
Comment lire des lignes spécifiques d’un fichier CSV dans R
Vous pouvez utiliser les méthodes suivantes pour lire des lignes spécifiques d’un fichier CSV dans R :
Méthode 1 : importer un fichier CSV à partir d’une ligne spécifique
df <- read.csv("my_data.csv", skip=2)
Cet exemple particulier ignorera les deux premières lignes du fichier CSV et importera toutes les autres lignes du fichier en commençant par la troisième ligne.
Méthode 2 : Importer un fichier CSV où les lignes remplissent la condition
library(sqldf) df <- read.csv.sql("my_data.csv", sql = "select * from file where `points` > 90", eol = "\n")
Cet exemple particulier importera uniquement les lignes du fichier CSV dont la valeur dans la colonne « points » est supérieure à 90.
Les exemples suivants montrent comment utiliser chacune de ces méthodes en pratique avec le fichier CSV suivant appelé my_data.csv :
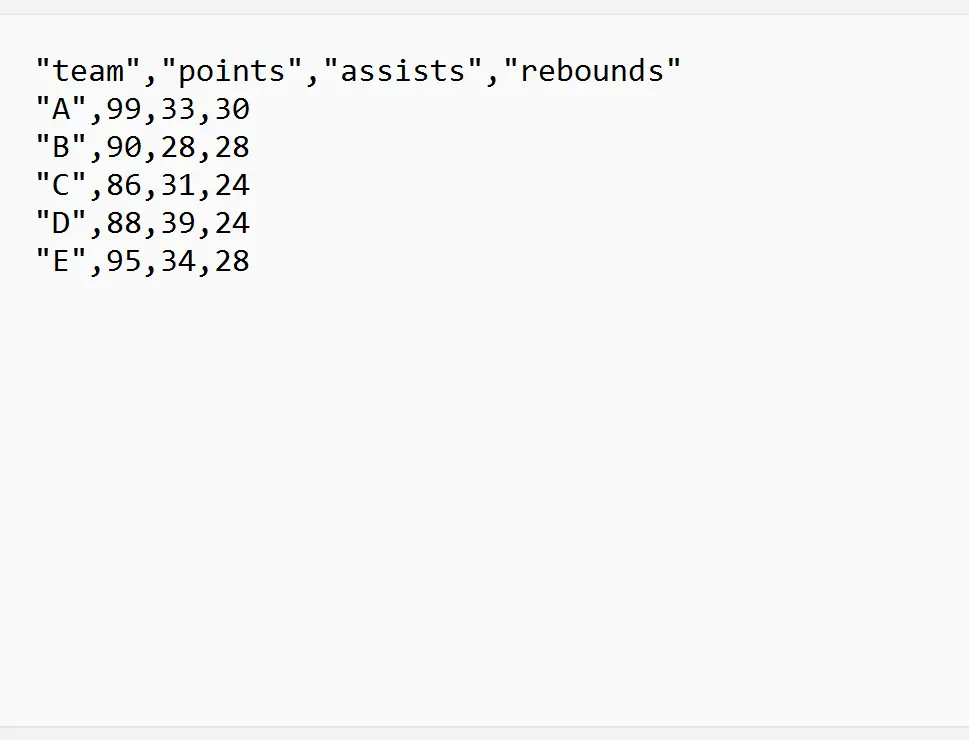
Exemple 1 : Importer un fichier CSV à partir d’une ligne spécifique
Le code suivant montre comment importer le fichier CSV et ignorer les deux premières lignes du fichier :
#import data frame and skip first two rows
df <- read.csv('my_data.csv', skip=2)
#view data frame
df
B X90 X28 X28.1
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
Notez que les deux premières lignes (avec les équipes A et B) ont été ignorées lors de l’importation du fichier CSV.
Par défaut, R tente d’utiliser les valeurs de la prochaine ligne disponible comme noms de colonne.
Pour renommer les colonnes, vous pouvez utiliser la fonction names() comme suit :
#rename columns
names(df) <- c('team', 'points', 'assists', 'rebounds')
#view updated data frame
df
team points assists rebounds
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
Exemple 2 : Importer un fichier CSV où les lignes remplissent la condition
Supposons que nous souhaitions importer uniquement les lignes du fichier CSV dont la valeur dans la colonne de points est supérieure à 90.
Nous pouvons utiliser la fonction read.csv.sql du package sqldf pour ce faire :
library(sqldf)
#only import rows where points > 90
df <- read.csv.sql("my_data.csv",
sql = "select * from file where `points` > 90", eol = "\n")
#view data frame
df
team points assists rebounds
1 "A" 99 33 30
2 "E" 95 34 28
Notez que seules les deux lignes du fichier CSV dont la valeur dans la colonne « points » est supérieure à 90 ont été importées.
Note #1 : Dans cet exemple, nous avons utilisé l’argument eol pour spécifier que la « fin de ligne » dans le fichier est indiquée par \n , qui représente un saut de ligne.
Remarque n°2 : dans cet exemple, nous avons utilisé une simple requête SQL, mais vous pouvez écrire des requêtes plus complexes pour filtrer les lignes selon encore plus de conditions.
Ressources additionnelles
Les didacticiels suivants expliquent comment effectuer d’autres tâches courantes dans R :
Comment lire un CSV à partir d’une URL dans R
Comment fusionner plusieurs fichiers CSV dans R
Comment exporter un bloc de données vers un fichier CSV dans R
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus