
Comment effectuer une analyse univariée en Python : avec des exemples
Le terme analyse univariée fait référence à l’analyse d’une variable. Vous pouvez vous en souvenir car le préfixe « uni » signifie « un ».
Il existe trois manières courantes d’effectuer une analyse univariée sur une variable :
1. Statistiques récapitulatives – Mesure le centre et la répartition des valeurs.
2. Tableau de fréquence – Décrit la fréquence à laquelle différentes valeurs apparaissent.
3. Graphiques – Utilisé pour visualiser la distribution des valeurs.
Ce didacticiel fournit un exemple de la manière d’effectuer une analyse univariée avec le DataFrame pandas suivant :
import pandas as pd #create DataFrame df = pd.DataFrame({'points': [1, 1, 2, 3.5, 4, 4, 4, 5, 5, 6.5, 7, 7.4, 8, 13, 14.2], 'assists': [5, 7, 7, 9, 12, 9, 9, 4, 6, 8, 8, 9, 3, 2, 6], 'rebounds': [11, 8, 10, 6, 6, 5, 9, 12, 6, 6, 7, 8, 7, 9, 15]}) #view first five rows of DataFrame df.head() points assists rebounds 0 1.0 5 11 1 1.0 7 8 2 2.0 7 10 3 3.5 9 6 4 4.0 12 6
1. Calculer les statistiques récapitulatives
Nous pouvons utiliser la syntaxe suivante pour calculer diverses statistiques récapitulatives pour la variable « points » dans le DataFrame :
#calculate mean of 'points' df['points'].mean() 5.706666666666667 #calculate median of 'points' df['points'].median() 5.0 #calculate standard deviation of 'points' df['points'].std() 3.858287308169384
2. Créer un tableau de fréquence
Nous pouvons utiliser la syntaxe suivante pour créer un tableau de fréquences pour la variable ‘points’ :
#create frequency table for 'points' df['points'].value_counts() 4.0 3 1.0 2 5.0 2 2.0 1 3.5 1 6.5 1 7.0 1 7.4 1 8.0 1 13.0 1 14.2 1 Name: points, dtype: int64
Cela nous dit que :
- La valeur 4 apparaît 3 fois
- La valeur 1 apparaît 2 fois
- La valeur 5 apparaît 2 fois
- La valeur 2 apparaît 1 fois
Et ainsi de suite.
Connexe : Comment créer des tableaux de fréquences en Python
3. Créer des graphiques
Nous pouvons utiliser la syntaxe suivante pour créer un boxplot pour la variable ‘points’ :
import matplotlib.pyplot as plt df.boxplot(column=['points'], grid=False, color='black')
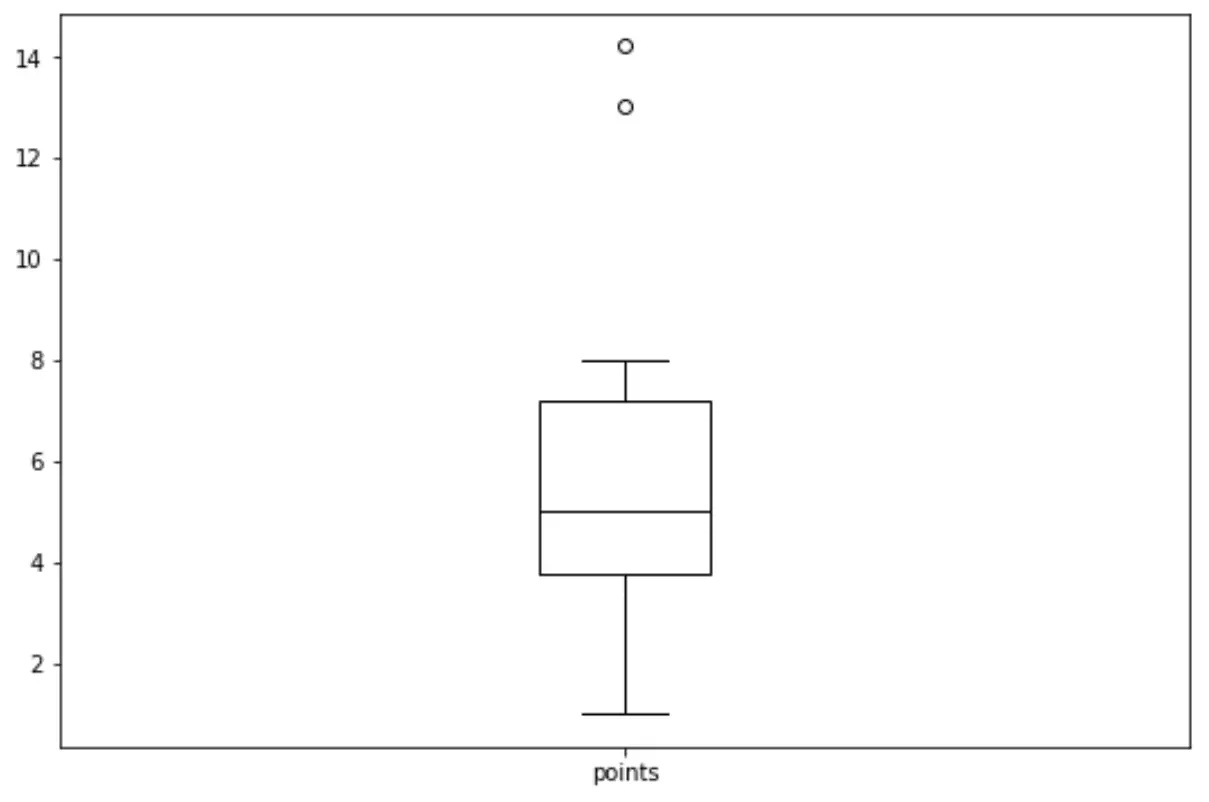
Connexe : Comment créer un boxplot à partir de Pandas DataFrame
Nous pouvons utiliser la syntaxe suivante pour créer un histogramme pour la variable ‘points’ :
import matplotlib.pyplot as plt df.hist(column='points', grid=False, edgecolor='black')
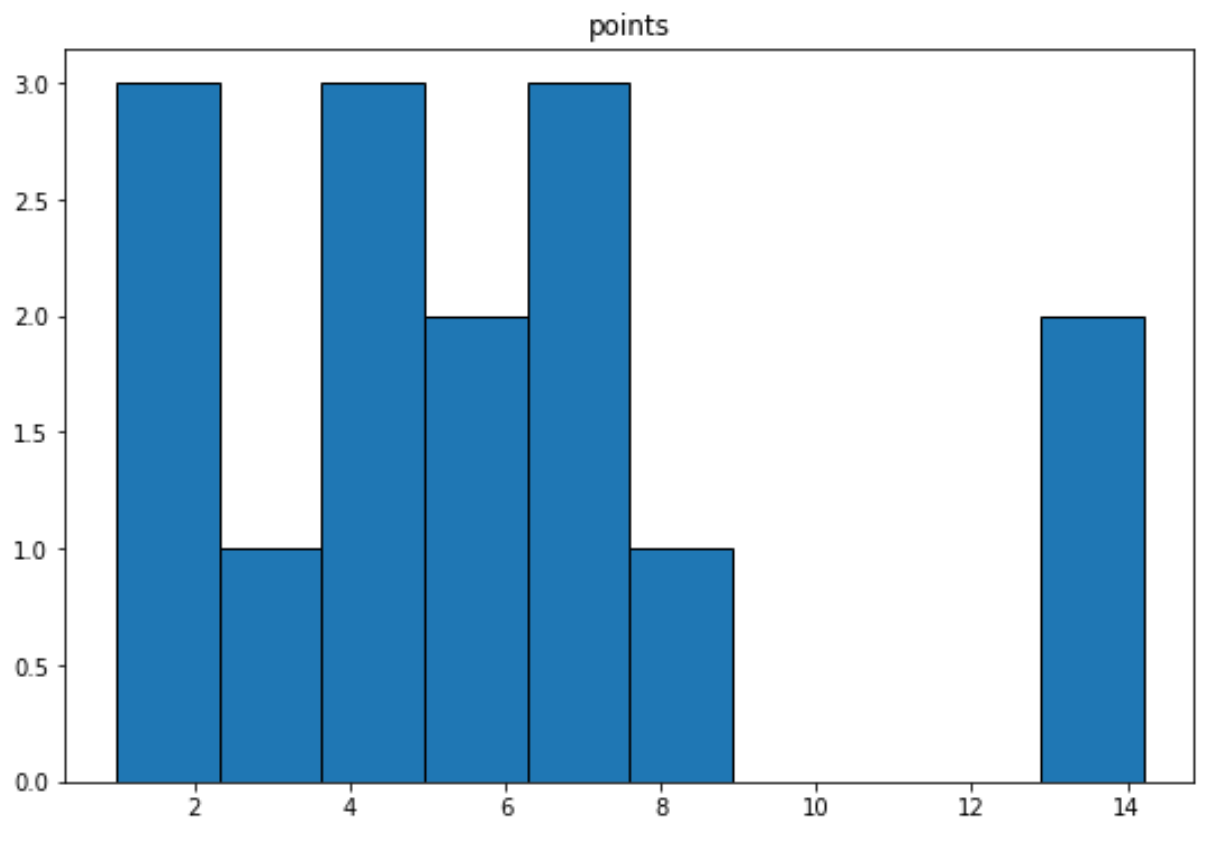
Connexe : Comment créer un histogramme à partir de Pandas DataFrame
Nous pouvons utiliser la syntaxe suivante pour créer une courbe de densité pour la variable « points » :
import seaborn as sns sns.kdeplot(df['points'])
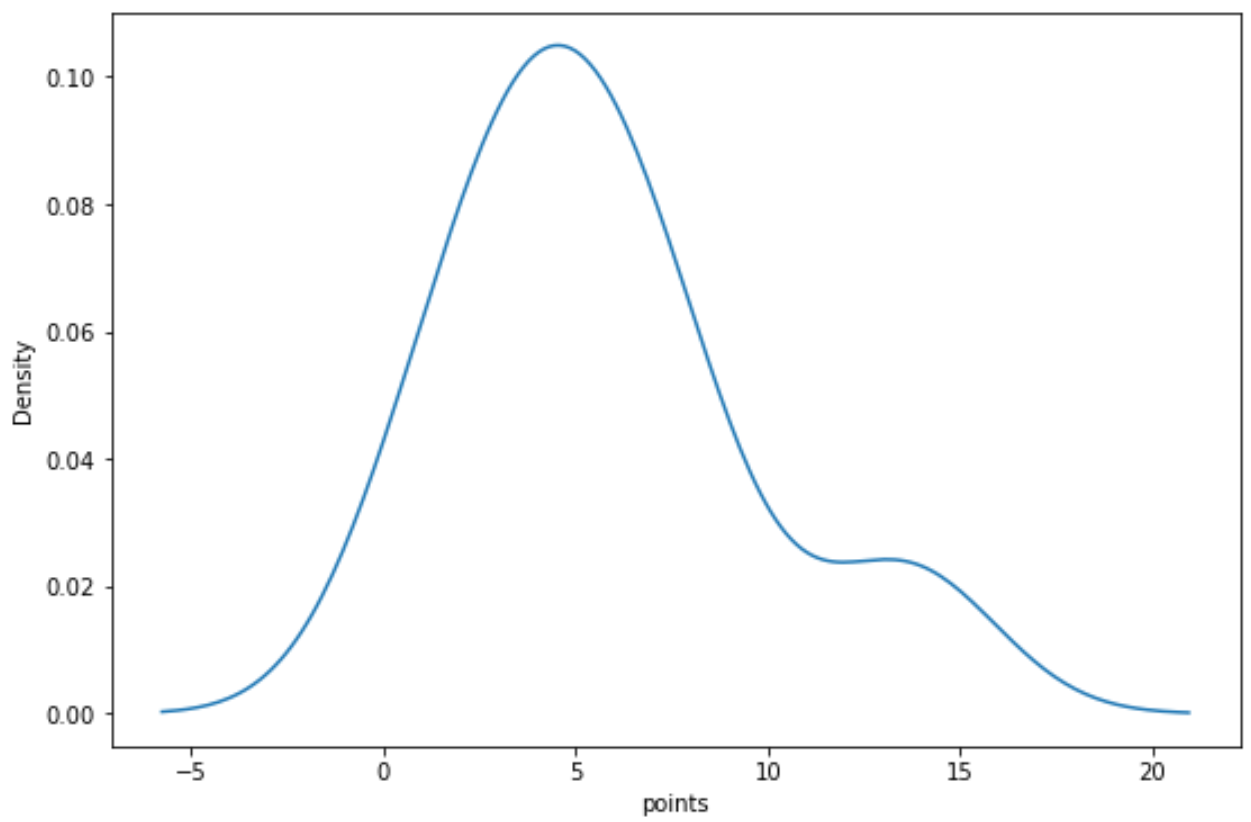
Connexe : Comment créer un tracé de densité dans Matplotlib
Chacun de ces graphiques nous offre une manière unique de visualiser la distribution des valeurs de la variable « points ».
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus