaystyle N_{\overline{x}}\left(\mu, \frac{\sigma}{\sqrt{n}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-44571aa7337b095ab9c9fa1f746e93a5_l3.png "Rendered by QuickLaTeX.com")
золото

є середнім значенням вибіркового розподілу середнього значення та

є його стандартним відхиленням. Крім того,

стандартна помилка розподілу вибірки.
Примітка. Якщо генеральна сукупність не відповідає нормальному розподілу, але розмір вибірки є великим (n>30), вибірковий розподіл середнього також можна наблизити до нормального розподілу вище за межею центральної теореми.
Отже, оскільки вибірковий розподіл середнього відповідає нормальному розподілу, формула для обчислення будь-якої ймовірності, пов’язаної з вибірковим середнім, має вигляд:

золото:
-

це зразок засобів.
-
Це середній показник населення.
-

стандартне відхилення сукупності.
-
це розмір вибірки.
-

є змінною, визначеною стандартним нормальним розподілом N(0,1).
Вибірковий розподіл частки
Фактично, коли ми вивчаємо частку вибірки, ми аналізуємо випадки успіху. Таким чином, випадкова змінна в дослідженні відповідає біноміальному розподілу ймовірностей.
Відповідно до центральної граничної теореми, для великих розмірів (n>30) ми можемо наблизити біноміальний розподіл до нормального. Таким чином, вибірковий розподіл частки наближається до нормального розподілу з такими параметрами:
![\begin{array}{c}\displaystyle\mu_{p}=p \qquad \sigma_{p}=\sqrt{\frac{pq}{n}}\\[4ex]\displaystyle N_{p}\left(p, \sqrt{\frac{pq}{n}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-f3408076893f390bb65baecfe38e6eff_l3.png "Rendered by QuickLaTeX.com")
золото

це ймовірність успіху і

це ймовірність невдачі

.
Примітка. Біноміальний розподіл можна наблизити до нормального, лише якщо


І

.
Отже, оскільки вибірковий розподіл частки можна наблизити до нормального розподілу, формула для обчислення будь-якої ймовірності, пов’язаної з часткою вибірки, має вигляд:

золото:
-

є пропорцією зразка.
-
це частка населення.
-
ймовірність відмови популяції,
.
-
це розмір вибірки.
-
є змінною, визначеною стандартним нормальним розподілом N(0,1).
Вибірковий розподіл дисперсії
Вибірковий розподіл дисперсії визначається розподілом ймовірності хі-квадрат. Таким чином, формула для статистики вибіркового розподілу дисперсії :

золото:
-

є статистикою вибіркового розподілу дисперсії, яка слідує за розподілом хі-квадрат.
-
це розмір вибірки.
-

дисперсія вибірки.
-

є дисперсія сукупності.
Вибірковий розподіл різниці середніх
Якщо розмір вибірки достатньо великий (n 1 ≥30 і n 2 ≥30), вибірковий розподіл середньої різниці відповідає нормальному розподілу. Точніше, параметри зазначеного розподілу розраховуються наступним чином:
![\begin{array}{c}\displaystyle \mu_{\overline{x_1}-\overline{x_2}}=\mu_1-\mu_2 \qquad \sigma_{\overline{x_1}-\overline{x_2}}=\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}\\[6ex]\displaystyle N_{\overline{x_1}-\overline{x_2}}\left(\mu_1-\mu_2, \sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-90c67b74b4e9326b7869d641a59725d9_l3.png "Rendered by QuickLaTeX.com")
Примітка. Якщо обидві генеральні сукупності є нормальними розподілами, тоді вибірковий розподіл різниці середніх відповідає нормальному розподілу незалежно від розмірів вибірки.
Отже, оскільки вибірковий розподіл різниці середніх визначається нормальним розподілом, формула для розрахунку статистики вибіркового розподілу різниці середніх має вигляд:

золото:
-

є середнім значенням вибірки i.
-

це середнє значення населення i.
-

є стандартним відхиленням сукупності i.
-

це розмір вибірки i.
-
є змінною, визначеною стандартним нормальним розподілом N(0,1).
Зауважте, що вибірки з різних сукупностей можуть мати різні розміри вибірки.
Вибірковий розподіл різниці в пропорціях
Вибірки, відібрані для розподілу вибірки різниць у пропорціях, визначаються біноміальними розподілами, оскільки для практичних цілей пропорція є відношенням успішних випадків до загальної кількості спостережень.
Однак завдяки центральній граничній теоремі біноміальні розподіли можуть бути наближені до нормальних розподілів ймовірностей. Таким чином, вибірковий розподіл різниці в пропорціях може бути наближено до нормального розподілу з такими характеристиками:
![\begin{array}{c}\displaystyle\mu_{\widehat{p_1}-\widehat{p_2}}=p_1-p_2 \qquad \sigma_{\widehat{p_1}-\widehat{p_2}}=\sqrt{\frac{p_1q_1}{n_1}+\frac{p_2q_2}{n_2}}\\[6ex]\displaystyle N_{p}\left(p_1-p_2, \sqrt{\frac{p_1q_1}{n_1}+\frac{p_2q_2}{n_2}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-a1ce359b5dd6d80f8d27b0b9a1034bed_l3.png "Rendered by QuickLaTeX.com")
Примітка. Вибірковий розподіл різниці в пропорціях можна наблизити до нормального розподілу, лише якщо

,

,

,

,

І

.
Отже, оскільки вибірковий розподіл різниці в пропорціях можна наблизити до нормального розподілу, формула для розрахунку статистики вибіркового розподілу різниці в пропорціях виглядає наступним чином:

золото:
-

є пропорцією зразка i.
-

це частка населення i.
-

ймовірність відмови популяції i,

.
-
це розмір вибірки i.
-
є змінною, визначеною стандартним нормальним розподілом N(0,1).
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше