
Comment effectuer une régression logistique dans Stata
La régression logistique est une méthode que nous utilisons pour ajuster un modèle de régression lorsque la variable de réponse est binaire. Voici quelques exemples d’utilisation de la régression logistique :
- Nous voulons savoir quel est l’impact de l’exercice, de l’alimentation et du poids sur la probabilité d’avoir une crise cardiaque. La variable de réponse est la crise cardiaque et elle a deux résultats potentiels : une crise cardiaque se produit ou ne se produit pas.
- Nous voulons savoir comment le GPA, le score ACT et le nombre de cours AP suivis ont un impact sur la probabilité d’être accepté dans une université particulière. La variable de réponse est l’acceptation et elle a deux résultats potentiels : accepté ou non accepté.
- Nous voulons savoir si le nombre de mots et le titre de l’e-mail ont un impact sur la probabilité qu’un e-mail soit du spam. La variable de réponse est spam et elle a deux résultats potentiels : spam ou non spam.
Ce tutoriel explique comment effectuer une régression logistique dans Stata.
Exemple : régression logistique dans Stata
Supposons que nous souhaitions comprendre si l’âge d’une mère et ses habitudes tabagiques affectent la probabilité d’avoir un bébé de faible poids à la naissance.
Pour explorer cela, nous pouvons effectuer une régression logistique en utilisant l’âge et le tabagisme (oui ou non) comme variables explicatives et le faible poids à la naissance (oui ou non) comme variable de réponse. Puisque la variable de réponse est binaire – il n’y a que deux résultats possibles – il convient d’utiliser la régression logistique.
Effectuez les étapes suivantes dans Stata pour effectuer une régression logistique à l’aide de l’ensemble de données appelé lbw , qui contient des données sur 189 mères différentes.
Étape 1 : Chargez les données.
Chargez les données en tapant ce qui suit dans la zone de commande :
utilisez https://www.stata-press.com/data/r13/lbw
Étape 2 : Obtenez un résumé des données.
Obtenez une compréhension rapide des données avec lesquelles vous travaillez en tapant ce qui suit dans la zone Commande :
résumer
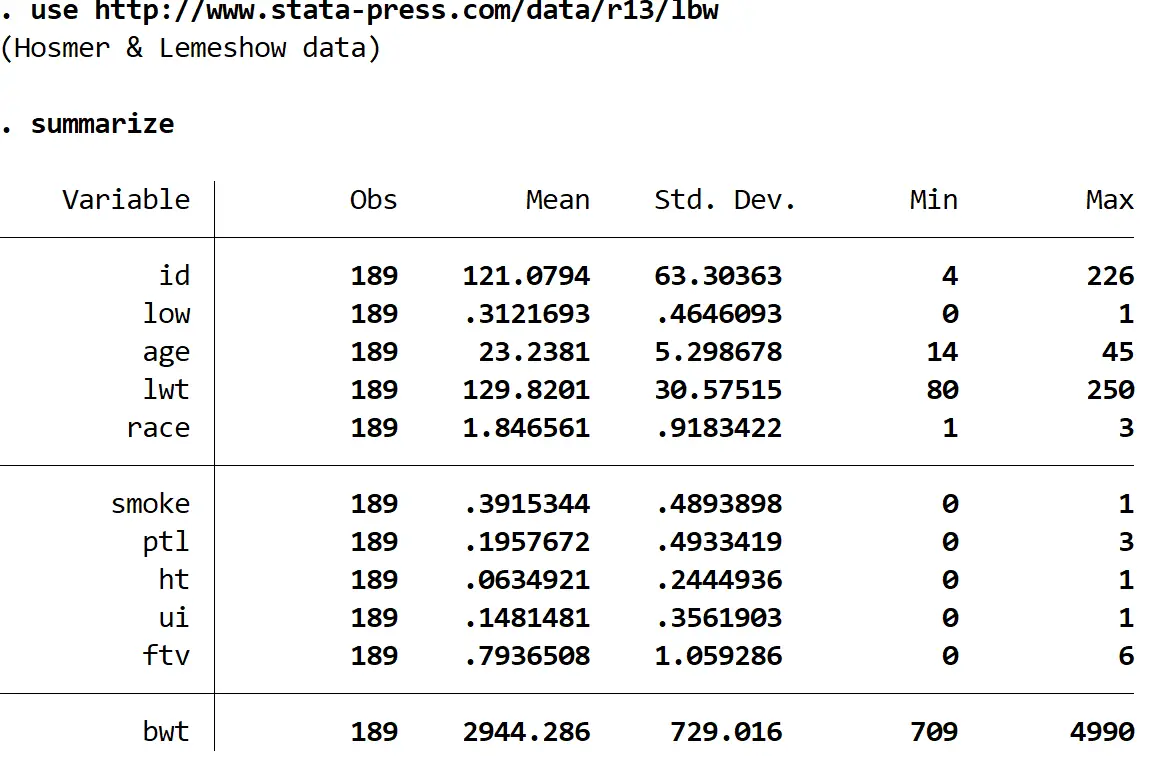
Nous pouvons voir qu’il y a 11 variables différentes dans l’ensemble de données, mais les trois seules qui nous intéressent sont les suivantes :
- faible – que le bébé ait ou non un faible poids à la naissance. 1 = oui, 0 = non.
- âge – âge de la mère.
- fumée – si la mère a fumé ou non pendant la grossesse. 1 = oui, 0 = non.
Étape 3 : Effectuez une régression logistique.
Tapez ce qui suit dans la zone de commande pour effectuer une régression logistique en utilisant l’âge et la fumée comme variables explicatives et faible comme variable de réponse.
logit fumée de faible âge
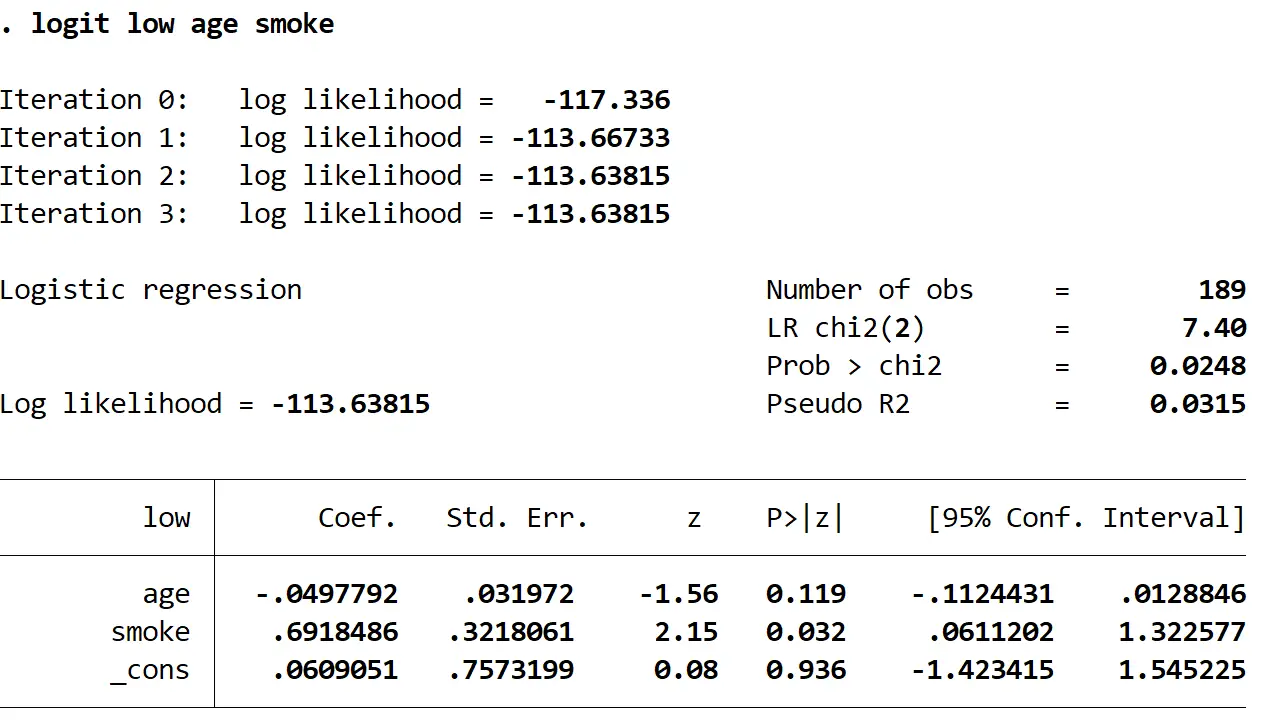
Voici comment interpréter les nombres les plus intéressants du résultat :
Coef (âge) : -.0497792. En maintenant la fumée constante, chaque année d’augmentation de l’âge est associée à une augmentation exp(-0,0497792) = 0,951 des chances qu’un bébé ait un faible poids à la naissance. Ce nombre étant inférieur à 1, cela signifie qu’une augmentation de l’âge est en réalité associée à une diminution des chances d’avoir un bébé de faible poids à la naissance.
Par exemple, supposons que la mère A et la mère B fument toutes les deux. Si la mère A a un an de plus que la mère B, alors les chances que la mère A ait un bébé de faible poids à la naissance ne représentent que 95,1 % des chances que la mère B ait un bébé de faible poids à la naissance.
P>|z| (âge) : 0,119. Il s’agit de la valeur p associée à la statistique de test pour l’âge . Puisque cette valeur n’est pas inférieure à 0,05, l’âge n’est pas un prédicteur statistiquement significatif d’un faible poids à la naissance.
Rapport de cotes (fumée) : 0,6918486. En maintenant l’âge constant, une mère qui fume pendant la grossesse a une probabilité exp(.6918486) = 1,997 plus élevée d’avoir un bébé de faible poids à la naissance qu’une mère qui ne fume pas pendant la grossesse.
Par exemple, supposons que la mère A et la mère B aient toutes deux 30 ans. Si la mère A fume pendant la grossesse et que la mère B ne fume pas, alors les chances que la mère A ait un bébé de faible poids à la naissance sont 99,7 % plus élevées que les chances que la mère B ait un bébé de faible poids à la naissance.
P>|z| (fumée) : 0,032. Il s’agit de la valeur p associée à la statistique de test pour la fumée . Puisque cette valeur est inférieure à 0,05, la fumée est un prédicteur statistiquement significatif d’un faible poids à la naissance.
Étape 4 : Rapportez les résultats.
Enfin, nous souhaitons rapporter les résultats de notre régression logistique. Voici un exemple de la façon de procéder :
Une régression logistique a été réalisée pour déterminer si l’âge d’une mère et ses habitudes tabagiques affectent la probabilité d’avoir un bébé avec un faible poids à la naissance. Un échantillon de 189 mères a été utilisé dans l’analyse.
Les résultats ont montré qu’il existait une relation statistiquement significative entre le tabagisme et la probabilité d’un faible poids à la naissance (z = 2,15, p = 0,032), alors qu’il n’y avait pas de relation statistiquement significative entre l’âge et la probabilité d’un faible poids à la naissance (z = -1,56, p = 0,032). 119).
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus