Як усунути тенденції даних: із прикладами
«Зняття тенденції» з даних часових рядів означає видалення основної тенденції в даних. Основна причина, чому ми хочемо це зробити, полягає в тому, щоб легше візуалізувати базові тенденції в даних, які є сезонними або циклічними.
Наприклад, розглянемо такі дані часового ряду, які представляють загальний обсяг продажів компанії за 20 послідовних періодів:
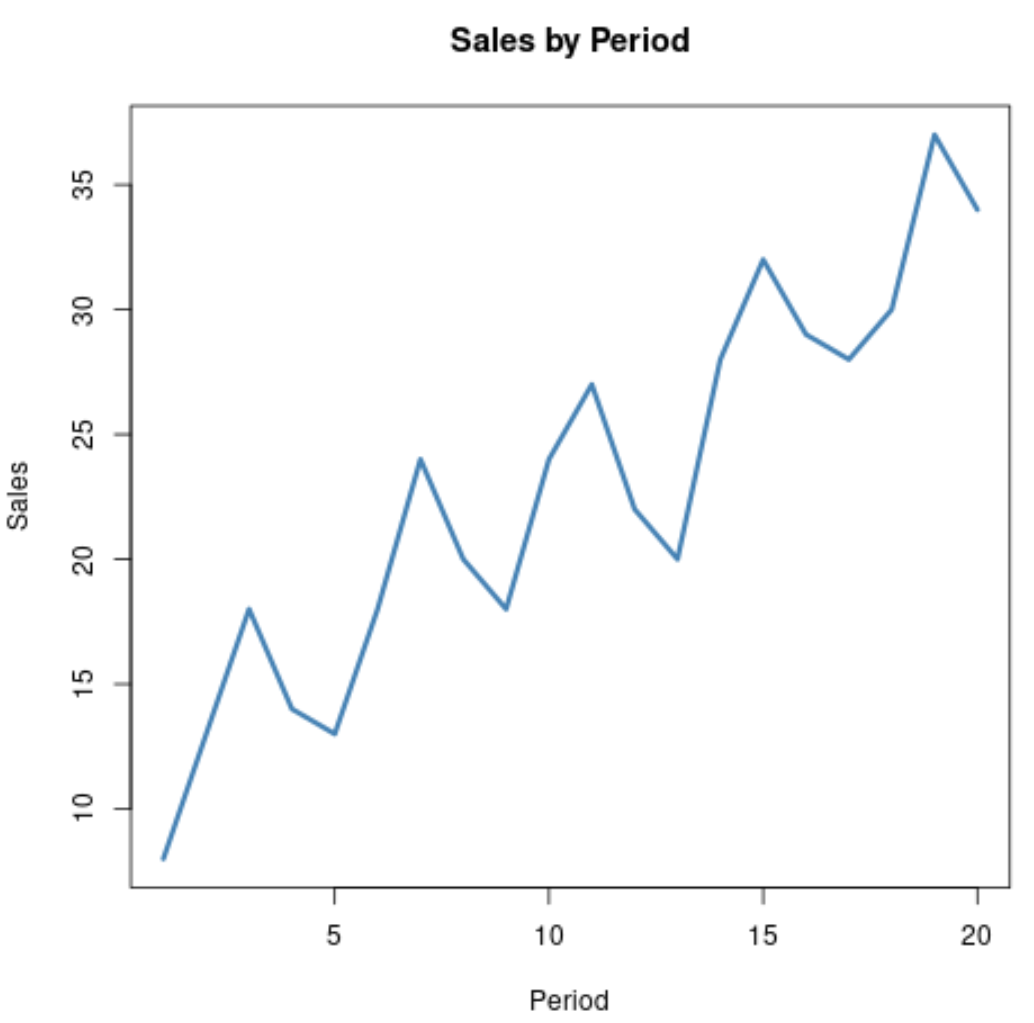
Очевидно, що продажі, як правило, збільшуються з часом, але, схоже, також існує циклічна або сезонна тенденція в даних, про що свідчать крихітні «пагорби», які виникають з часом.
Щоб отримати краще уявлення про цю циклічну тенденцію, ми можемо дефлювати дані. У цьому випадку це передбачає усунення загальної висхідної тенденції з часом, щоб отримані дані представляли лише циклічну тенденцію.
Є два поширених методи, які використовуються для дефляції даних часових рядів:
1. Схильність до диференціації
2. Деградація підгонкою моделі
Цей підручник містить коротке пояснення кожного методу.
Спосіб 1: Релаксація диференціюванням
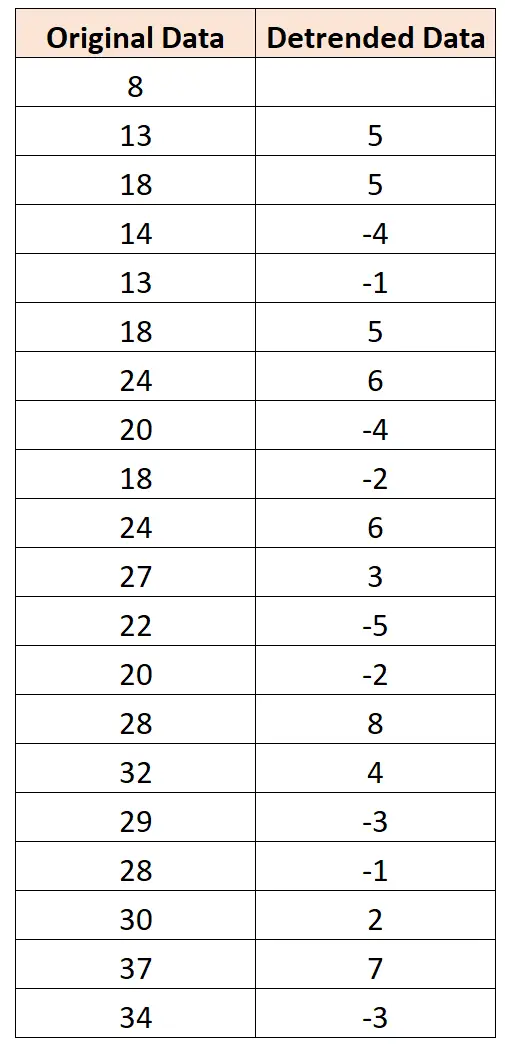
Один із способів усунути тенденції даних часових рядів — це просто створити новий набір даних, у якому кожне спостереження представляє різницю між собою та попереднім спостереженням.
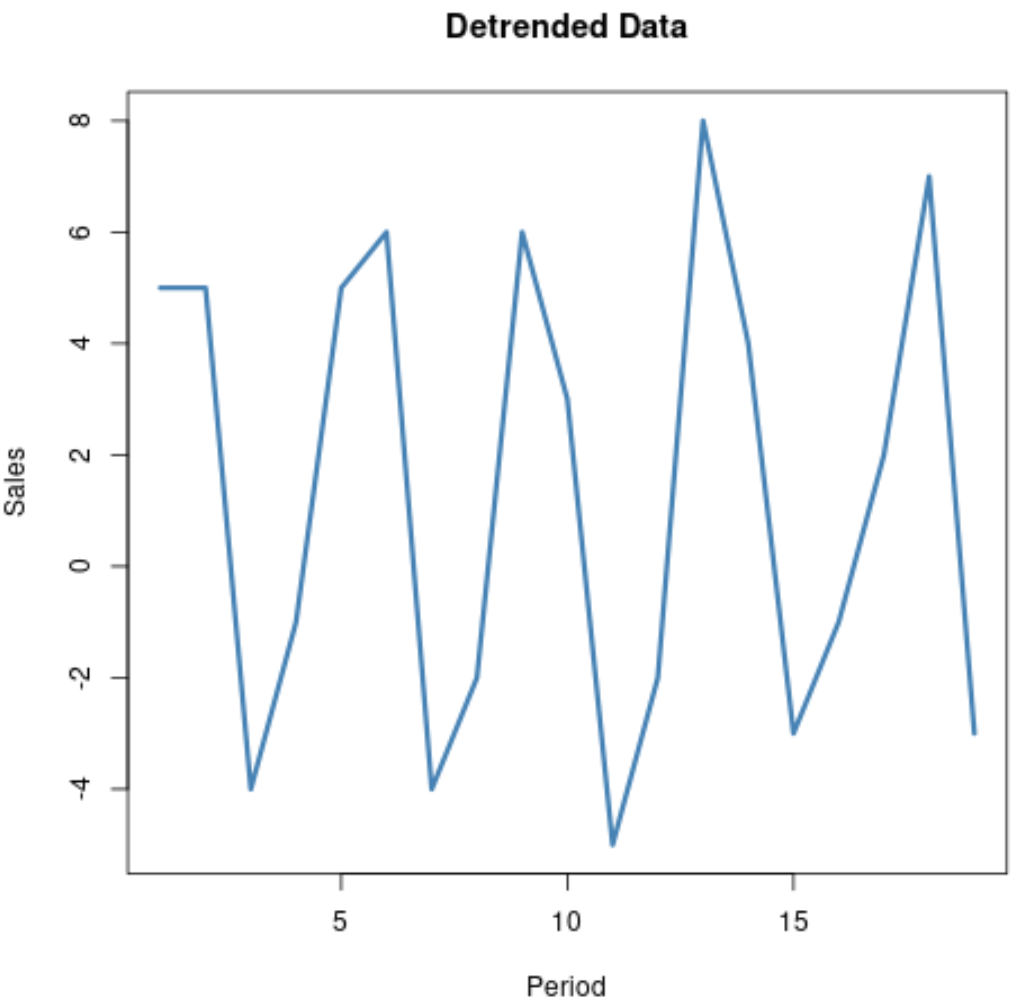
Наприклад, на наведеному нижче зображенні показано, як використовувати диференціювання для вилучення тренду з ряду даних.
Щоб отримати перше значення даних часових рядів з виключеним трендом, ми обчислюємо 13 – 8 = 5. Потім, щоб отримати наступне значення, ми обчислюємо 18-13 = 5 і так далі.
На наступній діаграмі показано вихідні дані часового ряду:
І ця діаграма показує дані без тенденції:
Зверніть увагу, наскільки простіше побачити сезонний тренд у даних часових рядів на цій діаграмі, оскільки загальний висхідний тренд було видалено.
Спосіб 2: Деградація шляхом підгонки моделі
Інший спосіб усунення тренду даних часових рядів — підібрати регресійну модель до даних, а потім обчислити різницю між спостережуваними значеннями та прогнозованими значеннями моделі.
Наприклад, припустімо, що ми маємо однаковий набір даних:

Якщо підібрати просту модель лінійної регресії до даних, ми зможемо отримати прогнозоване значення для кожного спостереження в наборі даних.
Потім ми можемо знайти різницю між фактичним значенням і прогнозованим значенням для кожного спостереження. Ці відмінності представляють дані без трендів.
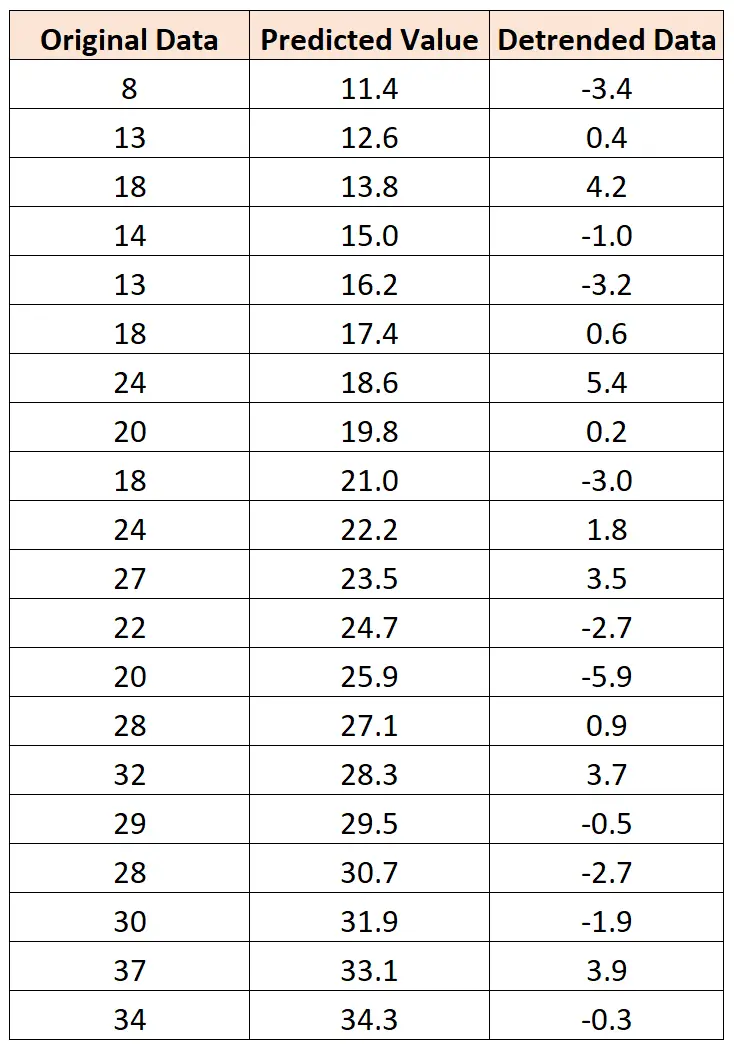
Якщо ми створимо графік даних без тенденції, ми зможемо набагато легше візуалізувати сезонний або циклічний тренд даних:
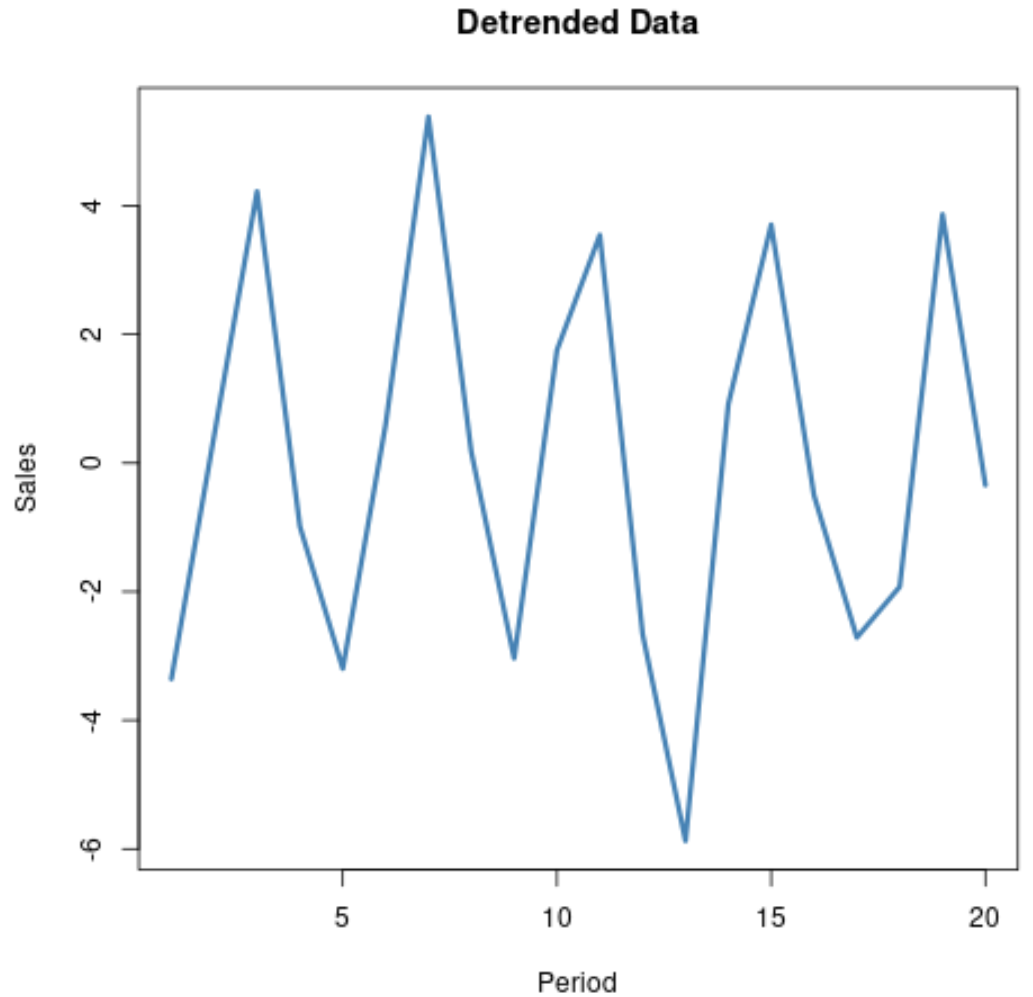
Зауважте, що в цьому прикладі ми використовували лінійну регресію, але можна використовувати більш складний метод, наприклад експоненціальну регресію, якщо в даних є більше експоненційної висхідної чи спадної тенденції.
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше