
Comment effectuer un encodage One-Hot en Python
L’encodage à chaud est utilisé pour convertir des variables catégorielles dans un format pouvant être facilement utilisé par les algorithmes d’apprentissage automatique .
L’idée de base du codage one-hot est de créer de nouvelles variables qui prennent les valeurs 0 et 1 pour représenter les valeurs catégorielles d’origine.
Par exemple, l’image suivante montre comment nous effectuerions un codage à chaud pour convertir une variable catégorielle contenant des noms d’équipe en de nouvelles variables contenant uniquement des valeurs 0 et 1 :
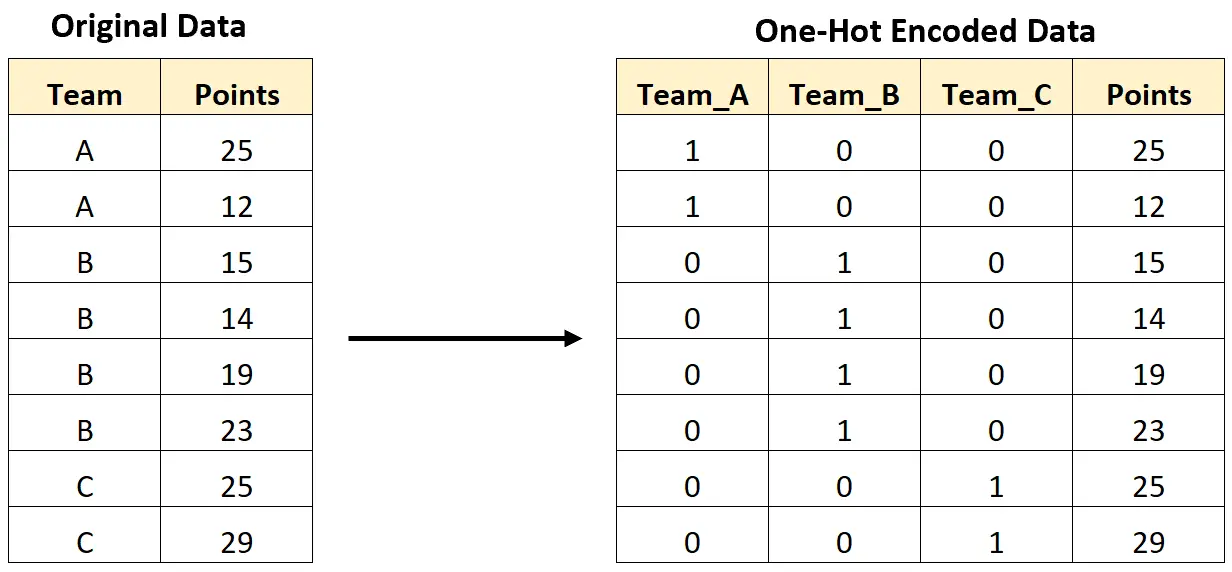
L’exemple étape par étape suivant montre comment effectuer un encodage à chaud pour cet ensemble de données exact en Python.
Étape 1 : Créer les données
Tout d’abord, créons le DataFrame pandas suivant :
import pandas as pd #create DataFrame df = pd.DataFrame({'team': ['A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'], 'points': [25, 12, 15, 14, 19, 23, 25, 29]}) #view DataFrame print(df) team points 0 A 25 1 A 12 2 B 15 3 B 14 4 B 19 5 B 23 6 C 25 7 C 29
Étape 2 : Effectuer un encodage à chaud
Ensuite, importons la fonction OneHotEncoder() depuis la bibliothèque sklearn et utilisons-la pour effectuer un encodage à chaud sur la variable ‘team’ dans le DataFrame pandas :
from sklearn.preprocessing import OneHotEncoder #creating instance of one-hot-encoder encoder = OneHotEncoder(handle_unknown='ignore') #perform one-hot encoding on 'team' column encoder_df = pd.DataFrame(encoder.fit_transform(df[['team']]).toarray()) #merge one-hot encoded columns back with original DataFrame final_df = df.join(encoder_df) #view final df print(final_df) team points 0 1 2 0 A 25 1.0 0.0 0.0 1 A 12 1.0 0.0 0.0 2 B 15 0.0 1.0 0.0 3 B 14 0.0 1.0 0.0 4 B 19 0.0 1.0 0.0 5 B 23 0.0 1.0 0.0 6 C 25 0.0 0.0 1.0 7 C 29 0.0 0.0 1.0
Notez que trois nouvelles colonnes ont été ajoutées au DataFrame puisque la colonne « équipe » d’origine contenait trois valeurs uniques.
Remarque : Vous pouvez trouver la documentation complète de la fonction OneHotEncoder() ici .
Étape 3 : Supprimez la variable catégorielle d’origine
Enfin, nous pouvons supprimer la variable ‘team’ d’origine du DataFrame puisque nous n’en avons plus besoin :
#drop 'team' column final_df.drop('team', axis=1, inplace=True) #view final df print(final_df) points 0 1 2 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
Connexe : Comment supprimer des colonnes dans Pandas (4 méthodes)
On pourrait également renommer les colonnes du DataFrame final pour les rendre plus faciles à lire :
#rename columns final_df.columns = ['points', 'teamA', 'teamB', 'teamC'] #view final df print(final_df) points teamA teamB teamC 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
L’encodage à chaud est terminé et nous pouvons maintenant insérer ce DataFrame pandas dans n’importe quel algorithme d’apprentissage automatique que nous souhaitons.
Ressources additionnelles
Comment calculer une moyenne tronquée en Python
Comment effectuer une régression linéaire en Python
Comment effectuer une régression logistique en Python
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus