
Comment utiliser des erreurs standard robustes dans la régression dans Stata
La régression linéaire multiple est une méthode que nous pouvons utiliser pour comprendre la relation entre plusieurs variables explicatives et une variable de réponse.
Malheureusement, un problème qui se produit souvent en régression est connu sous le nom d’ hétéroscédasticité , dans lequel il y a un changement systématique dans la variance des résidus sur une plage de valeurs mesurées.
Cela entraîne une augmentation de la variance des estimations du coefficient de régression, mais le modèle de régression ne prend pas en compte ce phénomène. Cela rend beaucoup plus probable qu’un modèle de régression déclare qu’un terme du modèle est statistiquement significatif, alors qu’en réalité il ne l’est pas.
Une façon de prendre en compte ce problème consiste à utiliser des erreurs types robustes , qui sont plus « robustes » au problème de l’hétéroscédasticité et tendent à fournir une mesure plus précise de la véritable erreur type d’un coefficient de régression.
Ce didacticiel explique comment utiliser des erreurs standard robustes dans l’analyse de régression dans Stata.
Exemple : erreurs standard robustes dans Stata
Nous utiliserons l’ensemble de données Stata intégré automatiquement pour illustrer comment utiliser des erreurs standard robustes en régression.
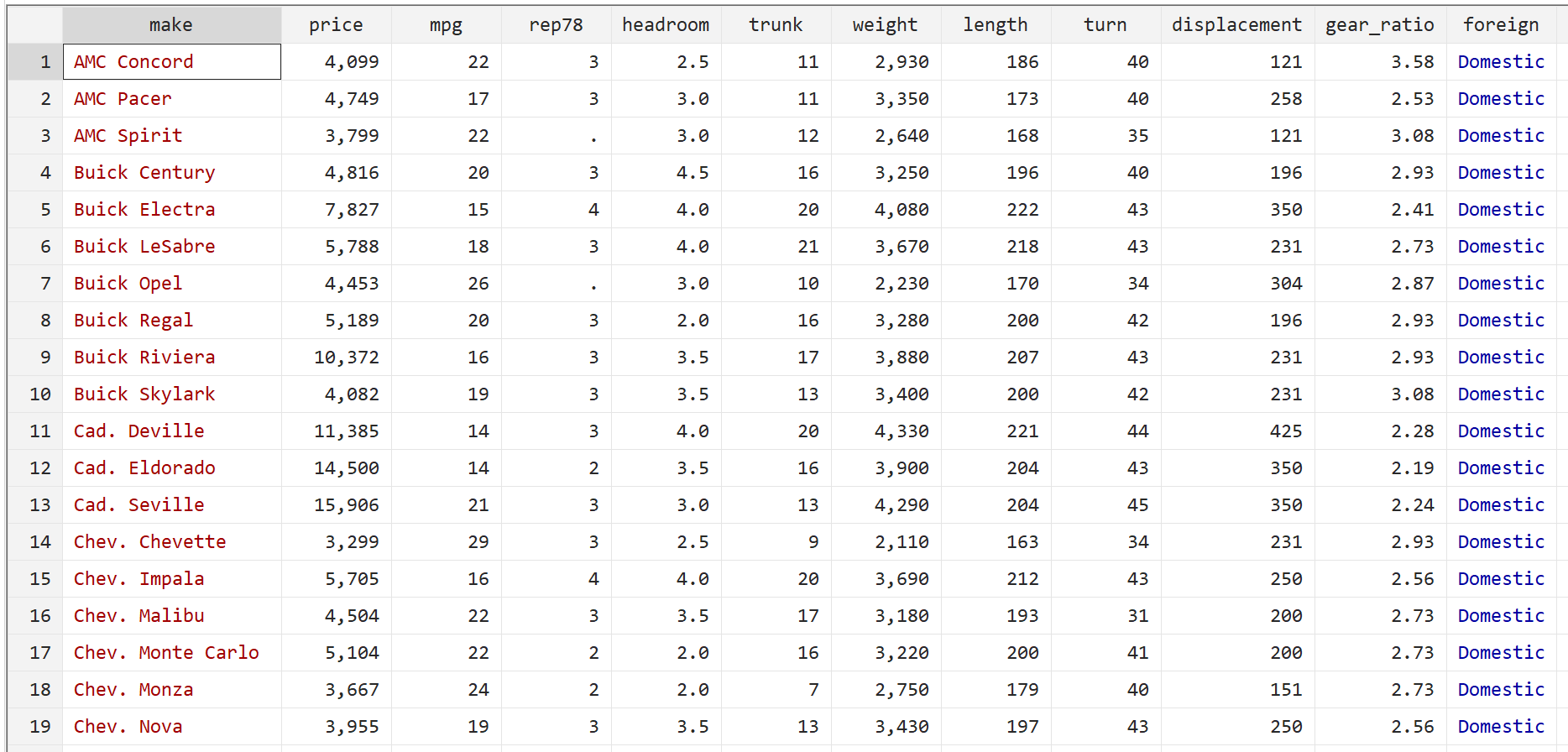
Étape 1 : Chargez et affichez les données.
Tout d’abord, utilisez la commande suivante pour charger les données :
utilisation automatique du système
Ensuite, affichez les données brutes à l’aide de la commande suivante :
br
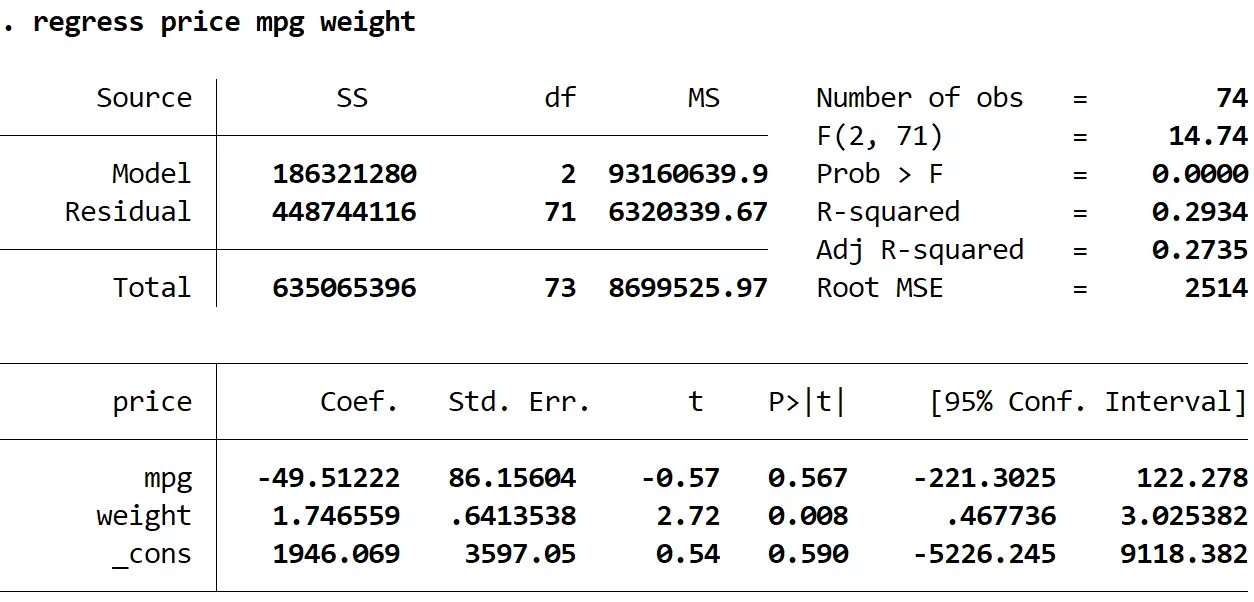
Étape 2 : Effectuez une régression linéaire multiple sans erreurs types robustes.
Ensuite, nous saisirons la commande suivante pour effectuer une régression linéaire multiple en utilisant le prix comme variable de réponse et le mpg et le poids comme variables explicatives :
régression prix mpg poids
Étape 3 : Effectuez une régression linéaire multiple en utilisant des erreurs standard robustes.
Nous allons maintenant effectuer exactement la même régression linéaire multiple, mais cette fois, nous utiliserons la commande vce(robust) pour que Stata sache utiliser des erreurs standard robustes :
régression prix mpg poids, vce (robuste)
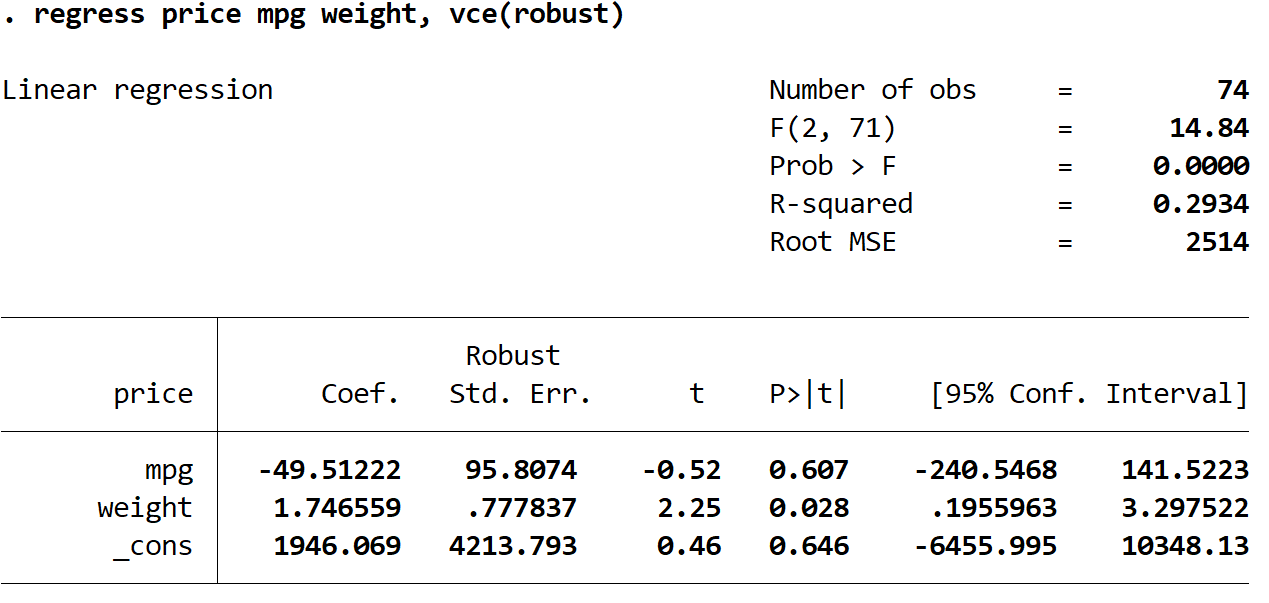
Il y a quelques choses intéressantes à noter ici :
1. Les estimations des coefficients sont restées les mêmes . Lorsque nous utilisons des erreurs types robustes, les estimations des coefficients ne changent pas du tout. Notez que les estimations des coefficients pour le mpg, le poids et la constante sont les suivantes pour les deux régressions :
- mpg: -49.51222
- poids : 1.746559
- _contre : 1946.069
2. Les erreurs standard ont changé . Notez que lorsque nous avons utilisé des erreurs types robustes, les erreurs types pour chacune des estimations de coefficient ont augmenté.
Remarque : Dans la plupart des cas, les erreurs standard robustes seront supérieures aux erreurs standard normales, mais dans de rares cas, il est possible que les erreurs standard robustes soient en réalité plus petites.
3. La statistique de test de chaque coefficient a changé. Notez que la valeur absolue de chaque statistique de test , t , a diminué. En effet, la statistique du test est calculée comme le coefficient estimé divisé par l’erreur type. Ainsi, plus l’erreur type est grande, plus la valeur absolue de la statistique du test est petite.
4. Les valeurs p ont changé . Notez que les valeurs p pour chaque variable ont également augmenté. En effet, des statistiques de test plus petites sont associées à des valeurs p plus grandes.
Bien que les valeurs p aient changé pour nos coefficients, la variable mpg n’est toujours pas statistiquement significative à α = 0,05 et le poids variable est toujours statistiquement significatif à α = 0,05.
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus