
Qu’est-ce qu’une observation influente en statistique ?
En statistiques, une observation influente est une observation dans un ensemble de données qui, une fois supprimée, modifie considérablement les estimations des coefficients d’un modèle de régression.
La manière la plus courante de mesurer l’influence des observations consiste à utiliser la distance de Cook , qui quantifie l’ampleur de la modification de toutes les valeurs ajustées dans un modèle de régression lorsque la i ème observation est supprimée.
En règle générale, toute observation avec une distance de Cook supérieure à 1 est considérée comme une observation à fort effet de levier.
L’exemple suivant montre comment calculer et interpréter la distance de Cook pour un ensemble de données donné afin de détecter des observations influentes potentielles.
Exemple : Détection d’observations influentes
Supposons que nous ayons l’ensemble de données suivant avec 14 valeurs :
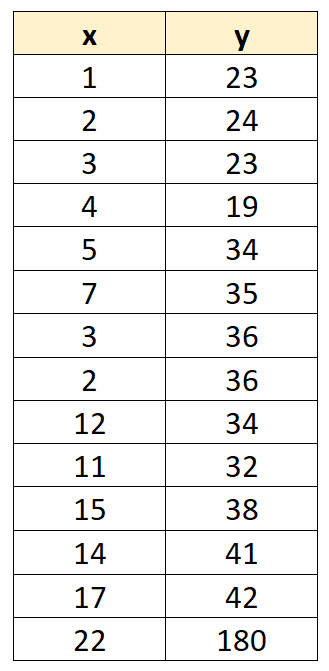
Supposons maintenant que nous ajustions un modèle de régression linéaire simple . Le résultat de la régression est présenté ci-dessous :

À l’aide d’un logiciel statistique, nous pouvons calculer les valeurs suivantes pour la distance de Cook pour chaque observation :
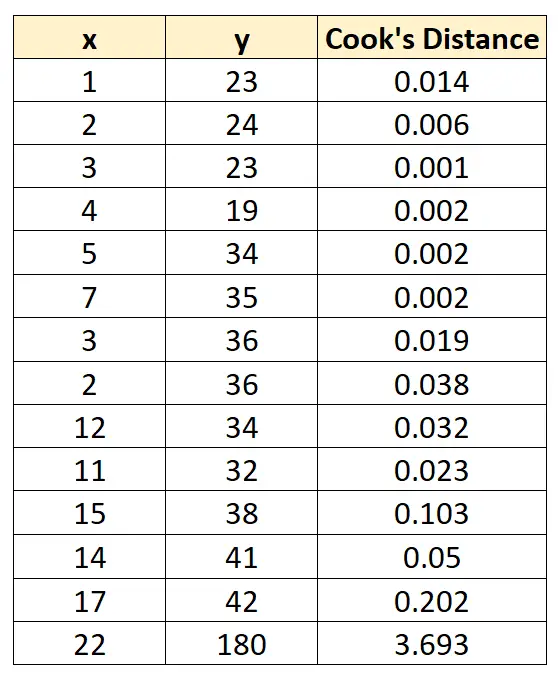
Notez que la dernière observation a une valeur nettement supérieure à 1 pour la distance de Cook, ce qui nous indique qu’il s’agit d’une observation influente.
Supposons que nous supprimions cette valeur de l’ensemble de données et ajustions un nouveau modèle de régression linéaire simple. La sortie de ce modèle est présentée ci-dessous :

Notez que les coefficients de régression pour l’ordonnée à l’origine et x ont tous deux radicalement changé. Cela nous indique que la suppression de l’observation influente de l’ensemble de données a complètement modifié le modèle de régression ajusté.
Les graphiques suivants montrent la différence entre ces deux équations de régression ajustées :
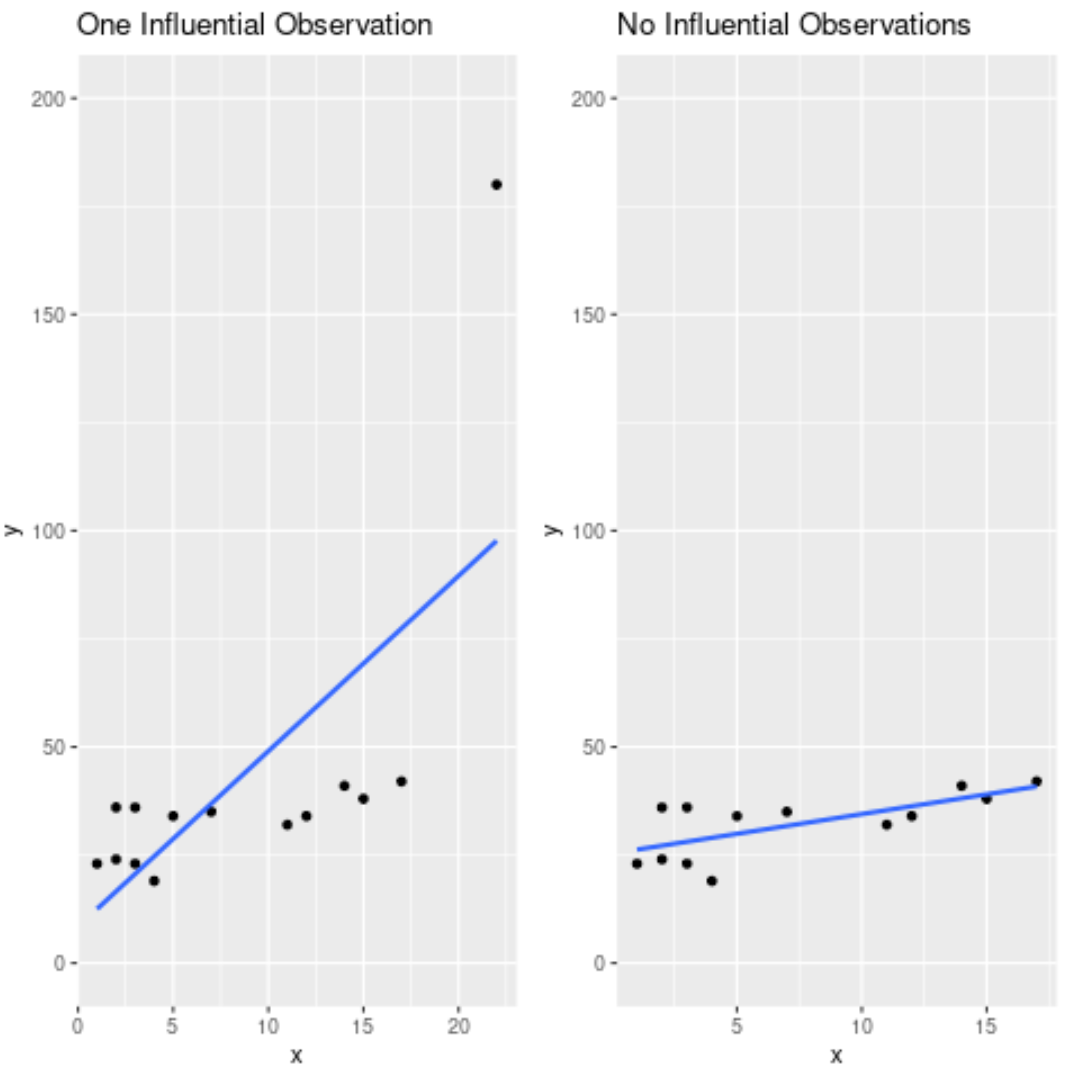
Remarquez à quel point la seule observation influente modifie la droite de régression. En supprimant cette observation, nous avons pu trouver une droite de régression qui correspond beaucoup plus étroitement aux données.
Remarques
Il est important de noter que la distance de Cook doit être utilisée pour identifier les observations potentiellement influentes. Cependant, ce n’est pas parce qu’une observation est influente qu’elle doit nécessairement être supprimée de l’ensemble de données.
Tout d’abord, vous devez vérifier que l’observation n’est pas le résultat d’une erreur de saisie de données ou d’un autre événement étrange. S’il s’avère qu’il s’agit d’une valeur légitime, vous pouvez alors décider de la traiter de l’une des manières suivantes :
- Supprimez-le de l’ensemble de données.
- Laissez-le dans l’ensemble de données.
- Remplacez-le par une valeur alternative comme la moyenne ou la médiane.
Selon votre scénario spécifique, l’une de ces options peut être plus logique que les autres.
Comment calculer la distance du cuisinier en pratique
Les didacticiels suivants expliquent comment calculer la distance de Cook pour un ensemble de données donné en Python et R :
Comment calculer la distance du cuisinier en Python
Comment calculer la distance de Cook en R
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus