
Statistique de test
Cet article explique ce que sont les statistiques de test dans les statistiques. Vous découvrirez également comment calculer une statistique de test et quand accepter ou rejeter une hypothèse en fonction de la valeur de la statistique de test.
Qu’est-ce qu’une statistique de test ?
Une statistique de test est une valeur calculée dans un test d’hypothèse . Plus précisément, la statistique de test est utilisée pour rejeter ou accepter l’hypothèse nulle d’un test d’hypothèse. Autrement dit, la statistique d’un test est la valeur calculée pour décider du résultat d’un test d’hypothèse.
Le test statistique tente de résumer les données d’un échantillon dans une valeur et, en plus, de mesurer le degré de concordance entre un échantillon de données et l’ hypothèse nulle du test. C’est pourquoi la statistique du test sert de référence pour décider de rejeter ou d’accepter l’hypothèse nulle.
Par exemple, la statistique du test Z est la statistique Z, qui suit une distribution normale et est utilisée pour rejeter ou rejeter une hypothèse du test Z.
Logiquement, pour déterminer s’il faut rejeter ou accepter l’hypothèse nulle d’un test d’hypothèse, il ne suffit pas de calculer la statistique correspondant à ce test d’hypothèse, mais il faut ensuite interpréter le résultat obtenu et voir s’il se situe dans la région de rejet ou dans la région d’acceptation. Ci-dessous, nous verrons comment cela se fait.
D’autre part, la p-value (ou p-value ) est la probabilité d’avoir obtenu la valeur de la statistique de test calculée en supposant que l’hypothèse nulle est vraie. Autrement dit, la valeur p est la probabilité correspondant à la statistique du test et est également utilisée pour rejeter ou accepter l’hypothèse nulle d’un test d’hypothèse. Vous pouvez en savoir plus sur la valeur p en cliquant sur le lien suivant :
Région de rejet et région d’acceptation d’une statistique de test
Pour rejeter ou accepter une hypothèse de test, nous devons voir si la statistique du test se situe dans la région de rejet ou dans la région d’acceptation. Ainsi, la région de rejet et la région d’acceptation d’un test d’hypothèse sont définies comme suit :
- Région de rejet (ou région critique) : est la zone du graphe de distribution de référence du test d’hypothèse qui consiste à rejeter l’hypothèse nulle (et à accepter l’hypothèse alternative).
- Région d’acceptation : est l’aire du graphique de la distribution de référence du test d’hypothèse qui implique l’acceptation de l’hypothèse nulle (et le rejet de l’hypothèse alternative).
Par conséquent, si la statistique du test se situe dans la région de rejet, l’hypothèse nulle est rejetée et l’hypothèse alternative est acceptée. À l’inverse, si la statistique du test se situe dans la région d’acceptation, l’hypothèse nulle est acceptée et l’hypothèse alternative est rejetée.
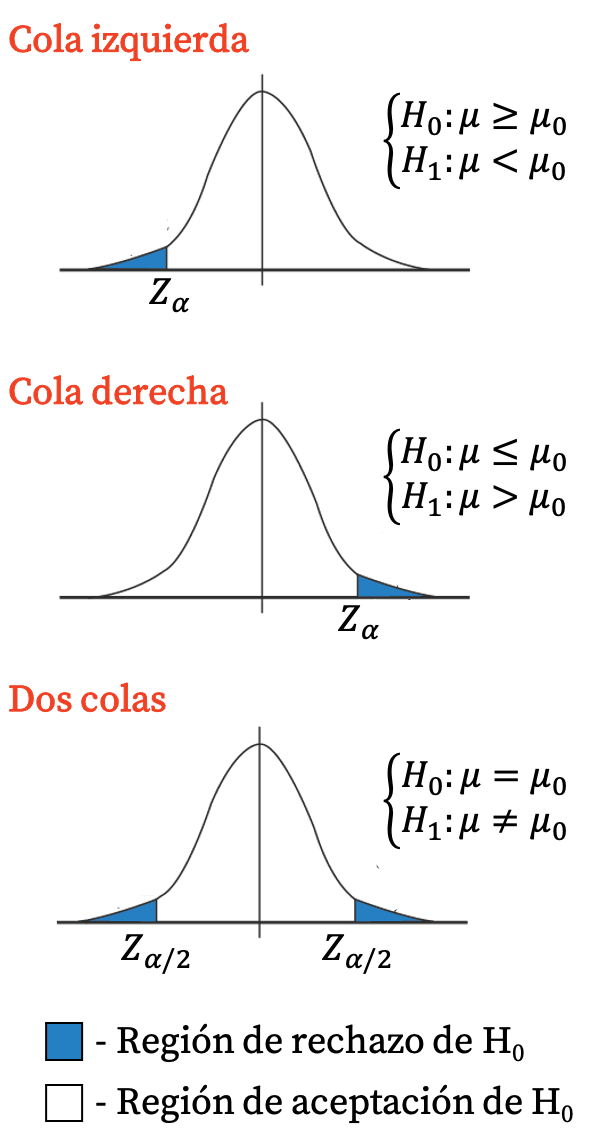
Les valeurs qui établissent les limites de la région de rejet et de la région d’acceptation sont appelées valeurs critiques , qui dépendent du niveau de signification choisi. Ainsi, en rejetant ou en acceptant une hypothèse, nous comparons en réalité la valeur de la statistique du test avec les valeurs critiques du test.
Tester les formules statistiques
Il n’existe pas de formule unique pour calculer la statistique du test, mais en fonction du test d’hypothèse, la formule de la statistique du test varie. C’est pourquoi nous vous laissons ci-dessous les liens suivants afin que vous puissiez voir comment la statistique du test est calculée dans chaque cas :
à propos de l'auteur
Pr Amélia Rodriguez
En mettant l'accent sur l'apprentissage interactif et les applications pratiques, la professeure Amélia Rodriguez propose des tutoriels complets et des exemples concrets pour rendre les concepts de probabilité accessibles et pertinents pour la vie de ses étudiants. Lire plus