
Comment interpoler les valeurs manquantes dans R (y compris un exemple)
Vous pouvez utiliser la syntaxe de base suivante pour interpoler les valeurs manquantes dans une colonne de bloc de données dans R :
library(dplyr) library(zoo) df <- df %>% mutate(column_name = na.approx(column_name))
L’exemple suivant montre comment utiliser cette syntaxe dans la pratique.
Exemple : interpoler les valeurs manquantes dans R
Supposons que nous ayons le bloc de données suivant dans R qui montre les ventes totales réalisées par un magasin pendant 15 jours consécutifs :
#create data frame df <- data.frame(day=1:15, sales=c(3, 6, 8, 10, 14, 17, 20, NA, NA, NA, NA, 35, 39, 44, 49)) #view data frame df day sales 1 1 3 2 2 6 3 3 8 4 4 10 5 5 14 6 6 17 7 7 20 8 8 NA 9 9 NA 10 10 NA 11 11 NA 12 12 35 13 13 39 14 14 44 15 15 49
Notez qu’il nous manque des chiffres de ventes pour quatre jours dans le bloc de données.
Si nous créons un simple graphique linéaire pour visualiser les ventes au fil du temps, voici à quoi cela ressemblerait :
#create line chart to visualize sales plot(df$sales, type='o', pch=16, col='steelblue', xlab='Day', ylab='Sales')
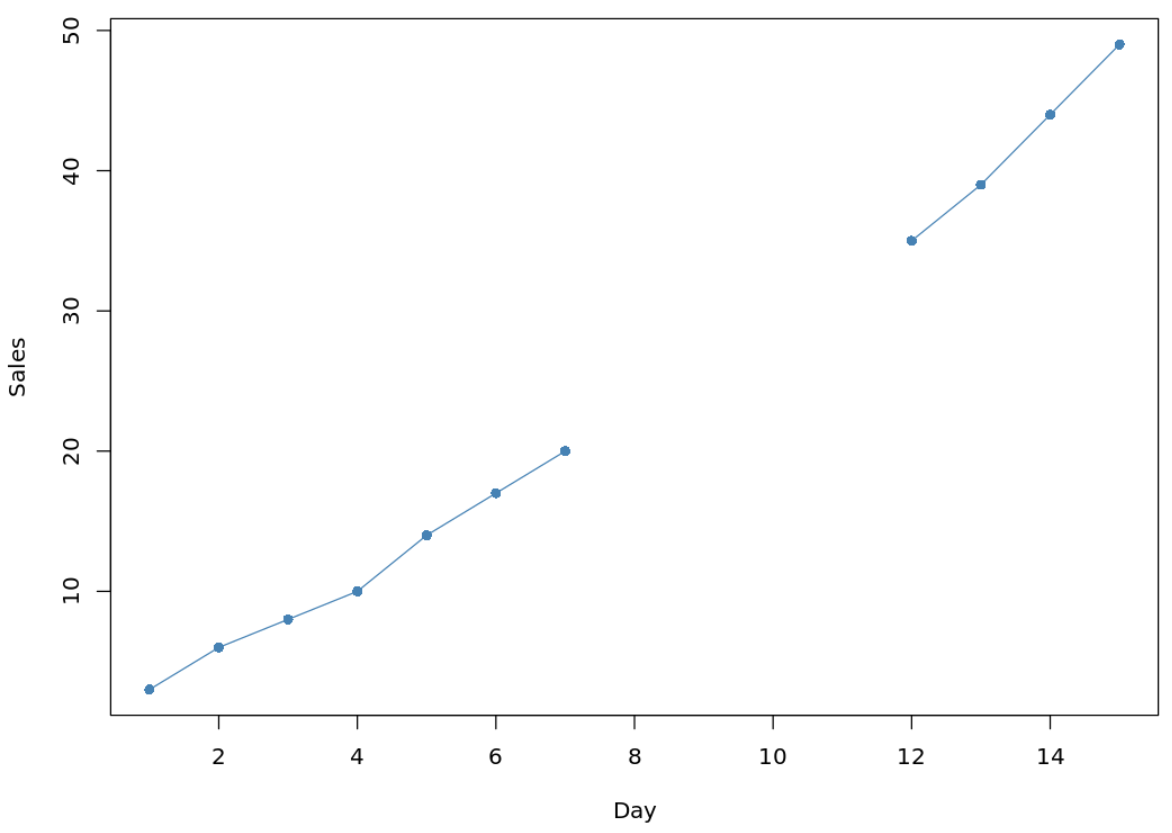
Pour remplir les valeurs manquantes, nous pouvons utiliser la fonction na.approx() du package zoo ainsi que la fonction mutate() du package dplyr :
library(dplyr) library(zoo) #interpolate missing values in 'sales' column df <- df %>% mutate(sales = na.approx(sales)) #view updated data frame df day sales 1 1 3 2 2 6 3 3 8 4 4 10 5 5 14 6 6 17 7 7 20 8 8 23 9 9 26 10 10 29 11 11 32 12 12 35 13 13 39 14 14 44 15 15 49
Notez que chacune des valeurs manquantes a été remplacée.
Si nous créons un autre graphique linéaire pour visualiser le bloc de données mis à jour, voici à quoi il ressemblerait :
#create line chart to visualize sales plot(df$sales, type='o', pch=16, col='steelblue', xlab='Day', ylab='Sales')
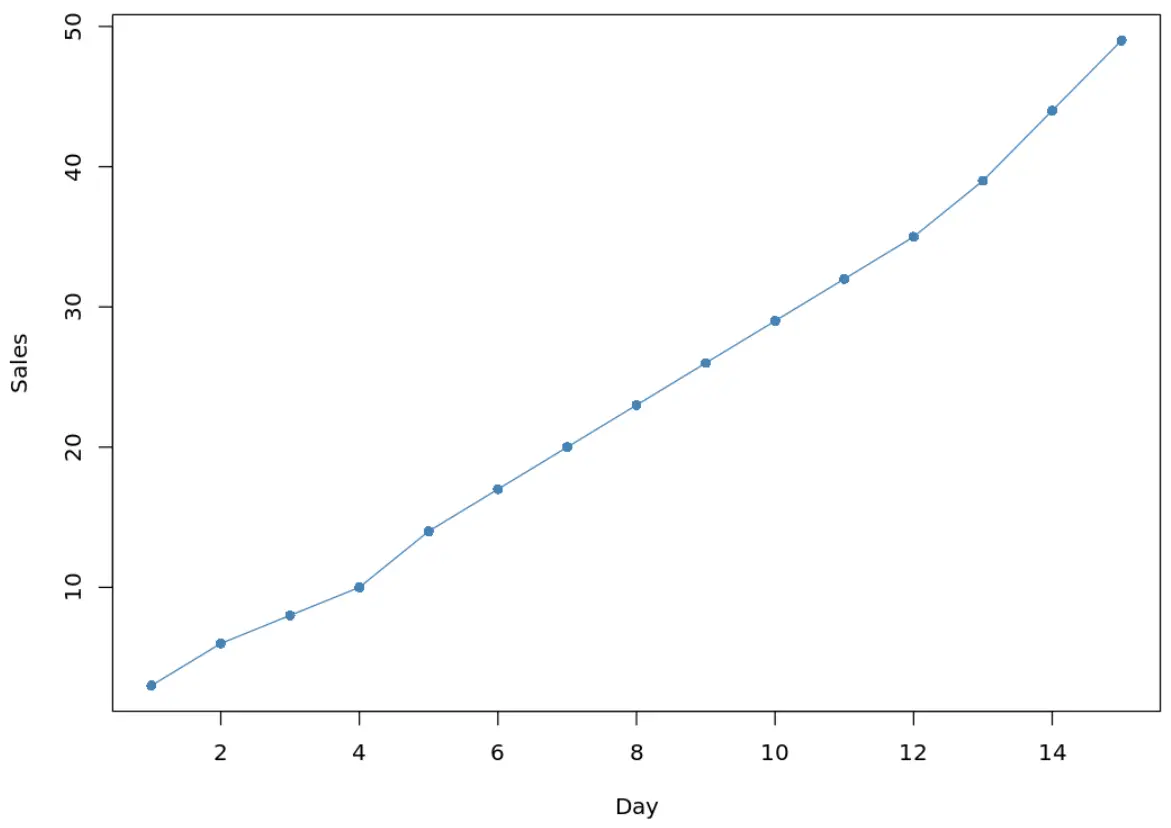
Notez que les valeurs choisies par la fonction na.approx() semblent assez bien correspondre à la tendance des données.
Ressources additionnelles
Les didacticiels suivants fournissent des informations supplémentaires sur la façon de gérer les valeurs manquantes dans R :
Comment rechercher et compter les valeurs manquantes dans R
Comment imputer les valeurs manquantes dans R
Comment utiliser la fonction is.na dans R
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus