
Comment calculer la distance du cuisinier dans SAS
La distance de Cook est utilisée pour identifier les observations influentes dans un modèle de régression.
La formule de la distance de Cook est la suivante :
ré je = (r je 2 / p*MSE) * (h ii / (1-h ii ) 2 )
où:
- r i est le i ème résidu
- p est le nombre de coefficients dans le modèle de régression
- MSE est l’erreur quadratique moyenne
- h ii est la ième valeur de levier
Essentiellement, la distance de Cook mesure dans quelle mesure toutes les valeurs ajustées du modèle changent lorsque la i ème observation est supprimée.
Plus la valeur de la distance de Cook est grande, plus une observation donnée est influente.
En règle générale, toute observation avec une distance de Cook supérieure à 4/n (où n = observations totales) est considérée comme ayant une grande influence.
L’exemple suivant montre comment calculer la distance de Cook pour chaque observation dans un modèle de régression dans SAS.
Exemple : calcul de la distance du cuisinier dans SAS
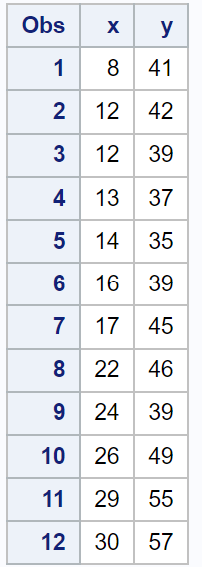
Supposons que nous ayons l’ensemble de données suivant dans SAS :
/*create dataset*/
data my_data;
input x y;
datalines;
8 41
12 42
12 39
13 37
14 35
16 39
17 45
22 46
24 39
26 49
29 55
30 57
;
run;
/*view dataset*/
proc print data=my_data;
Nous pouvons utiliser PROC REG pour ajuster un modèle de régression linéaire simple à cet ensemble de données, puis utiliser l’instruction OUTPUT avec l’instruction COOKD pour calculer la distance de Cook pour chaque observation dans le modèle de régression :
/*fit simple linear regression model and calculate Cook's distance for each obs*/
proc reg data=my_data;
model y=x;
output out=cooksData cookd=cookd;
run;
/*print Cook's distance values for each observation*/
proc print data=cooksData;
Le tableau final du résultat affiche l’ensemble de données d’origine ainsi que la distance de Cook pour chaque observation :
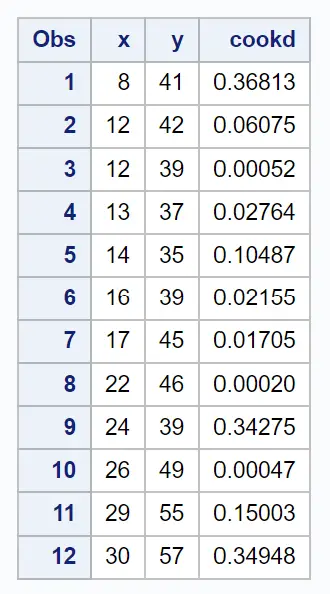
Par exemple, on peut voir :
- La distance de Cook pour la première observation est de 0,36813 .
- La distance de Cook pour la deuxième observation est de 0,06075 .
- La distance de Cook pour la troisième observation est 0,00052 .
Et ainsi de suite.
La procédure PROC REG produit également plusieurs tracés de diagnostic dans la sortie et le graphique de la distance de Cook peut être vu dans cette sortie :
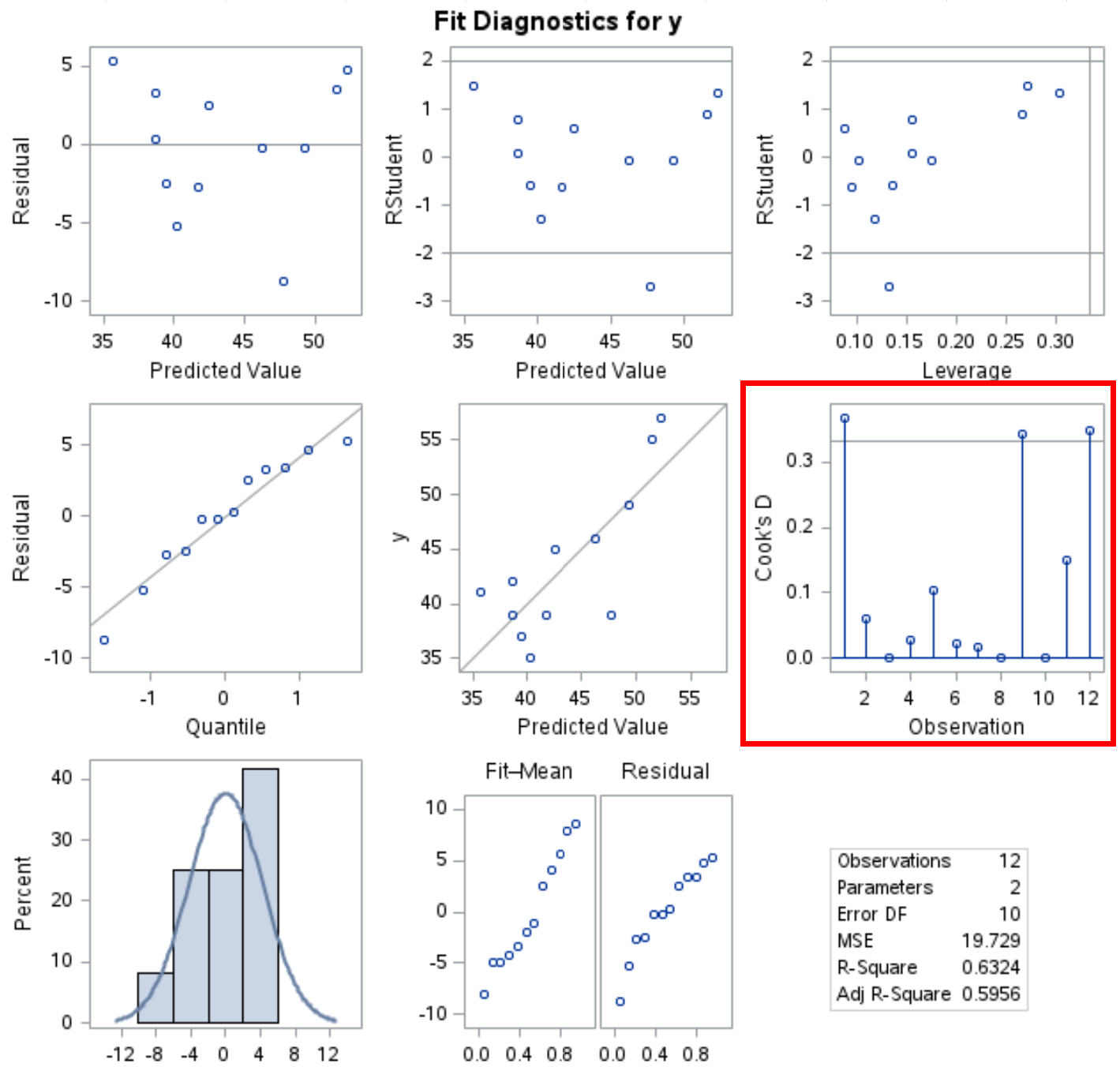
L’axe des x montre le numéro d’observation et l’axe des y montre la distance de Cook pour chaque observation.
Notez qu’une ligne de coupure est placée à 4/n (dans ce cas n = 12, donc la coupure est à 0,33) et nous pouvons voir que trois observations dans l’ensemble de données sont supérieures à cette ligne.
Cela indique que ces observations pourraient avoir une grande influence sur le modèle de régression et devraient peut-être être examinées de plus près avant d’interpréter les résultats du modèle.
Ressources additionnelles
Les didacticiels suivants expliquent comment effectuer d’autres tâches courantes dans SAS :
Comment créer un tracé résiduel dans SAS
Comment créer des histogrammes dans SAS
Comment créer des nuages de points dans SAS
Comment identifier les valeurs aberrantes dans SAS
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus