Як читати розподільну панель f
Цей підручник пояснює, як читати та інтерпретувати таблицю розподілу F.
Що таке таблиця розподілу F?
Таблиця розподілу F – це таблиця, яка показує критичні значення розподілу F. Щоб використовувати таблицю розподілу F, вам потрібні лише три значення:
- Ступені вільності чисельника
- Ступені свободи знаменника
- Альфа-рівень (звичайні варіанти: 0,01, 0,05 і 0,10)
У наступній таблиці показано таблицю розподілу F для альфа = 0,10. Числа у верхній частині таблиці представляють ступені свободи чисельника (позначеного в таблиці DF1 ), а числа в лівій частині таблиці представляють ступені свободи знаменника (позначеного в таблиці DF2 ).
Не соромтеся натискати на таблицю, щоб збільшити.
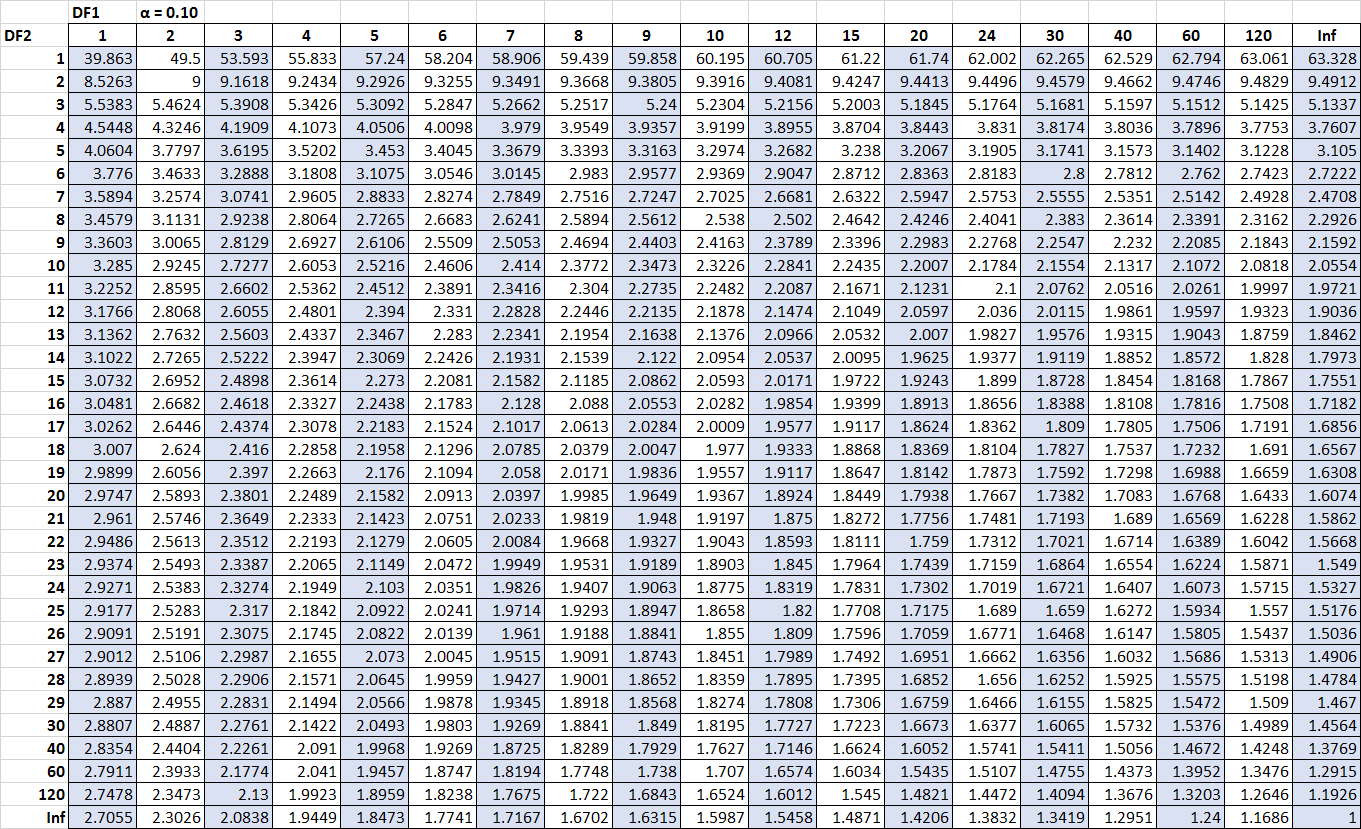
Критичні значення в таблиці часто порівнюють із F-статистикою F-тесту. Якщо F-статистика перевищує критичне значення в таблиці, ви можете відхилити нульову гіпотезу F-тесту та зробити висновок, що результати тесту є статистично значущими.
Приклади використання таблиці розподілу F
Таблиця F-розподілу використовується для визначення критичного значення для F-тесту. Три найпоширеніші сценарії, у яких ви будете виконувати тест F:
- F-тест у регресійному аналізі для перевірки загальної значущості регресійної моделі.
- F-тест у ANOVA (дисперсійний аналіз), щоб перевірити загальну різницю між груповими середніми.
- F-тест, щоб дізнатися, чи дві генеральні сукупності мають однакові дисперсії.
Розглянемо приклад використання таблиці розподілу F у кожному з цих сценаріїв.
F Тест у регресійному аналізі
Припустімо, ми виконуємо множинний лінійний регресійний аналіз, використовуючи навчальні години та складені підготовчі іспити як змінні прогностики та оцінку підсумкового іспиту як змінну відповіді. Коли ми виконуємо регресійний аналіз, ми отримуємо такий результат:
| Джерело | SS | df | РС. | Ф | П. |
|---|---|---|---|---|---|
| регресія | 546,53 | 2 | 273,26 | 5.09 | 0,033 |
| Залишковий | 483,13 | 9 | 53,68 | ||
| Всього | 1029,66 | 11 |
У регресійному аналізі f-статистика обчислюється як регресійна MS/залишкова MS. Ця статистика показує, чи регресійна модель забезпечує кращу відповідність даним, ніж модель, яка не містить незалежних змінних. По суті, він перевіряє, чи є регресійна модель у цілому корисною.
У цьому прикладі F-статистика дорівнює 273,26 / 53,68 = 5,09 .
Припустімо, ми хочемо знати, чи є ця F-статистика значущою на рівні альфа = 0,05. Використовуючи таблицю розподілу F для альфа = 0,05 із чисельником ступенів свободи 2 ( df для регресії) і знаменником ступенів свободи 9 ( df для залишку) , ми знаходимо, що критичне значення F дорівнює 4 2565 .
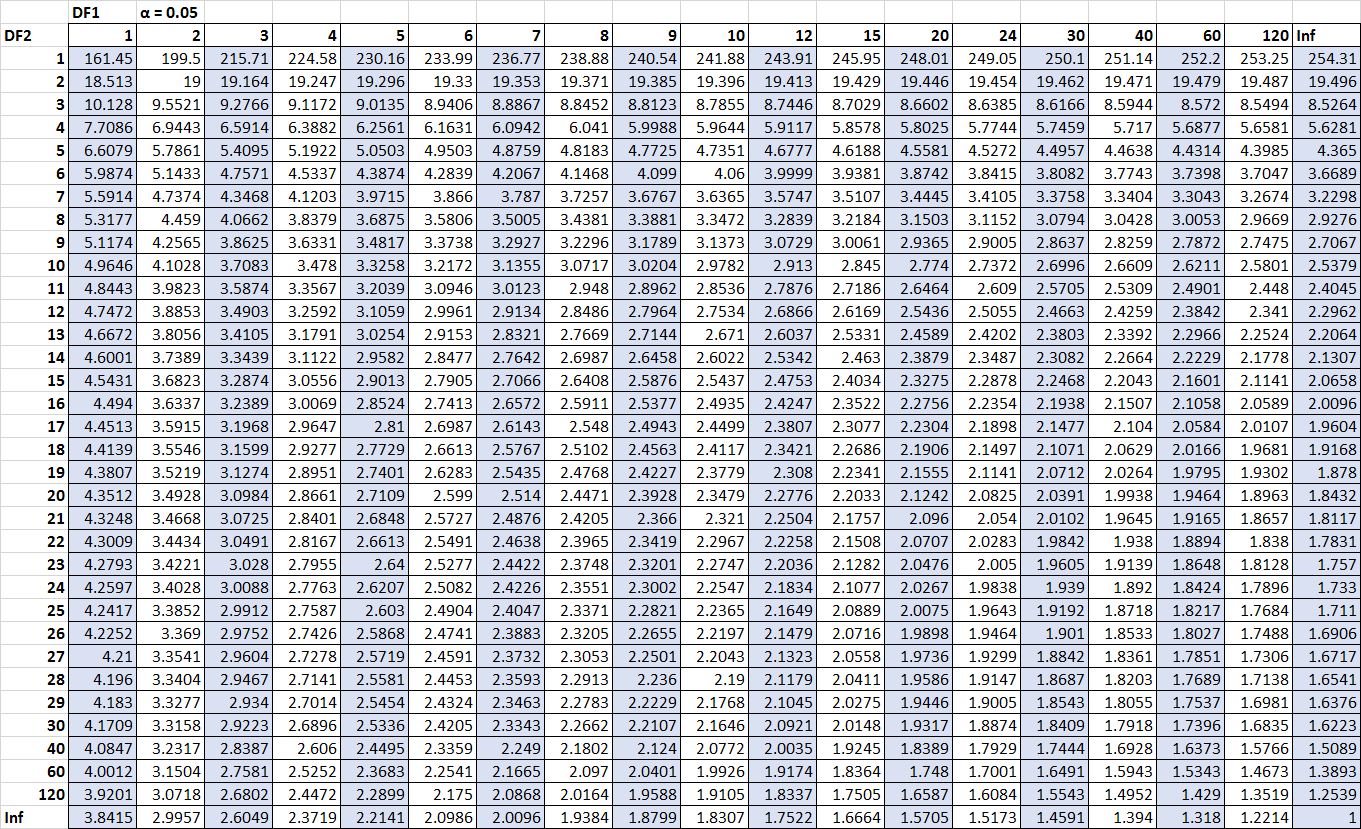
Оскільки наша статистика f( 5,09 ) більша за критичне значення F ( 4,2565) , ми можемо зробити висновок, що регресійна модель в цілому є статистично значущою.
F тест в ANOVA
Припустімо, ми хочемо знати, чи призводять три різні методи дослідження до різних результатів тесту. Щоб перевірити це, ми набираємо 60 студентів. Ми випадковим чином розподіляємо 20 студентів для використання однієї з трьох методів навчання протягом місяця для підготовки до іспиту. Коли всі студенти склали іспит, ми виконуємо односторонній дисперсійний аналіз , щоб визначити, чи впливає техніка навчання на результати іспиту. У наступній таблиці показано результати одностороннього дисперсійного аналізу:
| Джерело | SS | df | РС. | Ф | П. |
|---|---|---|---|---|---|
| Лікування | 58.8 | 2 | 29.4 | 1.74 | 0,217 |
| Помилка | 202.8 | 12 | 16.9 | ||
| Всього | 261,6 | 14 |
У дисперсійному аналізі f-статистика обчислюється як MS лікування/помилка MS. Ця статистика показує, чи є середній бал у трьох групах рівним чи ні.
У цьому прикладі F-статистика становить 29,4 / 16,9 = 1,74 .
Припустімо, ми хочемо знати, чи є ця F-статистика значущою на рівні альфа = 0,05. Використовуючи таблицю розподілу F для альфа = 0,05 із чисельником ступенів свободи 2 ( df для лікування) і знаменником ступенів свободи 12 ( df для помилки) , ми знаходимо, що критичне значення F становить 38853 .
Оскільки наша статистика f ( 1,74 ) не перевищує критичне значення F ( 3,8853) , ми робимо висновок, що немає статистично значущої різниці між середніми балами трьох груп.
F-тест для однакових дисперсій двох сукупностей
Припустімо, ми хочемо знати, чи рівні дисперсії двох сукупностей чи ні. Щоб перевірити це, ми можемо виконати F-тест для однакових дисперсій, у якому ми беремо випадкову вибірку з 25 спостережень із кожної сукупності та знаходимо дисперсію вибірки для кожної вибірки.
Статистика тесту для цього F-тесту визначається наступним чином:
Статистика F = s 1 2 / s 2 2
де s 1 2 і s 2 2 – вибіркові дисперсії. Чим далі це співвідношення від одиниці, тим сильніші докази нерівних дисперсій у сукупності.
Критичне значення критерію F визначається таким чином:
Критичне значення F = значення, знайдене в таблиці розподілу F з n 1 -1 і n 2 -1 ступенями свободи та рівнем значущості α.
Припустимо, дисперсія вибірки для зразка 1 становить 30,5, а дисперсія вибірки для зразка 2 становить 20,5. Це означає, що наша тестова статистика становить 30,5/20,5 = 1,487 . Щоб з’ясувати, чи є ця тестова статистика значущою при альфа = 0,10, ми можемо знайти критичне значення в таблиці розподілу F, пов’язане з альфа = 0,10, чисельником df = 24 і знаменником df = 24. Це число виявляється рівним 1,7019. .
Оскільки наша статистика f( 1,487 ) не перевищує критичне значення F( 1,7019) , ми робимо висновок, що немає статистично значущої різниці між дисперсіями цих двох сукупностей.
Додаткові ресурси
Щоб отримати повний набір таблиць розподілу F для альфа-значень 0,001, 0,01, 0,025, 0,05 і 0,10, перегляньте цю сторінку .
Про автора
Редакція
Привіт, я Бенджамін, професор статистики на пенсії, який став викладачем статистики. Маючи великий досвід і знання в галузі статистики, я готовий поділитися своїми знаннями, щоб розширити можливості студентів через Statorials. Дізнайтеся більше