
Analyse discriminante linéaire en Python (étape par étape)
L’analyse discriminante linéaire est une méthode que vous pouvez utiliser lorsque vous disposez d’un ensemble de variables prédictives et que vous souhaitez classer une variable de réponse en deux classes ou plus.
Ce didacticiel fournit un exemple étape par étape de la façon d’effectuer une analyse discriminante linéaire en Python.
Étape 1 : Charger les bibliothèques nécessaires
Tout d’abord, nous allons charger les fonctions et bibliothèques nécessaires pour cet exemple :
from sklearn.model_selection import train_test_split
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import cross_val_score
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn import datasets
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
Étape 2 : Charger les données
Pour cet exemple, nous utiliserons l’ensemble de données iris de la bibliothèque sklearn. Le code suivant montre comment charger cet ensemble de données et le convertir en DataFrame pandas pour faciliter son utilisation :
#load iris dataset iris = datasets.load_iris() #convert dataset to pandas DataFrame df = pd.DataFrame(data = np.c_[iris['data'], iris['target']], columns = iris['feature_names'] + ['target']) df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names) df.columns = ['s_length', 's_width', 'p_length', 'p_width', 'target', 'species'] #view first six rows of DataFrame df.head() s_length s_width p_length p_width target species 0 5.1 3.5 1.4 0.2 0.0 setosa 1 4.9 3.0 1.4 0.2 0.0 setosa 2 4.7 3.2 1.3 0.2 0.0 setosa 3 4.6 3.1 1.5 0.2 0.0 setosa 4 5.0 3.6 1.4 0.2 0.0 setosa #find how many total observations are in dataset len(df.index) 150
Nous pouvons voir que l’ensemble de données contient 150 observations au total.
Pour cet exemple, nous allons construire un modèle d’analyse discriminante linéaire pour classer à quelles espèces appartient une fleur donnée.
Nous utiliserons les variables prédictives suivantes dans le modèle :
- Longueur des sépales
- Largeur des sépales
- Longueur des pétales
- Largeur des pétales
Et nous les utiliserons pour prédire la variable de réponse Species , qui prend en charge les trois classes potentielles suivantes :
- sétosa
- versicolor
- virginie
Étape 3 : Ajuster le modèle LDA
Ensuite, nous adapterons le modèle LDA à nos données à l’aide de la fonction LinearDiscriminantAnalsyis de sklearn :
#define predictor and response variables X = df[['s_length', 's_width', 'p_length', 'p_width']] y = df['species'] #Fit the LDA model model = LinearDiscriminantAnalysis() model.fit(X, y)
Étape 4 : Utiliser le modèle pour faire des prédictions
Une fois que nous avons ajusté le modèle à l’aide de nos données, nous pouvons évaluer les performances du modèle en utilisant une validation croisée stratifiée répétée k-fold.
Pour cet exemple, nous utiliserons 10 plis et 3 répétitions :
#Define method to evaluate model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
#evaluate model
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
print(np.mean(scores))
0.9777777777777779
Nous pouvons voir que le modèle a réalisé une précision moyenne de 97,78 % .
Nous pouvons également utiliser le modèle pour prédire à quelle classe appartient une nouvelle fleur, en fonction des valeurs d’entrée :
#define new observation new = [5, 3, 1, .4] #predict which class the new observation belongs to model.predict([new]) array(['setosa'], dtype='<U10')
On voit que le modèle prédit que cette nouvelle observation appartient à l’espèce appelée setosa .
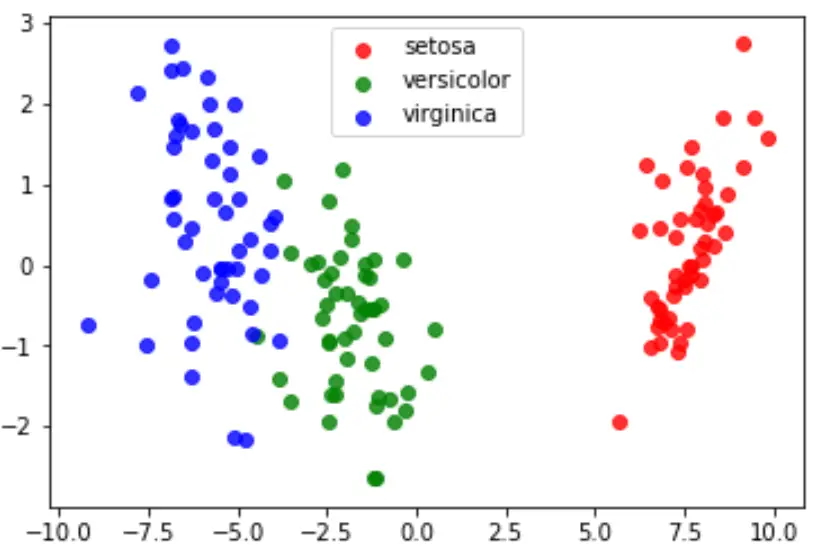
Étape 5 : Visualisez les résultats
Enfin, nous pouvons créer un tracé LDA pour visualiser les discriminants linéaires du modèle et visualiser dans quelle mesure il sépare les trois espèces différentes dans notre ensemble de données :
#define data to plot X = iris.data y = iris.target model = LinearDiscriminantAnalysis() data_plot = model.fit(X, y).transform(X) target_names = iris.target_names #create LDA plot plt.figure() colors = ['red', 'green', 'blue'] lw = 2 for color, i, target_name in zip(colors, [0, 1, 2], target_names): plt.scatter(data_plot[y == i, 0], data_plot[y == i, 1], alpha=.8, color=color, label=target_name) #add legend to plot plt.legend(loc='best', shadow=False, scatterpoints=1) #display LDA plot plt.show()
Vous pouvez trouver le code Python complet utilisé dans ce tutoriel ici .
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus