Як виконати перетворення бокса-кокса в sas
Перетворення боксу-Кокса є широко використовуваним методом для перетворення ненормально розподіленого набору даних у більш нормально розподілений набір.
Основна ідея цього методу полягає в тому, щоб знайти таке значення для λ, щоб перетворені дані були якнайближчими до нормального розподілу, використовуючи таку формулу:
- y(λ) = (y λ – 1) / λ, якщо y ≠ 0
- y(λ) = log(y), якщо y = 0
Ми можемо визначити оптимальне значення для використання для λ у SAS за допомогою процедури PROC TRANSREG .
У наступному прикладі показано, як використовувати цю процедуру на практиці.
Приклад: перетворення Бокса-Кокса в SAS
Припустімо, що в SAS є такий набір даних:
/*create dataset*/ data my_data; input xy; datalines ; 7 1 7 1 8 1 3 2 2 2 4 2 4 2 6 2 6 2 7 3 5 3 3 3 3 6 5 7 8 8 ; run; /*view dataset*/ proc print data =my_data;
Припустімо, що ми використовуємо PROC REG , щоб підібрати просту модель лінійної регресії до цього набору даних, використовуючи x як змінну прогностику та y як змінну відповіді.
/*fit simple linear regression model*/ proc reg data =my_data; model y = x; run ;
На вихідних діагностичних графіках ми можемо відобразити графік залишків і квантилів (крайній лівий графік у середньому рядку), щоб побачити, чи приблизно нормально розподілені залишки в моделі:
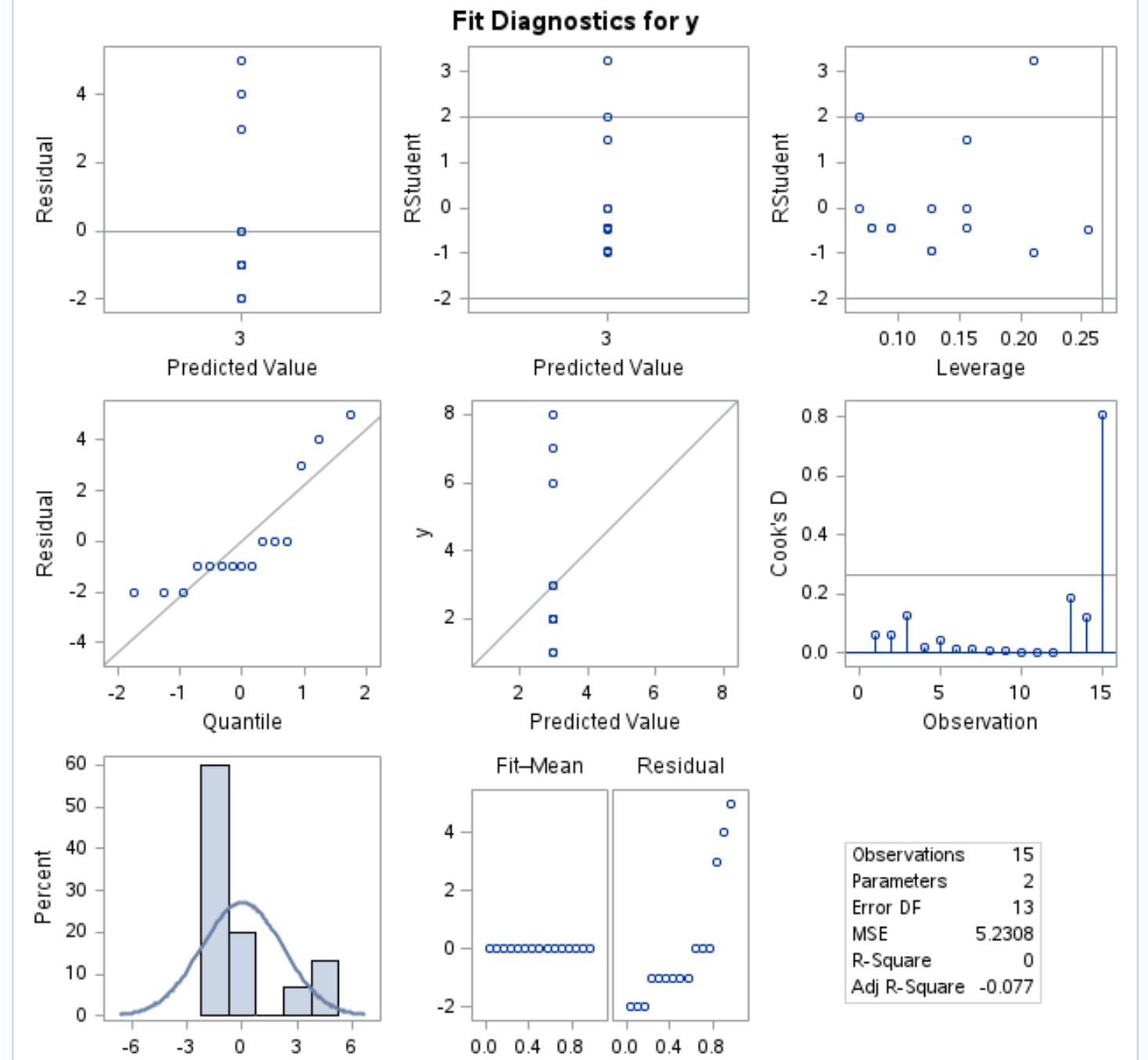
Якщо залишки лежать приблизно вздовж правої діагональної лінії графіка, ми зазвичай припускаємо, що залишки розподілені нормально.
З графіка ми бачимо, що залишки не дуже слідують прямій діагональній лінії.
Це вказує на те, що змінна відповіді в регресійній моделі, ймовірно, не розподілена нормально.
Оскільки змінна відповіді не є нормально розподіленою, ми можемо використовувати PROC TRANSREG , щоб ідентифікувати значення для λ, яке ми можемо використати для перетворення змінної відповіді таким чином, щоб вона була більш нормально розподілена:
/*perform box-cox transformation*/ proc transreg data =my_data; model boxcox (y) = identity (x); run ;
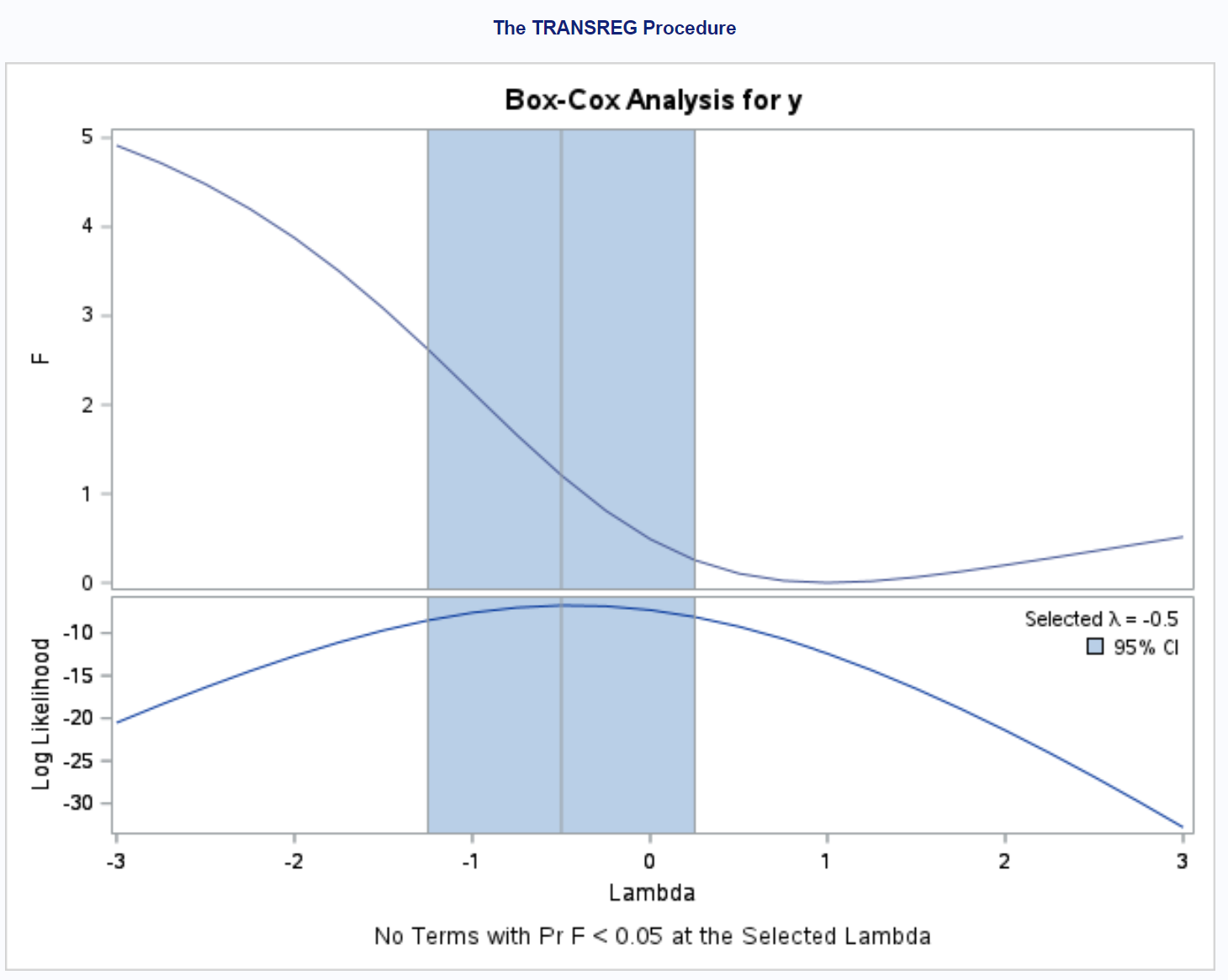
Результат говорить нам, що вибране значення для використання для λ становить – 0,5 .
Таким чином, ми можемо підібрати просту модель лінійної регресії, замінивши початкову змінну відповіді y на змінну y = (y -0,5 – 1) / -0,5 .
Наступний код показує, як це зробити:
/*create new dataset that uses box-cox transformation to create new y*/
data new_data;
set my_data;
new_y = (y**(-0.5) - 1) / -0.5;
run ;
/*fit simple linear regression model using new response variable*/
proc reg data =new_data;
model new_y = x;
run ;
У Residual vs. На квантильному графіку результату цієї моделі ми бачимо, що залишки лежать набагато ближче вздовж прямої діагональної лінії:
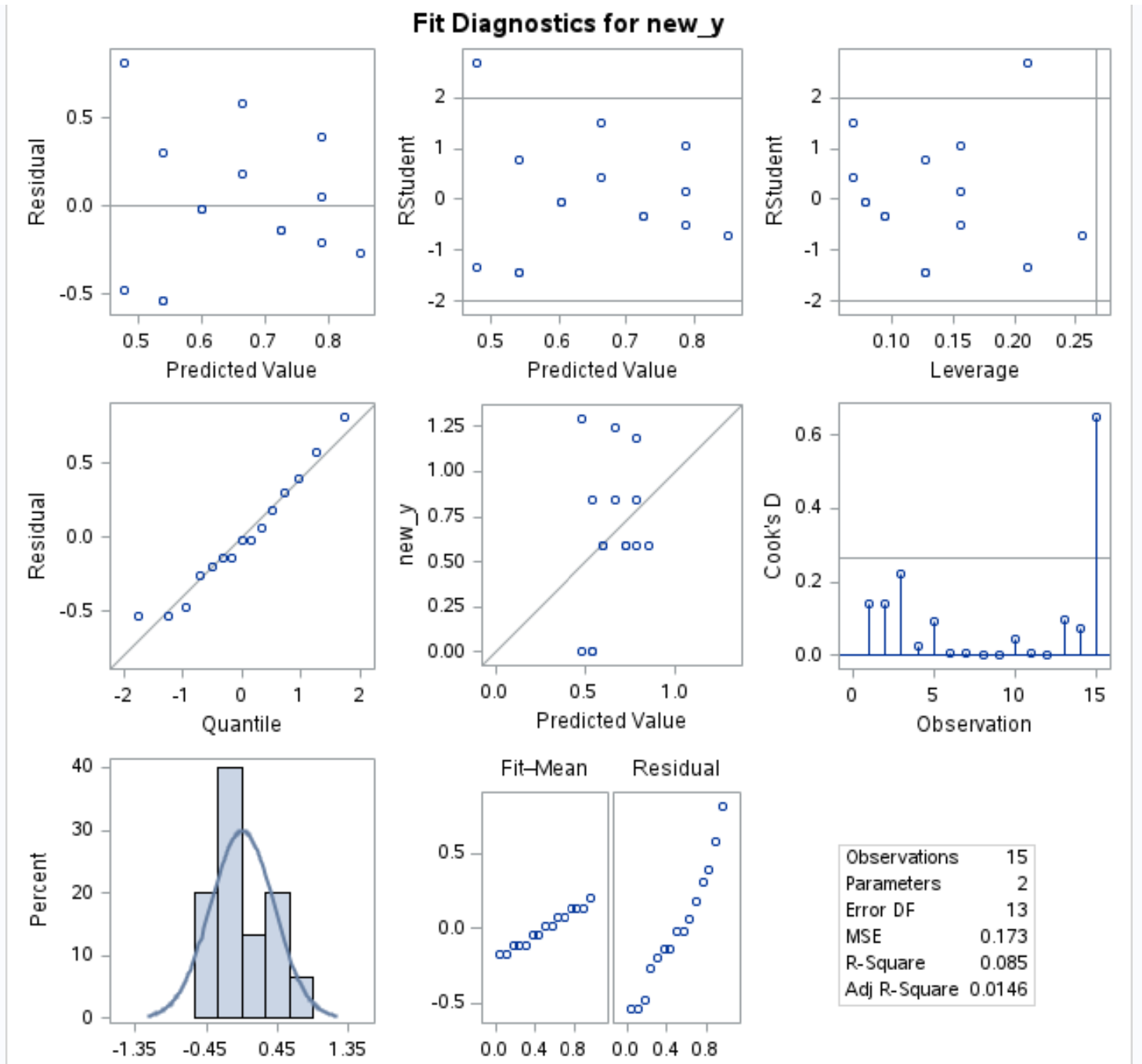
Це вказує на те, що залишки трансформованої моделі Бокса-Кокса розподілені набагато більш нормально, що задовольняє одне з основних припущень лінійної регресії .
Додаткові ресурси
У наступних посібниках пояснюється, як виконувати інші типові завдання в SAS:
Як використовувати Proc Univariate для перевірки нормальності в SAS
Як створити ділянку залишку в SAS
Як виконати тест Левена в SAS
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше