
Comment effectuer un test Chow en Python
Un test de Chow est utilisé pour tester si les coefficients de deux modèles de régression différents sur différents ensembles de données sont égaux.
Ce test est généralement utilisé dans le domaine de l’économétrie avec des données de séries chronologiques pour déterminer s’il existe une rupture structurelle dans les données à un moment donné.
L’exemple suivant, étape par étape, montre comment effectuer un test Chow en Python.
Étape 1 : Créer les données
Tout d’abord, nous allons créer de fausses données :
import pandas as pd #create DataFrame df = pd.DataFrame({'x': [1, 1, 2, 3, 4, 4, 5, 5, 6, 7, 7, 8, 8, 9, 10, 10, 11, 12, 12, 13, 14, 15, 15, 16, 17, 18, 18, 19, 20, 20], 'y': [3, 5, 6, 10, 13, 15, 17, 14, 20, 23, 25, 27, 30, 30, 31, 33, 32, 32, 30, 32, 34, 34, 37, 35, 34, 36, 34, 37, 38, 36]}) #view first five rows of DataFrame df.head() x y 0 1 3 1 1 5 2 2 6 3 3 10 4 4 13
Étape 2 : Visualisez les données
Ensuite, nous allons créer un nuage de points simple pour visualiser les données :
import matplotlib.pyplot as plt
#create scatterplot
plt.plot(df.x, df.y, 'o')
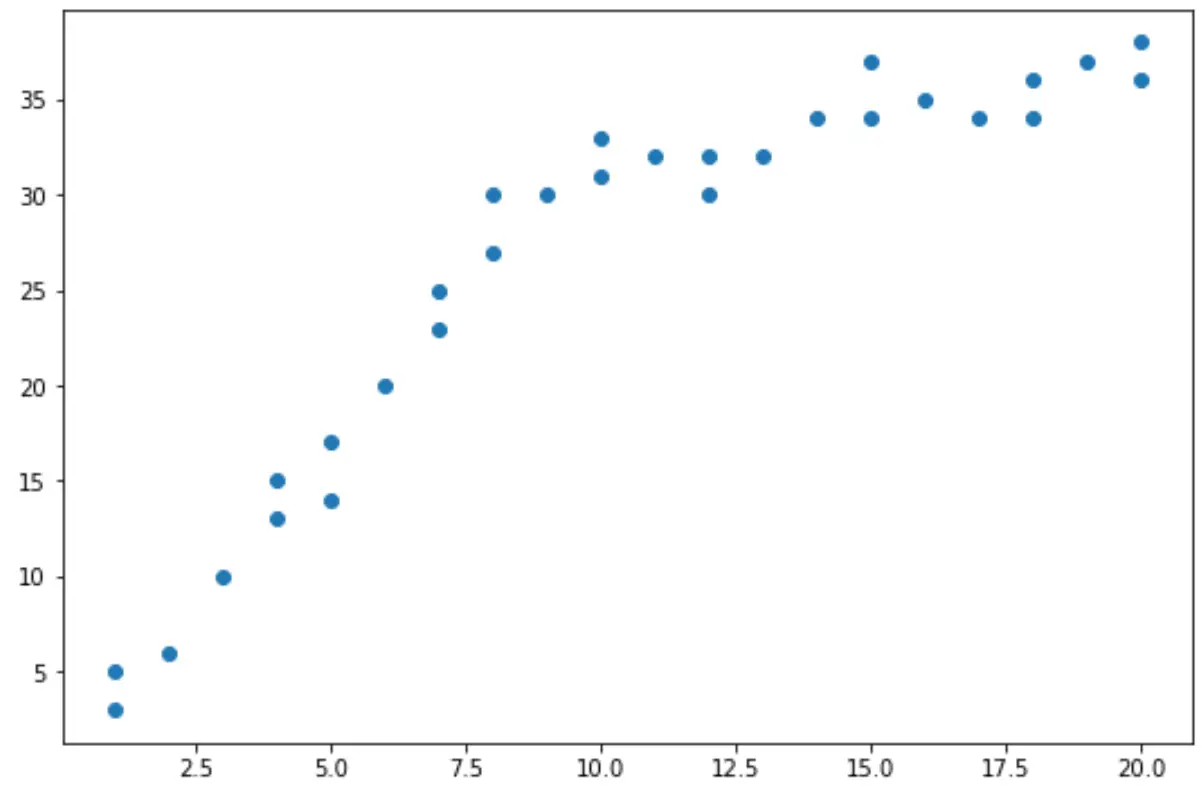
À partir du nuage de points, nous pouvons voir que la tendance dans les données semble changer à x = 10.
Ainsi, nous pouvons effectuer le test de Chow pour déterminer s’il existe un point de rupture structurelle dans les données à x = 10.
Étape 3 : Effectuer le test Chow
Nous pouvons utiliser la fonction chowtest du package chowtest en Python pour effectuer un test Chow.
Tout d’abord, nous devons installer ce package en utilisant pip :
pip install chowtest
Ensuite, nous pouvons utiliser la syntaxe suivante pour effectuer le test Chow :
from chow_test import chowtest chowtest(y=df[['y']], X=df[['x']], last_index_in_model_1=15, first_index_in_model_2=16, significance_level=.05) *********************************************************************************** Reject the null hypothesis of equality of regression coefficients in the 2 periods. *********************************************************************************** Chow Statistic: 118.14097335479373 p value: 0.0 *********************************************************************************** (118.14097335479373, 1.1102230246251565e-16)
Voici ce que signifient les arguments individuels dans la fonction chowtest() :
- y : La variable de réponse dans le DataFrame
- x : La variable prédictive dans le DataFrame
- last_index_in_model_1 : La valeur de l’indice du dernier point avant la rupture structurelle
- first_index_in_model_2 : La valeur de l’indice pour le premier point après la rupture structurelle
- significativité_level : Le niveau de signification à utiliser pour le test d’hypothèse
À partir du résultat du test, nous pouvons voir :
- Statistique du test F : 118,14
- Valeur p : <.0000
Puisque la valeur p est inférieure à 0,05, nous pouvons rejeter l’hypothèse nulle du test. Cela signifie que nous disposons de suffisamment de preuves pour affirmer qu’un point de rupture structurelle est présent dans les données.
En d’autres termes, deux droites de régression peuvent adapter le modèle dans les données plus efficacement qu’une seule droite de régression.
Ressources additionnelles
Les didacticiels suivants expliquent comment effectuer d’autres tests courants en Python :
Comment effectuer un test de causalité Granger en Python
Comment effectuer un test Breusch-Pagan en Python
Comment effectuer le test de White en Python
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus