
Comment calculer la distance de Mahalanobis dans SPSS
La distance de Mahalanobis est la distance entre deux points dans un espace multivarié. Il est souvent utilisé pour détecter des valeurs aberrantes dans des analyses statistiques impliquant plusieurs variables.
Ce didacticiel explique comment calculer la distance de Mahalanobis dans SPSS.
Exemple : Distance de Mahalanobis dans SPSS
Supposons que nous ayons l’ensemble de données suivant qui affiche les résultats à l’examen de 20 étudiants ainsi que le nombre d’heures qu’ils ont passé à étudier, le nombre d’examens préparatoires qu’ils ont passés et leur note actuelle dans le cours :
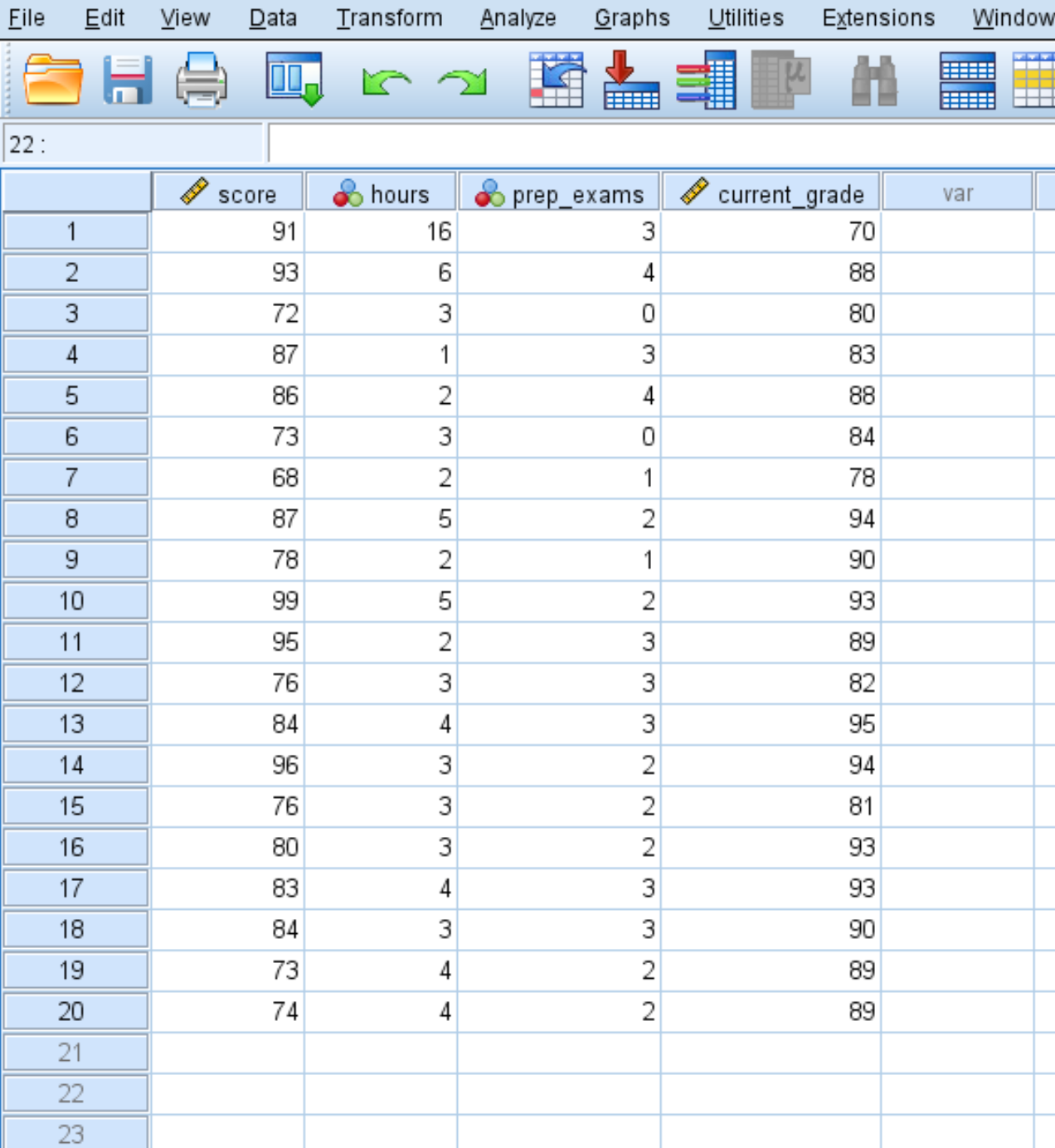
Nous pouvons utiliser les étapes suivantes pour calculer la distance de Mahalanobis pour chaque observation de l’ensemble de données afin de déterminer s’il existe des valeurs aberrantes multivariées.
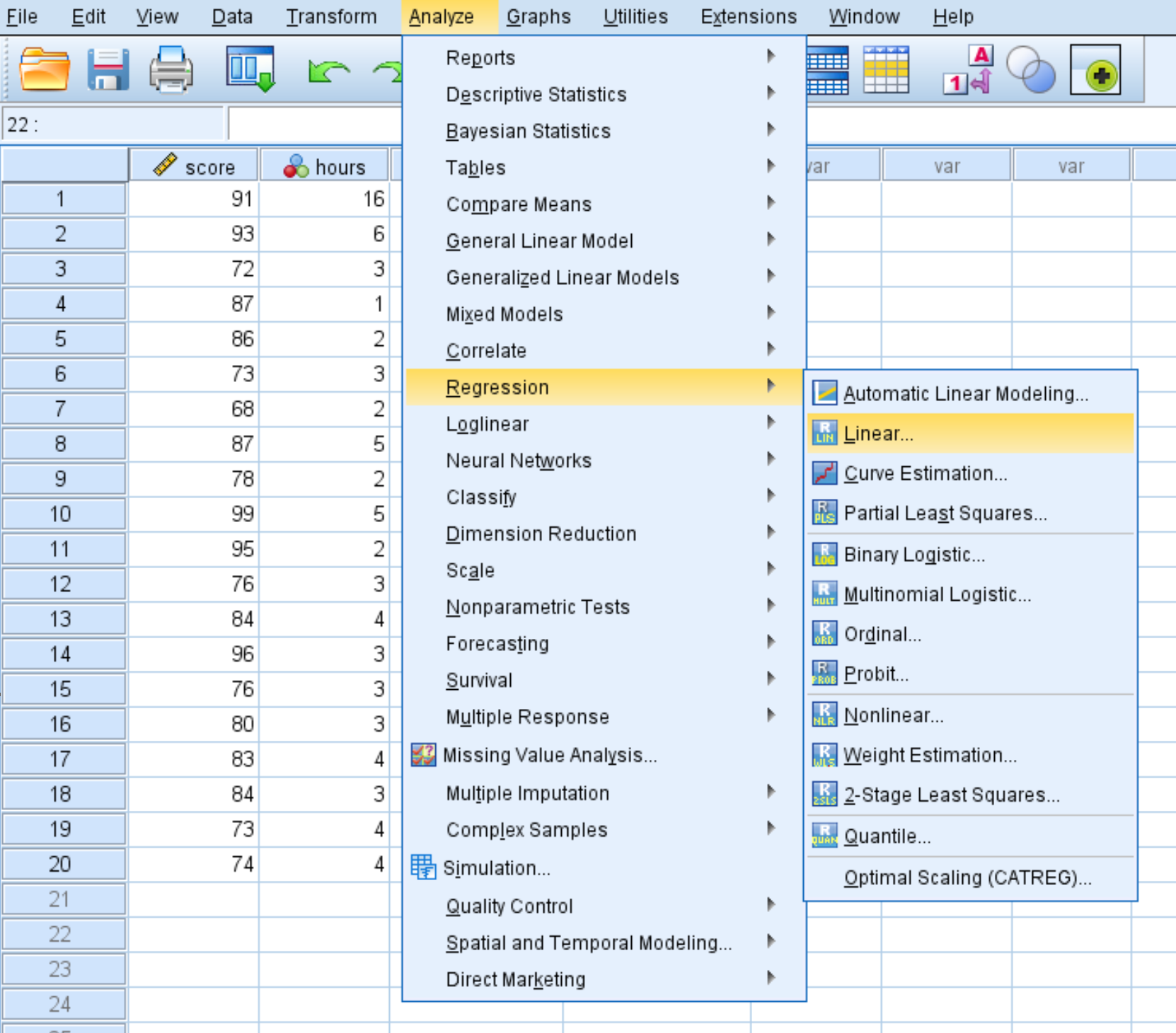
Étape 1 : Sélectionnez l’option de régression linéaire.
Cliquez sur l’onglet Analyser , puis Régression , puis Linéaire :
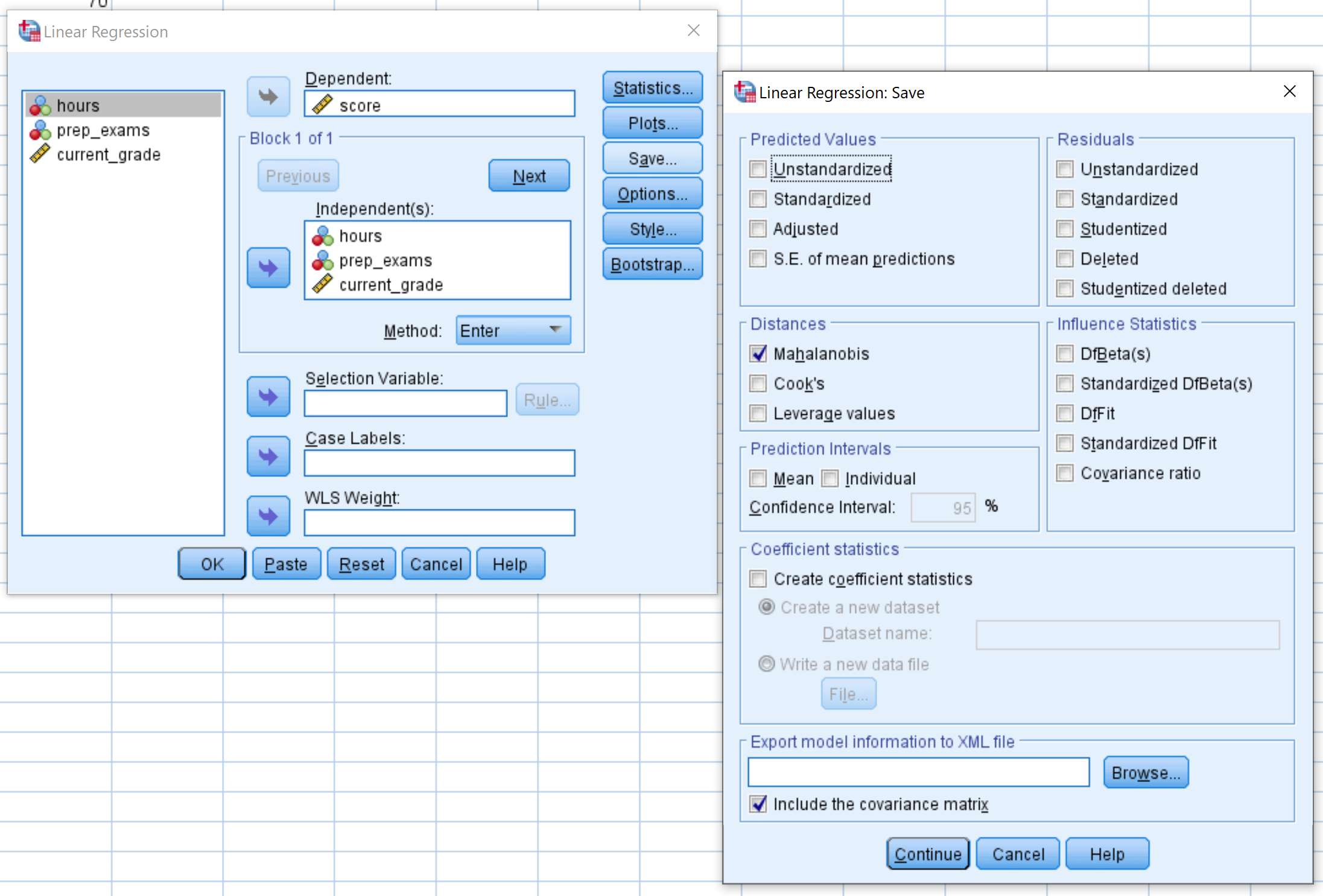
Étape 2 : Sélectionnez l’option Mahalanobis.
Faites glisser le score de la variable de réponse dans la zone intitulée Dépendant. Faites glisser les trois autres variables prédictives dans la zone intitulée Indépendant(s). Cliquez ensuite sur le bouton Enregistrer . Dans la nouvelle fenêtre qui apparaît, assurez-vous que la case à côté de Mahalanobis est cochée. Cliquez ensuite sur Continuer . Cliquez ensuite sur OK .
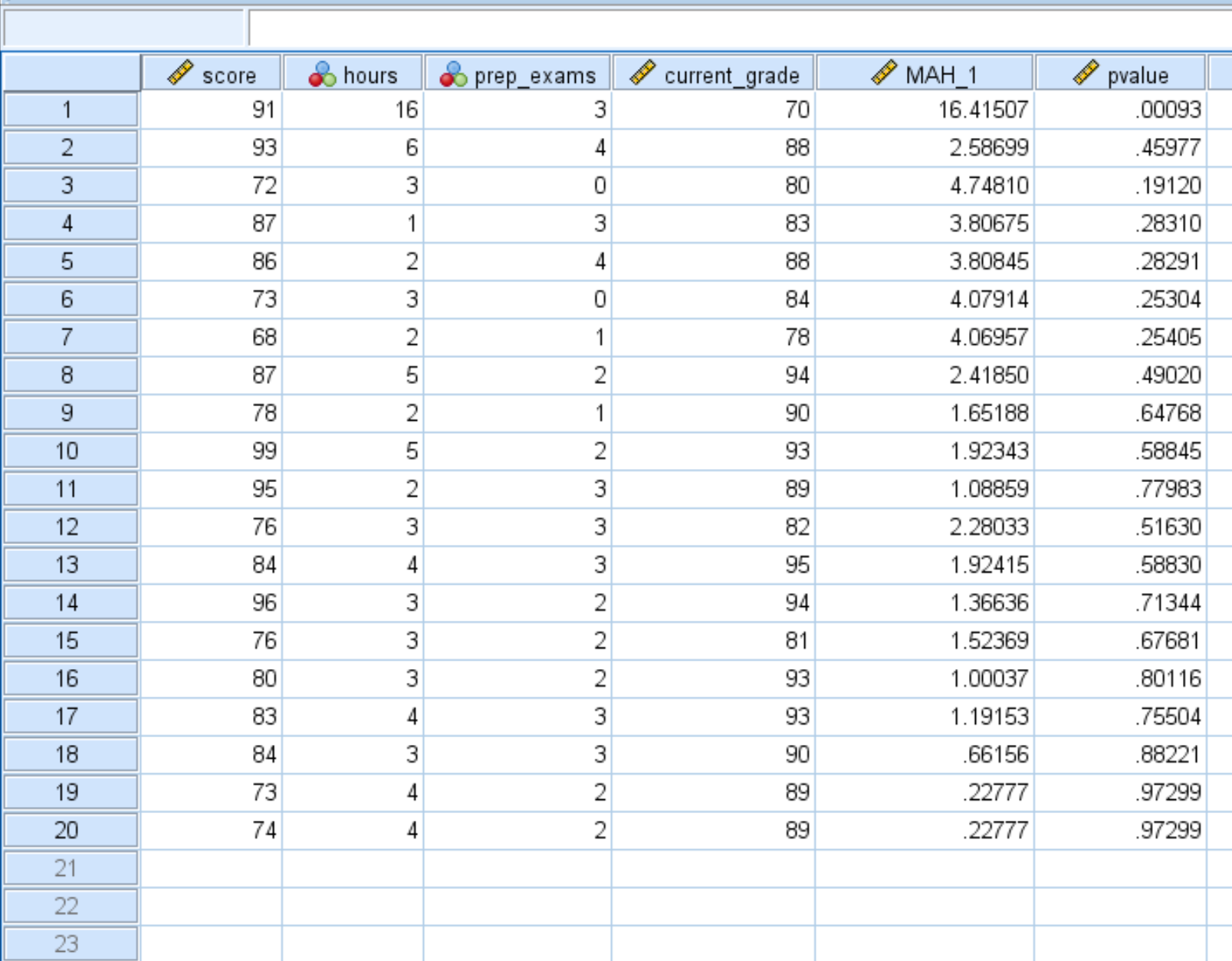
Une fois que vous avez cliqué sur OK , la distance de Mahalanobis pour chaque observation de l’ensemble de données apparaîtra dans une nouvelle colonne intitulée MAH_1 :
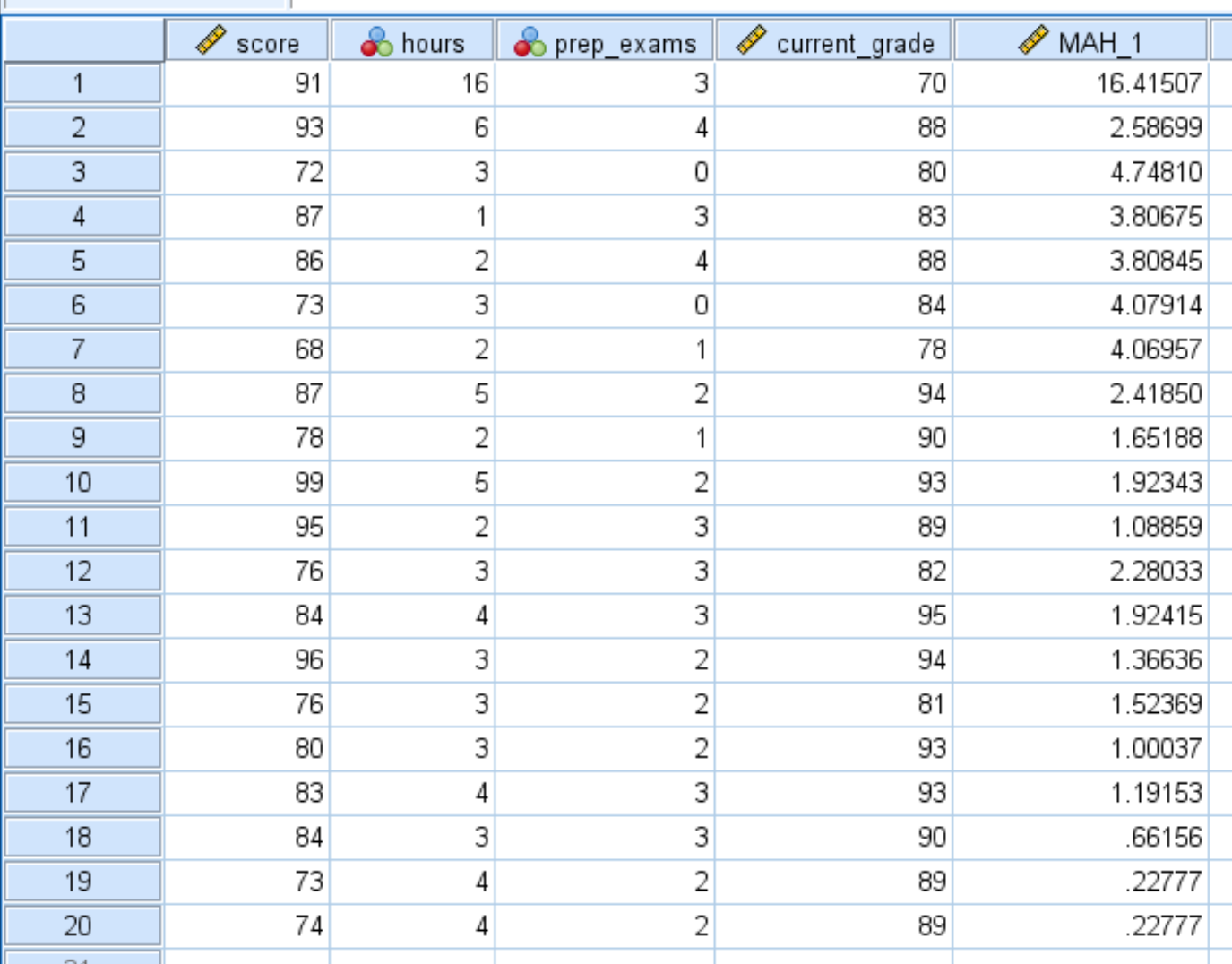
Nous pouvons constater que certaines distances sont beaucoup plus grandes que d’autres. Pour déterminer si l’une des distances est statistiquement significative, nous devons calculer leurs valeurs p.
Étape 3 : Calculez les valeurs p de chaque distance de Mahalanobis.
Cliquez sur l’onglet Transformation , puis sur Calculer la variable .
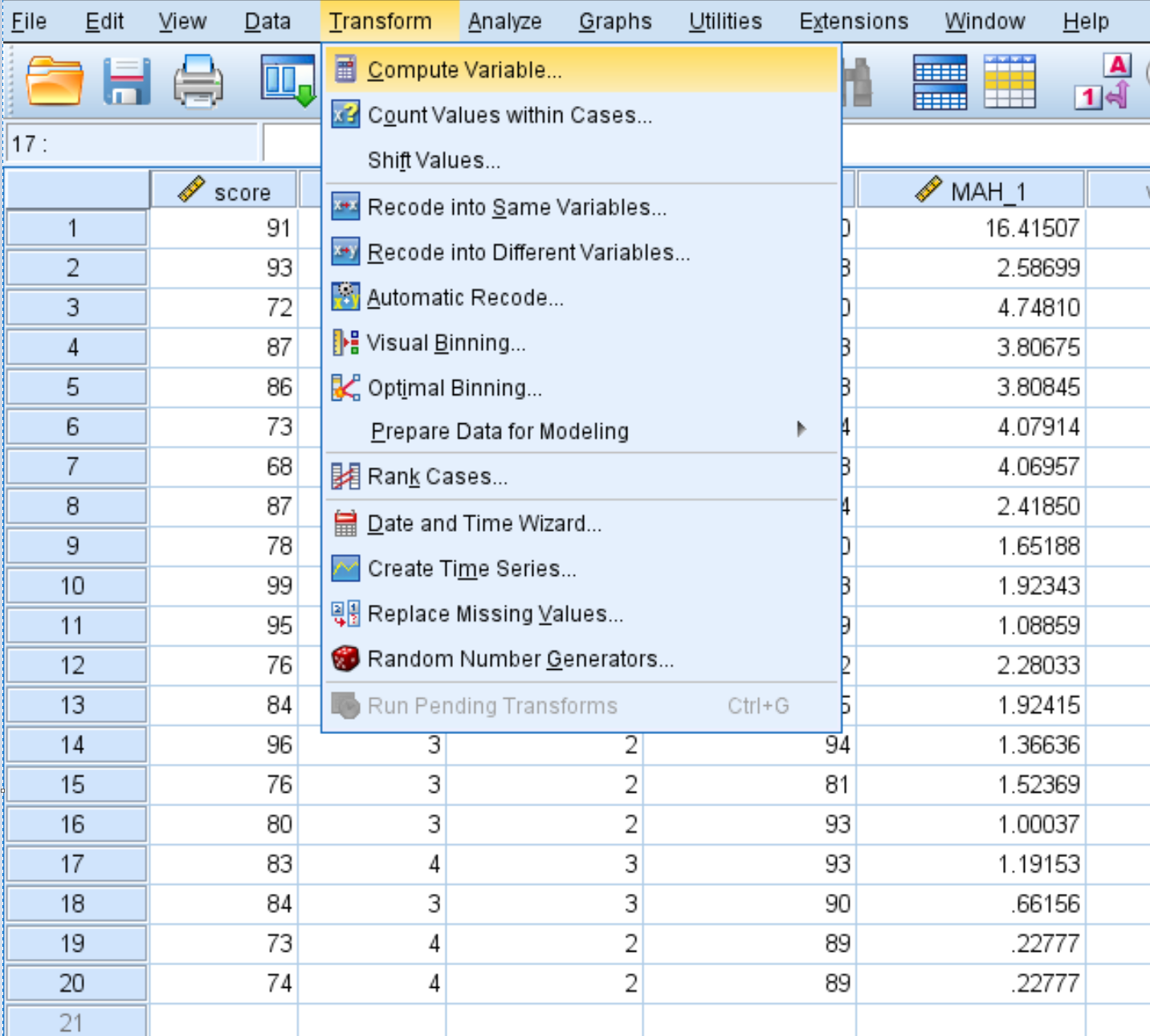
Dans la zone Variable cible , choisissez un nouveau nom pour la variable que vous créez. Nous avons choisi « pvalue ». Dans la zone Expression numérique , saisissez ce qui suit :
1 – CDF.CHISQ(MAH_1, 3)
Cliquez ensuite sur OK .
Cela produira une valeur p qui correspond à la valeur du Chi carré avec 3 degrés de liberté. Nous utilisons 3 degrés de liberté car il y a 3 variables prédictives dans notre modèle de régression.
Étape 4 : Interprétez les valeurs p.
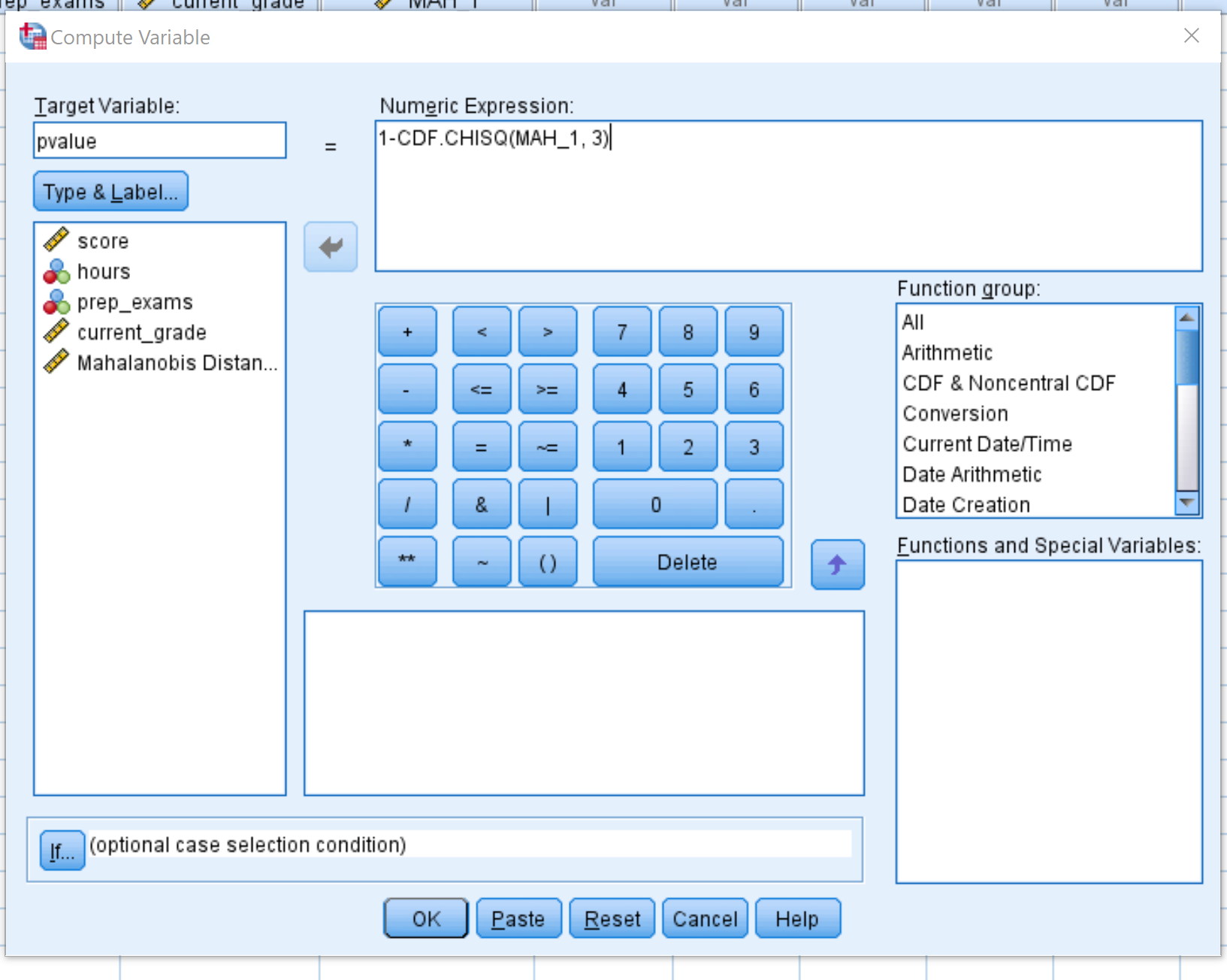
Une fois que vous avez cliqué sur OK , la valeur p pour chaque distance de Mahalanobis sera affichée dans une nouvelle colonne :
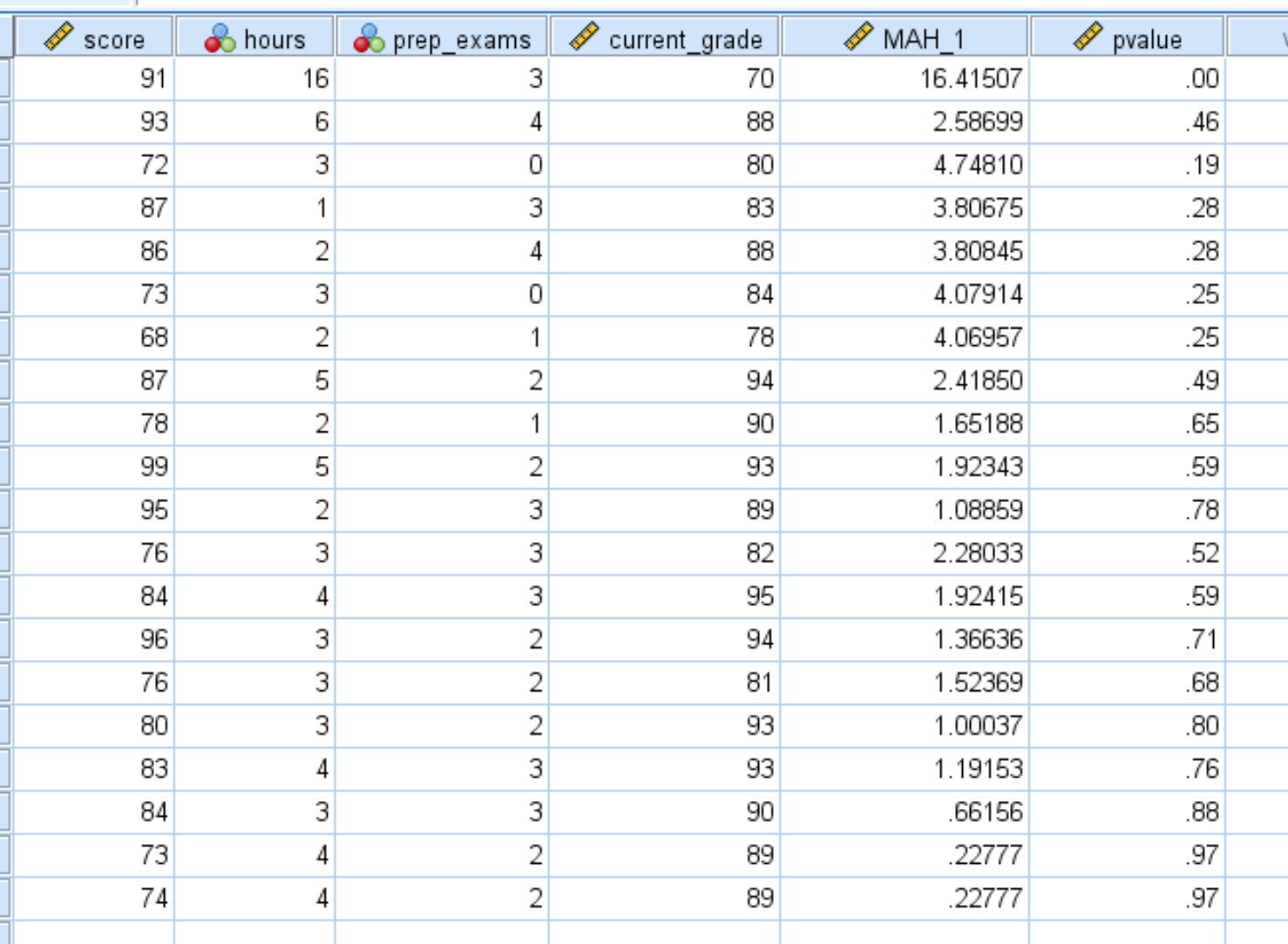
Par défaut, SPSS affiche uniquement les valeurs p avec deux décimales. Vous pouvez augmenter le nombre de décimales en cliquant sur Affichage des variables en bas de SPSS et en augmentant le nombre dans la colonne Décimales :
Une fois que vous revenez à la vue Données , vous pouvez voir chaque valeur p affichée avec cinq décimales. Toute valeur p inférieure à 0,001 est considérée comme une valeur aberrante.
Nous pouvons voir que la première observation est la seule valeur aberrante dans l’ensemble de données car elle a une valeur p inférieure à 0,001 :
Comment gérer les valeurs aberrantes
Si une valeur aberrante est présente dans vos données, vous disposez de plusieurs options :
1. Assurez-vous que la valeur aberrante n’est pas le résultat d’une erreur de saisie de données.
Parfois, un individu saisit simplement une mauvaise valeur de données lors de l’enregistrement des données. Si une valeur aberrante est présente, vérifiez d’abord que la valeur des données a été saisie correctement et qu’il ne s’agissait pas d’une erreur.
2. Supprimez la valeur aberrante.
Si la valeur est réellement aberrante, vous pouvez choisir de la supprimer si elle aura un impact significatif sur votre analyse globale. Assurez-vous simplement de mentionner dans votre rapport ou analyse final que vous avez supprimé une valeur aberrante.
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus