
COVARIANCE.P vs COVARIANCE.S dans Excel : quelle est la différence ?
En statistiques, la covariance est un moyen de mesurer la façon dont les changements dans une variable sont associés aux changements dans une autre variable.
Une valeur positive de covariance indique qu’une augmentation d’une variable est associée à une augmentation d’une autre variable.
Une valeur négative indique qu’une augmentation d’une variable est associée à une diminution d’une autre variable.
Il existe deux fonctions différentes que vous pouvez utiliser pour calculer la covariance dans Excel :
1. COVARIANCE.P : Cette fonction calcule la covariance de la population. Utilisez cette fonction lorsque la plage de valeurs représente l’ensemble de la population.
Cette fonction utilise la formule suivante :
Covariance de la population = Σ(x i – x )(y i – y ) / n
où:
- Σ : Un symbole grec qui signifie « somme »
- x i : La i ème valeur de la variable x
- x : La valeur moyenne de la variable x
- y i : la ième valeur de la variable y
- y : La valeur moyenne de la variable y
- n : Le nombre total d’observations
2. COVARIANCE.S : Cette fonction calcule la covariance de l’échantillon. Utilisez cette fonction lorsque la plage de valeurs représente un échantillon de valeurs plutôt qu’une population entière.
Cette fonction utilise la formule suivante :
Covariance de l’échantillon = Σ(x i – x )(y i – y ) / (n-1)
où:
- Σ : Un symbole grec qui signifie « somme »
- x i : La i ème valeur de la variable x
- x : La valeur moyenne de la variable x
- y i : la ième valeur de la variable y
- y : La valeur moyenne de la variable y
- n : Le nombre total d’observations
Remarquez la différence subtile entre les deux formules : COVARIANCE.P divise par n tandis que COVARIANCE.S divise par n-1 .
Pour cette raison, la formule COVARIANCE.S produira toujours une valeur plus grande car elle divise par une valeur plus petite.
L’exemple suivant montre comment utiliser chaque formule dans la pratique.
Exemple : COVARIANCE.P vs COVARIANCE.S dans Excel
Supposons que nous disposions de l’ensemble de données suivant dans Excel qui montre les points et les passes décisives de 15 joueurs de basket-ball différents :
La capture d’écran suivante montre comment calculer la covariance entre les points et les assistances à l’aide des deux formules de covariance différentes :
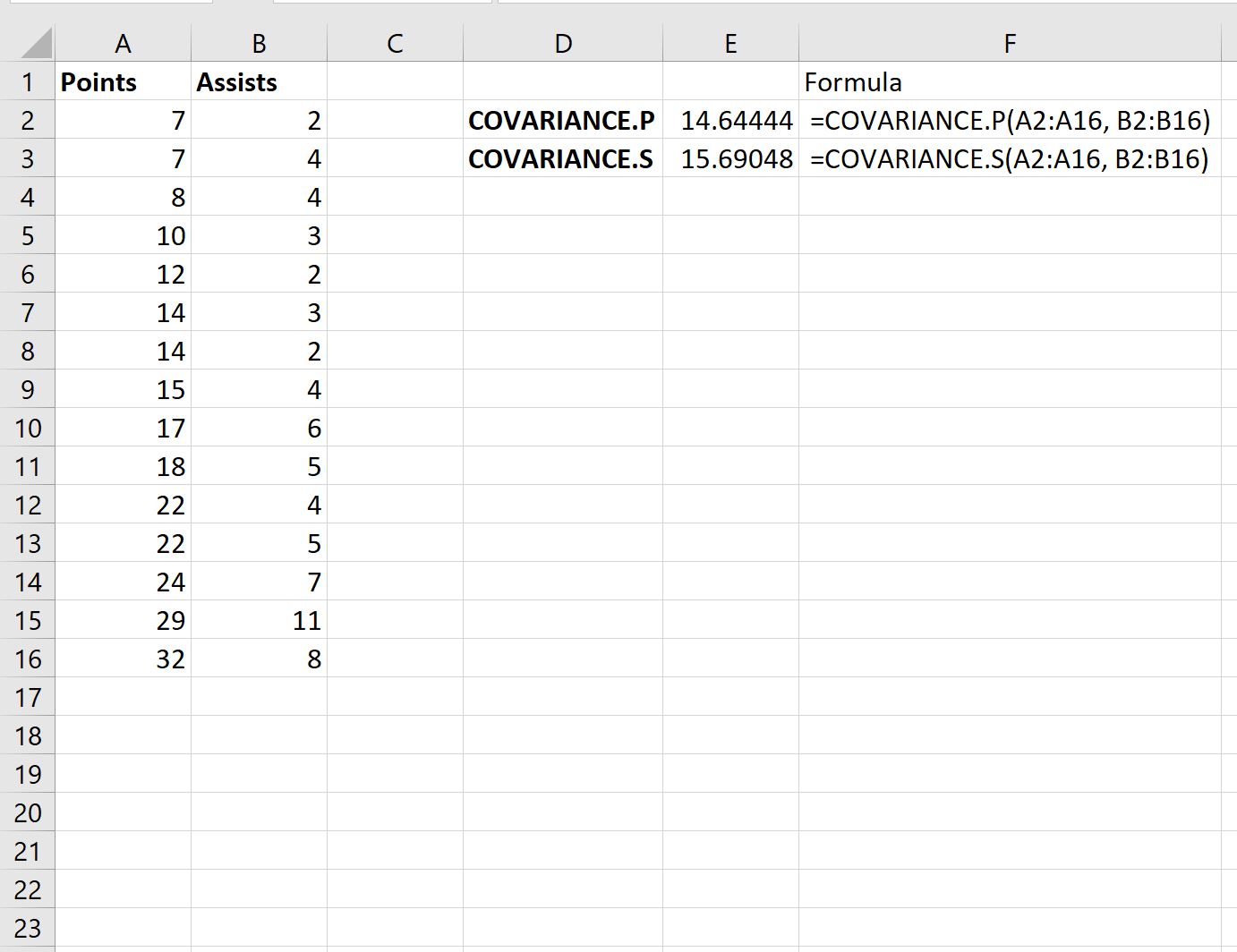
La covariance de l’échantillon s’avère être de 15,69 et la covariance de la population s’avère être de 14,64 .
Comme mentionné précédemment, la covariance de l’échantillon sera toujours plus grande que la covariance de la population.
Quand utiliser COVARIANCE.P ou COVARIANCE.S
Dans la plupart des cas, nous ne sommes pas en mesure de collecter des données pour une population entière. Nous collectons donc des données uniquement pour un échantillon de la population.
Ainsi, nous utilisons presque toujours COVARIANCE.S pour calculer la covariance d’un ensemble de données car notre ensemble de données représente généralement un échantillon.
Dans les rares cas où vos données représentent une population entière, vous pouvez utiliser la fonction COVARIANCE.P à la place.
Ressources additionnelles
Les didacticiels suivants expliquent la différence entre les autres fonctions Excel couramment utilisées :
STDEV.P vs STDEV.S dans Excel : quelle est la différence ?
PERCENTILE.EXC vs PERCENTILE.INC dans Excel : quelle est la différence ?
QUARTILE.EXC vs QUARTILE.INC dans Excel : quelle est la différence ?
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus