
Qu’est-ce que Y Hat en statistiques ?
En statistique, le terme y hat (écrit ŷ ) fait référence à la valeur estimée d’une variable de réponse dans un modèle de régression linéaire .
Nous écrivons généralement une équation de régression estimée comme suit :
ŷ = β 0 + β 1 x
où:
- ŷ : La valeur estimée de la variable de réponse
- β 0 : La valeur moyenne de la variable de réponse lorsque la variable prédictive est nulle
- β 1 : variation moyenne de la variable de réponse associée à une augmentation d’une unité de la variable prédictive
Par exemple, supposons que nous ayons l’ensemble de données suivant qui montre le nombre d’heures étudiées par six étudiants différents ainsi que leurs résultats aux examens finaux :
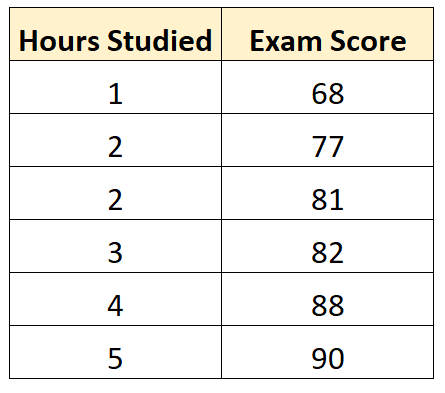
Supposons que nous utilisions un logiciel statistique (comme R , Excel , Python ou même manuellement ) pour ajuster le modèle de régression suivant en utilisant les heures étudiées comme variable prédictive et les résultats de l’examen comme variable de réponse :
Score = 66,615 + 5,0769*(Heures)
La façon d’interpréter les coefficients de régression dans ce modèle est la suivante :
- La note moyenne à l’examen pour un étudiant qui étudie zéro heure est de 66,615 .
- Le score à l’examen augmente en moyenne de 5,0769 points pour chaque heure supplémentaire étudiée.
Nous pouvons utiliser cette équation de régression pour estimer le score d’un élève donné en fonction du nombre d’heures étudiées.
Par exemple, un étudiant qui étudie pendant 3 heures devrait obtenir un score de :
Note = 66,615 + 5,0769*(3) = 81,85
Pourquoi Y Hat est-il utilisé ?
Le symbole « chapeau » dans les statistiques est utilisé pour désigner tout terme « estimé ». Par exemple, ŷ est utilisé pour désigner une variable de réponse estimée.
Généralement, lorsque nous ajustons des modèles de régression linéaire, nous utilisons un échantillon de données provenant d’une population, car cela est plus pratique et prend moins de temps que de collecter des données pour chaque observation possible dans une population.
Ainsi, lorsque nous trouvons une équation de régression, nous estimons uniquement la véritable relation entre une variable prédictive et une variable de réponse.
C’est pourquoi nous utilisons le terme ŷ dans l’équation de régression au lieu de y.
Ressources additionnelles
Introduction à la régression linéaire simple
Introduction à la régression linéaire multiple
Introduction aux variables explicatives et de réponse
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus