适用性测试
本文解释什么是拟合优度检验以及它在统计学中的用途。它还展示了如何执行适合性测试,此外,您将能够看到逐步解决的练习。
什么是适合性测试?
拟合优度检验是一种统计检验,可让我们确定数据样本是否符合特定的概率分布。换句话说,充分性检验用于检查观测数据是否与预期数据相对应。
我们经常尝试对一种现象进行预测,因此,我们对我们认为会发生的所述现象有预期值。然而,我们必须收集数据并检查收集的数据是否符合我们的预期。因此,充分性测试使我们能够使用统计标准来决定预期数据和观察到的数据是否相似。
因此,拟合优度检验是一种假设检验,其零假设是观测值等于期望值,另一方面,检验的备择假设表明观测值在统计上不同从预期值。
![\begin{cases}H_0: f(x)=f_o(x)\\[2ex]H_1: f(x)\neq f_o(x)\end{cases}](https://statorials.org/wp-content/ql-cache/quicklatex.com-db79847cd8097a2baca298bf82594f4f_l3.png "Rendered by QuickLaTeX.com")
在统计学中,拟合优度检验也称为卡方检验,因为检验的参考分布是卡方分布。
适合度检验公式
拟合优度检验统计量等于观测值与期望值之差的平方和除以期望值。
因此,充分性检验的公式如下:

金子:
-

是拟合优度检验统计量,遵循卡方分布

自由程度。
-

是数据样本大小。
-

是数据 i 的观测值。
-

是数据 i 的期望值。
因此,给定显着性水平

,计算出的检验统计量应与临界检验值进行比较,以确定是否拒绝假设检验的原假设或备择假设:
- 如果检验统计量小于临界值

,拒绝备择假设(并接受原假设)。
- 如果检验统计量大于临界值
,拒绝原假设(并接受备择假设)。
![\begin{array}{l}\text{Si } \chi^2<\chi^2_{1-\alpha|k-1}\text{ se rechaza } H_1\\[3ex]\text{Si } \chi^2>\chi^2_{1-\alpha|k-1}\text{ se rechaza } H_0\end{array}” title=”Rendered by QuickLaTeX.com” height=”70″ width=”243″ style=”vertical-align: 0px;”></p>
</p>
<h2 class=](https://statorials.org/wp-content/ql-cache/quicklatex.com-6b48f7bb620dca865b7e652e81cc247a_l3.png) 如何进行适合性测试
如何进行适合性测试
要进行适用性测试,应遵循以下步骤:
- 我们首先建立拟合优度检验的原假设和备择假设。
- 其次,我们选择拟合优度检验的置信水平,从而选择显着性水平。
- 接下来,我们计算拟合优度检验统计量,其公式可以在上面的部分中找到。
- 我们使用卡方分布表找到拟合优度检验的临界值。
- 我们将检验统计量与临界值进行比较:
- 如果检验统计量小于临界值,则拒绝备择假设(并接受原假设)。
- 如果检验统计量大于临界值,则拒绝原假设(并接受备择假设)。
充分性测试示例
- 一位商店老板说,她的销售额的 50% 是产品 A,她的销售额的 35% 是产品 B,而她的销售额的 15% 是产品 C。但是,每种产品的销售数量如下表所示:如下表。分析业主的理论数据与实际收集的数据是否存在统计差异。
| 产品 | 观察到的销售额 (O i ) |
|---|---|
| 产品A | 第453章 |
| 产品B | 268 |
| 产品C | 79 |
| 全部的 | 800 |
为了确定观测值是否等于期望值,我们将进行拟合优度检验。检验的原假设和备择假设为:
在本例中,我们将使用 95% 的置信水平进行检验,因此显着性水平将为 5%。

要找到预期销售值,我们需要将每种产品的预期销售额百分比乘以总销售额:
![\begin{array}{c}E_A=800\cdot 0,50=400\\[2ex]E_B=800\cdot 0,35=280\\[2ex]E_A=800\cdot 0,15=120\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-9daef735efca126bba60ccde38423d7b_l3.png "Rendered by QuickLaTeX.com")
因此,问题频率表如下:
| 产品 | 观察到的销售额 (O i ) | 预期销售额 (E i ) |
|---|---|---|
| 产品A | 第453章 | 400 |
| 产品B | 268 | 280 |
| 产品C | 79 | 120 |
| 全部的 | 800 | 800 |
现在我们已经计算了所有值,我们应用卡方检验公式来计算检验统计量:
![\begin{array}{c}\displaystyle\chi^2=\sum_{i=1}^k\frac{(O_i-E_i)^2}{E_i}\\[6ex]\chi^2=\cfrac{(453-400)^2}{400}+\cfrac{(268-280)^2}{280}+\cfrac{(79-120)^2}{120}\\[6ex]\chi^2=7,02+0,51+14,00\\[6ex]\chi^2=21,53\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-8c76621fbe8504217dfe8ac55b2d6e67_l3.png "Rendered by QuickLaTeX.com")
一旦计算出检验统计量的值,我们就使用卡方分布表来查找检验的临界值。卡方分布有

自由度和重要性水平是
,然而:
![\begin{array}{c}\chi^2_{1-\alpha|k-1}=\ \color{orange}\bm{?}\color{black}\\[4ex]\chi^2_{0,95|2}=5,991\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-1850e764fc71b1e7b49b0c4d8133ab89_l3.png "Rendered by QuickLaTeX.com")
因此,检验统计量 (21.53) 大于临界检验值 (5.991),因此拒绝原假设并接受备择假设。这意味着数据有很大差异,因此店主预期的销售额与实际销售额不同。
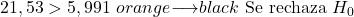
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多