
Comment centrer les données dans R (avec exemples)
Centrer un ensemble de données signifie soustraire la valeur moyenne de chaque observation individuelle dans l’ensemble de données.
Par exemple, supposons que nous ayons l’ensemble de données suivant :
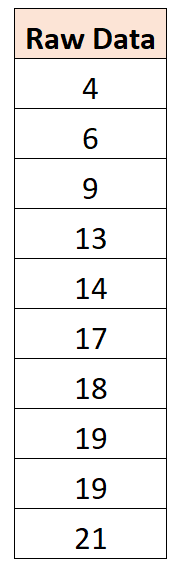
Il s’avère que la valeur moyenne est de 14. Ainsi, pour centrer cet ensemble de données, nous soustrairions 14 à chaque observation individuelle :
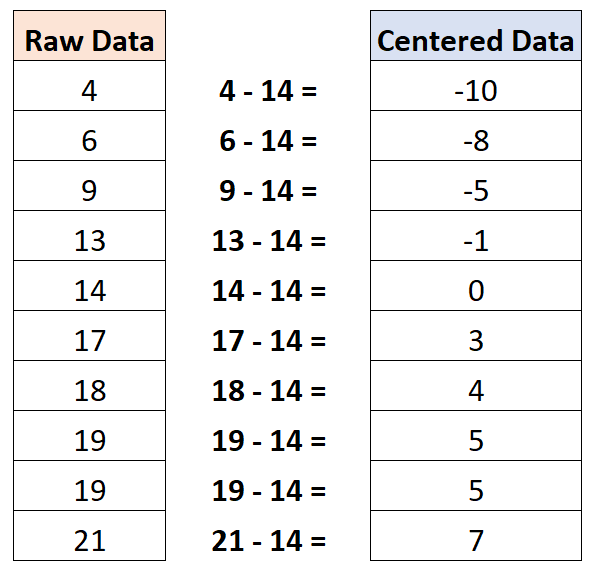
Notez que la valeur moyenne de l’ensemble de données centré est nulle.
Ce didacticiel fournit plusieurs exemples sur la manière de centrer les données dans R.
Exemple 1 : Centrer les valeurs d’un vecteur
Le code suivant montre comment utiliser la fonction scale() de la base R pour centrer les valeurs dans un vecteur :
#create vector data <- c(4, 6, 9, 13, 14, 17, 18, 19, 19, 21) #subtract the mean value from each observation in the vector scale(data, scale=FALSE) [,1] [1,] -10 [2,] -8 [3,] -5 [4,] -1 [5,] 0 [6,] 3 [7,] 4 [8,] 5 [9,] 5 [10,] 7 attr(,"scaled:center") [1] 14
Les valeurs résultantes sont les valeurs centrées de l’ensemble de données. La fonction scale() nous indique également que la valeur moyenne de l’ensemble de données est de 14.
Notez que la fonction scale() , par défaut, soustrait la moyenne de chaque observation individuelle, puis la divise par l’écart type.
En spécifiant scale=FALSE , nous disons à R de ne pas diviser par l’écart type.
Exemple 2 : centrer les colonnes dans un bloc de données
Le code suivant montre comment utiliser la fonction sapply() et la fonction scale() de la base R pour centrer les valeurs de chaque colonne d’un bloc de données :
#create data frame df <- data.frame(x = c(1, 4, 5, 6, 6, 8, 9), y = c(7, 7, 8, 8, 8, 9, 12), z = c(3, 3, 4, 4, 6, 7, 7)) #center each column in the data frame df_new <- sapply(df, function(x) scale(x, scale=FALSE)) #display data frame df_new x y z [1,] -4.5714286 -1.4285714 -1.8571429 [2,] -1.5714286 -1.4285714 -1.8571429 [3,] -0.5714286 -0.4285714 -0.8571429 [4,] 0.4285714 -0.4285714 -0.8571429 [5,] 0.4285714 -0.4285714 1.1428571 [6,] 2.4285714 0.5714286 2.1428571 [7,] 3.4285714 3.5714286 2.1428571
Nous pouvons vérifier que la moyenne de chaque colonne du nouveau bloc de données est égale à zéro en utilisant la fonction colMeans() :
colMeans(df_new)
x y z
2.537653e-16 -2.537653e-16 3.806479e-16
Les valeurs sont indiquées en notation scientifique, mais chaque valeur est essentiellement égale à zéro.
Ressources additionnelles
Comment faire la moyenne sur les colonnes dans R
Comment additionner des colonnes spécifiques dans R
Comment supprimer les valeurs aberrantes de plusieurs colonnes dans R
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus