
Arbre de décision vs forêts aléatoires : quelle est la différence ?
Un arbre de décision est un type de modèle d’apprentissage automatique utilisé lorsque la relation entre un ensemble de variables prédictives et une variable de réponse est non linéaire.
L’idée de base derrière un arbre de décision est de construire un « arbre » en utilisant un ensemble de variables prédictives qui prédit la valeur d’une variable de réponse à l’aide de règles de décision.
Par exemple, nous pourrions utiliser les variables prédictives « années de jeu » et « circuits moyens » pour prédire le salaire annuel des joueurs de baseball professionnels.
En utilisant cet ensemble de données, voici à quoi pourrait ressembler le modèle d’arbre de décision :
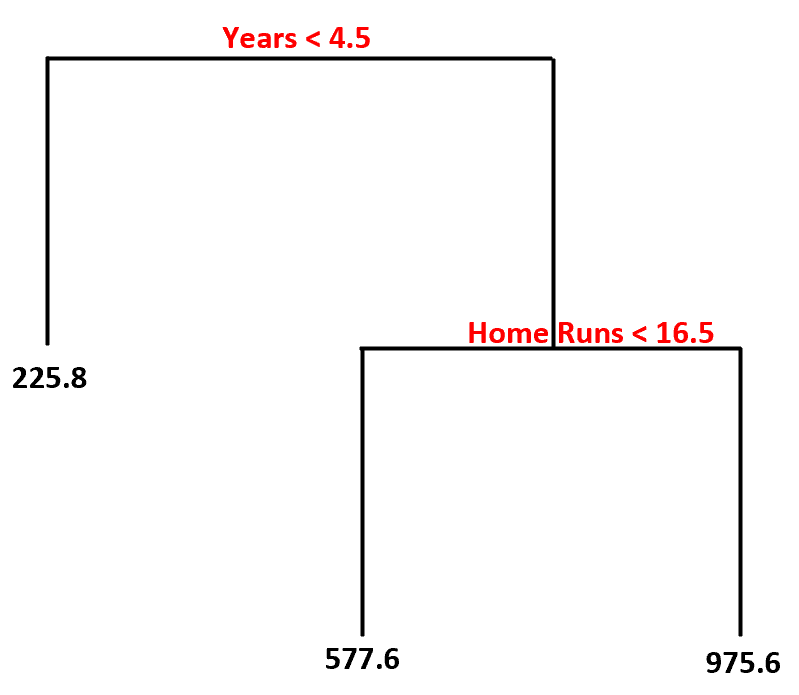
Voici comment nous interpréterions cet arbre de décision :
- Les joueurs ayant joué moins de 4,5 ans ont un salaire prévu de 225,8 000 $ .
- Les joueurs ayant joué plus de 4,5 ans ou plus et moins de 16,5 circuits en moyenne ont un salaire prévu de 577,6 000 $ .
- Les joueurs avec une expérience supérieure ou égale à 4,5 ans et une moyenne supérieure ou égale à 16,5 circuits ont un salaire prévu de 975,6 000 $ .
Le principal avantage d’un arbre de décision est qu’il peut être adapté rapidement à un ensemble de données et que le modèle final peut être clairement visualisé et interprété à l’aide d’un diagramme « arborescent » comme celui ci-dessus.
Le principal inconvénient est qu’un arbre de décision a tendance à surajuster un ensemble de données d’entraînement, ce qui signifie qu’il est susceptible d’avoir de mauvaises performances sur des données invisibles. Cela peut également être fortement influencé par les valeurs aberrantes de l’ensemble de données.
Une extension de l’arbre de décision est un modèle connu sous le nom de forêt aléatoire , qui est essentiellement un ensemble d’arbres de décision.
Voici les étapes que nous utilisons pour créer un modèle de forêt aléatoire :
1. Prenez des échantillons bootstrapés à partir de l’ensemble de données d’origine.
2. Pour chaque échantillon bootstrap, créez un arbre de décision en utilisant un sous-ensemble aléatoire de variables prédictives.
3. Faites la moyenne des prédictions de chaque arbre pour obtenir un modèle final.
L’avantage des forêts aléatoires est qu’elles ont tendance à fonctionner bien mieux que les arbres de décision sur des données invisibles et qu’elles sont moins sujettes aux valeurs aberrantes.
L’inconvénient des forêts aléatoires est qu’il n’y a aucun moyen de visualiser le modèle final et leur construction peut prendre beaucoup de temps si vous ne disposez pas de suffisamment de puissance de calcul ou si l’ensemble de données avec lequel vous travaillez est extrêmement volumineux.
Avantages et inconvénients : arbres de décision par rapport aux forêts aléatoires
Le tableau suivant résume les avantages et les inconvénients des arbres de décision par rapport aux forêts aléatoires :
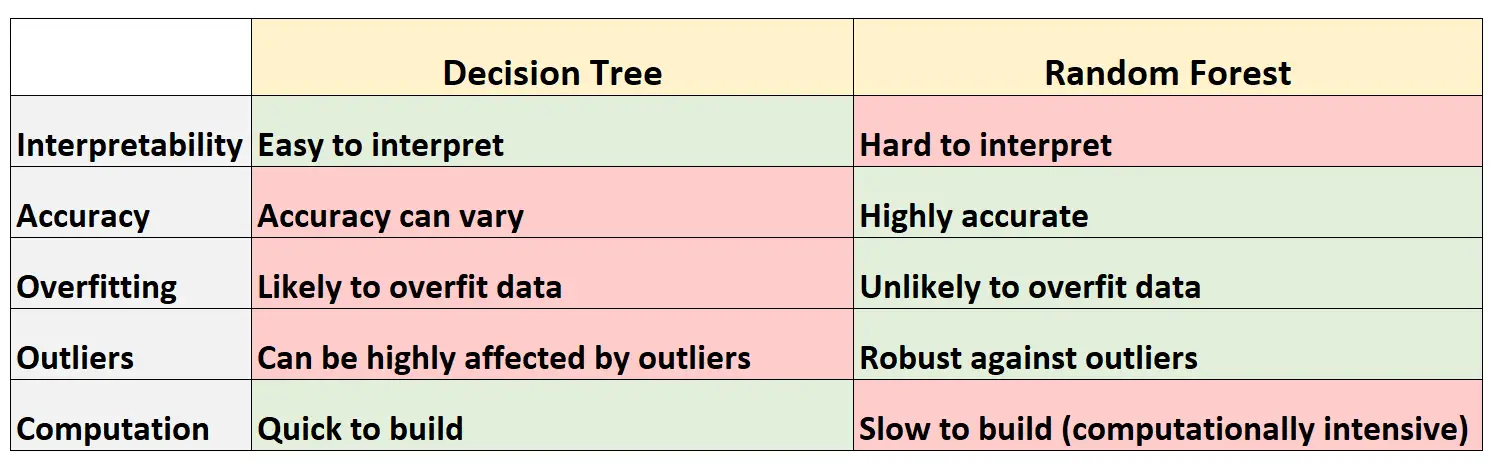
Voici une brève explication de chaque ligne du tableau :
1. Interprétabilité
Les arbres de décision sont faciles à interpréter car nous pouvons créer un diagramme arborescent pour visualiser et comprendre le modèle final.
À l’inverse, nous ne pouvons pas visualiser une forêt aléatoire et il peut souvent être difficile de comprendre comment le modèle final de forêt aléatoire prend des décisions.
2. Précision
Étant donné que les arbres de décision sont susceptibles de surajuster un ensemble de données d’entraînement, ils ont tendance à être moins performants sur des ensembles de données invisibles.
À l’inverse, les forêts aléatoires ont tendance à être très précises sur des ensembles de données invisibles, car elles évitent le surajustement des ensembles de données d’entraînement.
3. Surapprentissage
Comme mentionné précédemment, les arbres de décision surajustent souvent les données d’entraînement : cela signifie qu’ils sont susceptibles de s’adapter au « bruit » d’un ensemble de données, par opposition au véritable modèle sous-jacent.
À l’inverse, étant donné que les forêts aléatoires n’utilisent que certaines variables prédictives pour construire chaque arbre de décision individuel, les arbres finaux ont tendance à être décorrélés, ce qui signifie qu’il est peu probable que les modèles de forêts aléatoires surajustent les ensembles de données.
4. Valeurs aberrantes
Les arbres de décision sont très susceptibles d’être affectés par des valeurs aberrantes.
À l’inverse, étant donné qu’un modèle de forêt aléatoire construit de nombreux arbres de décision individuels et prend ensuite la moyenne des prédictions de ces arbres, il est beaucoup moins susceptible d’être affecté par des valeurs aberrantes.
5. Calcul
Les arbres de décision peuvent être rapidement adaptés aux ensembles de données.
À l’inverse, les forêts aléatoires nécessitent beaucoup plus de calculs et peuvent prendre beaucoup de temps à créer en fonction de la taille de l’ensemble de données.
Quand utiliser des arbres de décision ou des forêts aléatoires
En règle générale :
Vous devez utiliser un arbre de décision si vous souhaitez créer rapidement un modèle non linéaire et pouvoir interpréter facilement la manière dont le modèle prend des décisions.
Cependant, vous devriez utiliser une forêt aléatoire si vous disposez de nombreuses capacités de calcul et si vous souhaitez créer un modèle susceptible d’être très précis sans vous soucier de la façon d’interpréter le modèle.
Dans le monde réel, les ingénieurs en apprentissage automatique et les data scientists utilisent souvent des forêts aléatoires parce qu’elles sont très précises et que les ordinateurs et systèmes modernes peuvent souvent gérer de grands ensembles de données qui ne pouvaient pas être gérés auparavant.
Ressources additionnelles
Les didacticiels suivants fournissent une introduction aux arbres de décision et aux modèles de forêt aléatoire :
Les didacticiels suivants expliquent comment ajuster les arbres de décision et les forêts aléatoires dans R :
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus