
Comment calculer la distance du cuisinier en Python
La distance de Cook est utilisée pour identifier les observations influentes dans un modèle de régression.
La formule de la distance de Cook est la suivante :
ré je = (r je 2 / p*MSE) * (h ii / (1-h ii ) 2 )
où:
- r i est le i ème résidu
- p est le nombre de coefficients dans le modèle de régression
- MSE est l’erreur quadratique moyenne
- h ii est la ième valeur de levier
Essentiellement, la distance de Cook mesure dans quelle mesure toutes les valeurs ajustées du modèle changent lorsque la i ème observation est supprimée.
Plus la valeur de la distance de Cook est grande, plus une observation donnée est influente.
En règle générale, toute observation dont la distance de Cook est supérieure à 4/n (où n = observations totales) est considérée comme ayant une grande influence.
Ce didacticiel fournit un exemple étape par étape de la façon de calculer la distance de Cook pour un modèle de régression donné en Python.
Étape 1 : Saisissez les données
Tout d’abord, nous allons créer un petit ensemble de données avec lequel travailler en Python :
import pandas as pd #create dataset df = pd.DataFrame({'x': [8, 12, 12, 13, 14, 16, 17, 22, 24, 26, 29, 30], 'y': [41, 42, 39, 37, 35, 39, 45, 46, 39, 49, 55, 57]})
Étape 2 : Ajuster le modèle de régression
Ensuite, nous ajusterons un modèle de régression linéaire simple :
import statsmodels.api as sm
#define response variable
y = df['y']
#define explanatory variable
x = df['x']
#add constant to predictor variables
x = sm.add_constant(x)
#fit linear regression model
model = sm.OLS(y, x).fit()
Étape 3 : Calculer la distance du cuisinier
Ensuite, nous calculerons la distance de Cook pour chaque observation du modèle :
#suppress scientific notation
import numpy as np
np.set_printoptions(suppress=True)
#create instance of influence
influence = model.get_influence()
#obtain Cook's distance for each observation
cooks = influence.cooks_distance
#display Cook's distances
print(cooks)
(array([0.368, 0.061, 0.001, 0.028, 0.105, 0.022, 0.017, 0. , 0.343,
0. , 0.15 , 0.349]),
array([0.701, 0.941, 0.999, 0.973, 0.901, 0.979, 0.983, 1. , 0.718,
1. , 0.863, 0.713]))
Par défaut, la fonction cuisiniers_distance() affiche un tableau de valeurs pour la distance de Cook pour chaque observation suivi d’un tableau de valeurs p correspondantes.
Par exemple:
- Distance de Cook pour l’observation n°1 : 0,368 (valeur p : 0,701)
- Distance de Cook pour l’observation n°2 : 0,061 (valeur p : 0,941)
- Distance de Cook pour l’observation n°3 : 0,001 (valeur p : 0,999)
Et ainsi de suite.
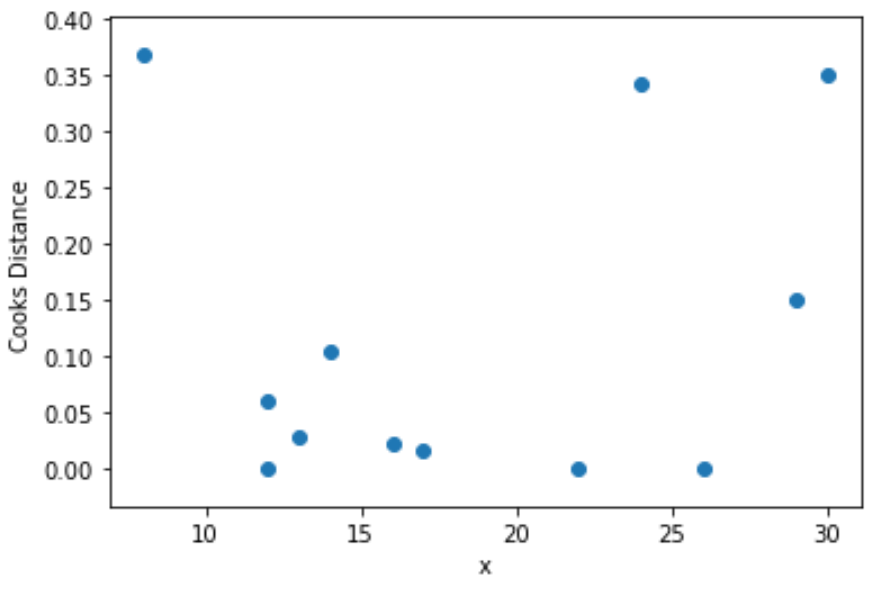
Étape 4 : Visualisez les distances du cuisinier
Enfin, nous pouvons créer un nuage de points pour visualiser les valeurs de la variable prédictive en fonction de la distance de Cook pour chaque observation :
import matplotlib.pyplot as plt
plt.scatter(df.x, cooks[0])
plt.xlabel('x')
plt.ylabel('Cooks Distance')
plt.show()
Pensées finales
Il est important de noter que la distance de Cook doit être utilisée pour identifier les observations potentiellement influentes. Ce n’est pas parce qu’une observation est influente qu’elle doit être supprimée de l’ensemble de données.
Tout d’abord, vous devez vérifier que l’observation n’est pas le résultat d’une erreur de saisie de données ou d’un autre événement étrange. S’il s’avère qu’il s’agit d’une valeur légitime, vous pouvez alors décider s’il est approprié de la supprimer, de la laisser telle quelle ou simplement de la remplacer par une valeur alternative comme la médiane.
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus