
Comment tester la multicolinéarité dans Stata
La multicolinéarité dans l’analyse de régression se produit lorsque deux ou plusieurs variables explicatives sont fortement corrélées les unes aux autres, de sorte qu’elles ne fournissent pas d’informations uniques ou indépendantes dans le modèle de régression. Si le degré de corrélation est suffisamment élevé entre les variables, cela peut poser des problèmes lors de l’ajustement et de l’interprétation du modèle de régression.
Par exemple, supposons que vous exécutiez une régression linéaire multiple avec les variables suivantes :
Variable de réponse : saut vertical maximum
Variables explicatives : pointure, taille, temps passé à pratiquer
Dans ce cas, les variables explicatives pointure et taille sont probablement fortement corrélées puisque les personnes de grande taille ont tendance à avoir des pointures plus grandes. Cela signifie que la multicolinéarité est susceptible de poser problème dans cette régression.
Heureusement, il est possible de détecter la multicolinéarité à l’aide d’une métrique appelée facteur d’inflation de la variance (VIF) , qui mesure la corrélation et la force de la corrélation entre les variables explicatives dans un modèle de régression.
Ce didacticiel explique comment utiliser VIF pour détecter la multicolinéarité dans une analyse de régression dans Stata.
Exemple : multicolinéarité dans Stata
Pour cet exemple, nous utiliserons l’ensemble de données intégré à Stata appelé auto . Utilisez la commande suivante pour charger l’ensemble de données :
utiliser automatiquement
Nous utiliserons la commande regress pour ajuster un modèle de régression linéaire multiple en utilisant le prix comme variable de réponse et le poids, la longueur et le mpg comme variables explicatives :
régression prix poids longueur mpg
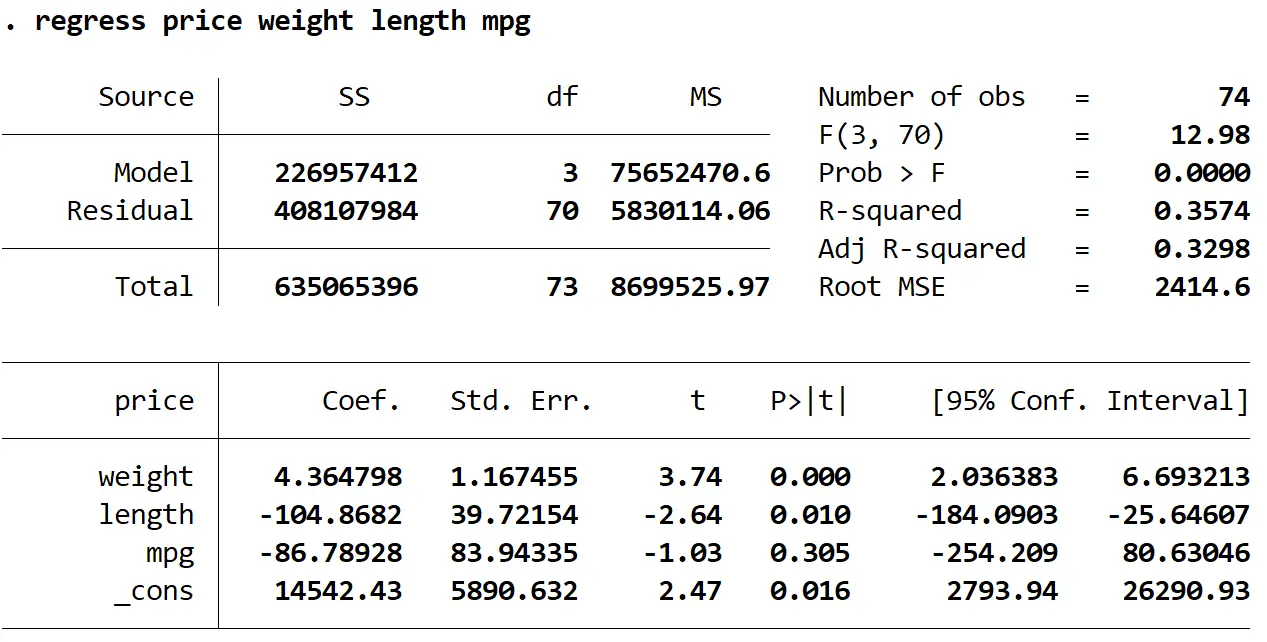
Ensuite, nous utiliserons la commande vif pour tester la multicolinéarité :
vif
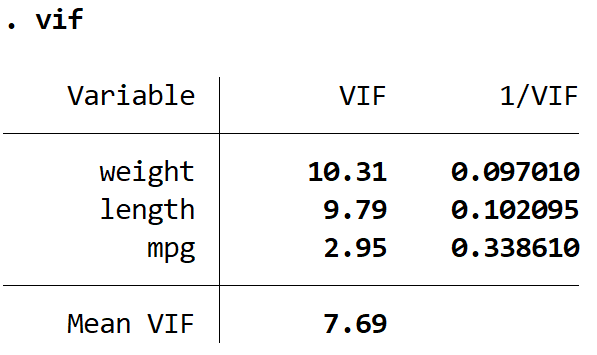
Cela produit une valeur VIF pour chacune des variables explicatives du modèle. La valeur de VIF commence à 1 et n’a pas de limite supérieure. Une règle générale pour interpréter les VIF est la suivante :
- Une valeur de 1 indique qu’il n’y a aucune corrélation entre une variable explicative donnée et toute autre variable explicative du modèle.
- Une valeur comprise entre 1 et 5 indique une corrélation modérée entre une variable explicative donnée et d’autres variables explicatives du modèle, mais elle n’est souvent pas suffisamment grave pour nécessiter une attention particulière.
- Une valeur supérieure à 5 indique une corrélation potentiellement sévère entre une variable explicative donnée et d’autres variables explicatives du modèle. Dans ce cas, les estimations des coefficients et les valeurs p dans les résultats de la régression ne sont probablement pas fiables.
Nous pouvons voir que les valeurs VIF pour le poids et la longueur sont supérieures à 5, ce qui indique que la multicolinéarité est probablement un problème dans le modèle de régression.
Comment gérer la multicolinéarité
Souvent, le moyen le plus simple de gérer la multicolinéarité consiste simplement à supprimer l’une des variables problématiques, car la variable que vous supprimez est probablement redondante de toute façon et ajoute peu d’informations uniques ou indépendantes au modèle.
Pour déterminer quelle variable supprimer, nous pouvons utiliser la commande corr pour créer une matrice de corrélation afin d’afficher les coefficients de corrélation entre chacune des variables du modèle, ce qui peut nous aider à identifier quelles variables pourraient être fortement corrélées les unes aux autres et pourraient causer le problème de la multicolinéarité :
corr prix poids longueur mpg
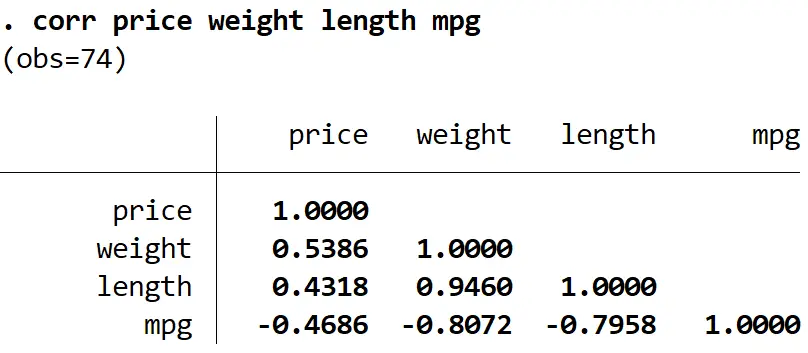
Nous pouvons voir que la longueur est fortement corrélée à la fois au poids et au mpg, et qu’elle a la plus faible corrélation avec le prix variable de réponse. Ainsi, supprimer la longueur du modèle pourrait résoudre le problème de multicolinéarité sans réduire la qualité globale du modèle de régression.
Pour tester cela, nous pouvons effectuer à nouveau l’analyse de régression en utilisant uniquement le poids et le mpg comme variables explicatives :
régression prix poids mpg
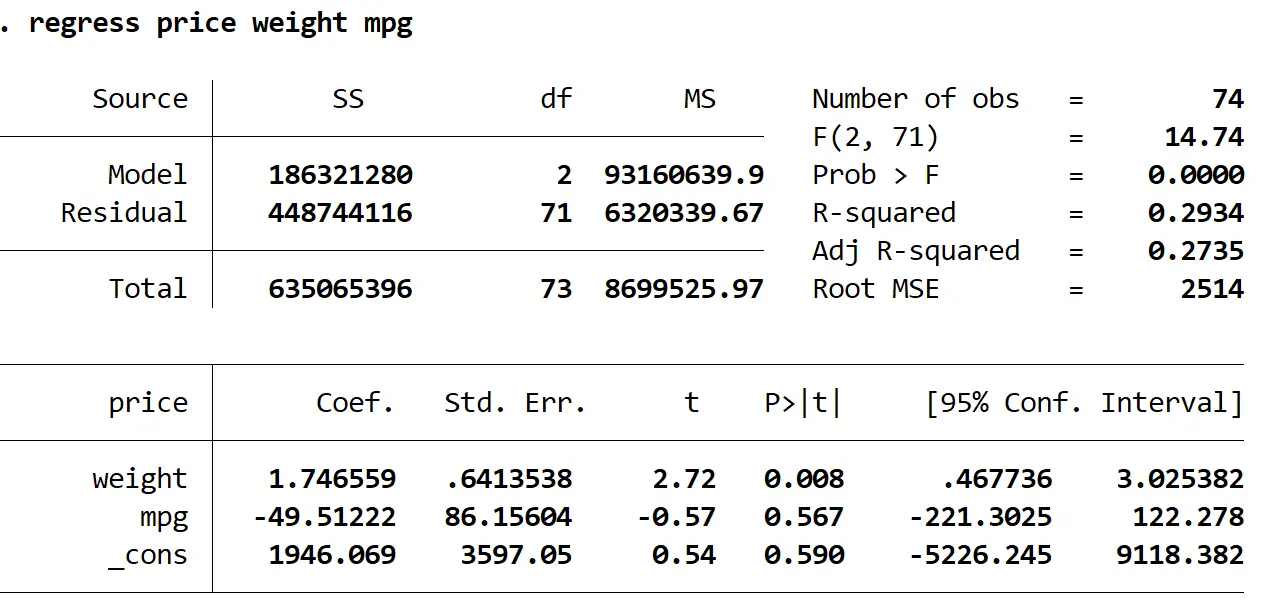
On peut voir que le R-carré ajusté de ce modèle est de 0,2735 contre 0,3298 dans le modèle précédent. Cela indique que l’utilité globale du modèle n’a que légèrement diminué. Ensuite, nous pouvons retrouver les valeurs VIF à l’aide de la commande VIF :
VIF
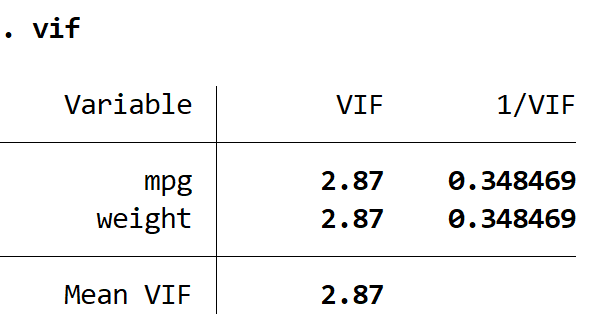
Les deux valeurs VIF sont inférieures à 5, ce qui indique que la multicolinéarité ne pose plus de problème dans le modèle.
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus