
Comment déterminer les variables significatives dans les modèles de régression
L’une des principales questions que vous vous poserez après avoir ajusté un modèle de régression linéaire multiple est la suivante : quelles variables sont significatives ?
Il existe deux méthodes que vous ne devez pas utiliser pour déterminer la signification d’une variable :
1. La valeur des coefficients de régression
Un coefficient de régression pour une variable prédictive donnée vous indique la variation moyenne de la variable de réponse associée à une augmentation d’une unité de cette variable prédictive.
Cependant, chaque variable prédictive d’un modèle est généralement mesurée sur une échelle différente. Il n’est donc pas logique de comparer les valeurs absolues des coefficients de régression pour déterminer quelles variables sont les plus importantes.
2. Les valeurs p des coefficients de régression
Les valeurs p des coefficients de régression peuvent vous indiquer si une variable prédictive donnée a une association statistiquement significative avec la variable de réponse, mais elles ne peuvent pas vous dire si une variable prédictive donnée est pratiquement significative dans le monde réel.
Les valeurs P peuvent également être faibles en raison d’une grande taille d’échantillon ou d’une faible variabilité, ce qui ne nous indique pas réellement si une variable prédictive donnée est ou non significative dans la pratique.
Cependant, il existe deux méthodes que vous devez utiliser pour déterminer la signification des variables :
1. Coefficients de régression standardisés
Généralement, lorsque nous effectuons une régression linéaire multiple, les coefficients de régression résultants dans la sortie du modèle ne sont pas standardisés , ce qui signifie qu’ils utilisent les données brutes pour trouver la droite la mieux ajustée.
Cependant, il est possible de standardiser chaque variable prédictive et la variable de réponse (en soustrayant la valeur moyenne de chaque variable des valeurs d’origine, puis en la divisant par l’écart type des variables), puis d’effectuer une régression, ce qui aboutit à des coefficients de régression standardisés .
En standardisant chaque variable du modèle, chaque variable est mesurée sur la même échelle. Il est donc logique de comparer les valeurs absolues des coefficients de régression dans les résultats pour comprendre quelles variables ont le plus grand effet sur la variable de réponse.
2. Expertise en la matière
Bien que les valeurs p puissent vous indiquer s’il existe un effet statistiquement significatif entre une variable prédictive donnée et la variable de réponse, une expertise en la matière est nécessaire pour confirmer si une variable prédictive est réellement pertinente et doit réellement être incluse dans un modèle.
L’exemple suivant montre comment déterminer en pratique les variables significatives dans un modèle de régression.
Exemple : Comment déterminer les variables significatives dans un modèle de régression
Supposons que nous disposions de l’ensemble de données suivant contenant des informations sur l’âge, la superficie en pieds carrés et le prix de vente de 12 maisons :
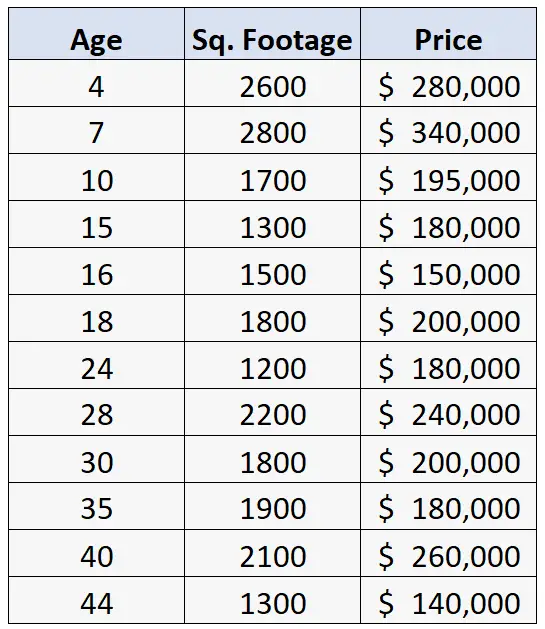
Supposons que nous effectuions ensuite une régression linéaire multiple, en utilisant l’âge et la superficie en pieds carrés comme variables prédictives et le prix comme variable de réponse.
Nous recevons le résultat suivant :

Les coefficients de régression de ce tableau ne sont pas standardisés , ce qui signifie qu’ils ont utilisé les données brutes pour ajuster ce modèle de régression.
À première vue, il semble que l’âge ait un effet beaucoup plus important sur le prix de l’immobilier puisque son coefficient dans le tableau de régression est de -409,833 , contre seulement 100,866 pour la variable prédictive superficie en pieds carrés .
Cependant, l’erreur type est beaucoup plus grande pour l’âge que pour la superficie en pieds carrés, c’est pourquoi la valeur p correspondante est en réalité grande pour l’âge (p = 0,520) et petite pour la superficie en pieds carrés (p = 0,000).
La raison des différences extrêmes dans les coefficients de régression est due aux différences extrêmes dans les échelles pour les deux variables :
- Les valeurs pour l’âge vont de 4 à 44 ans.
- Les valeurs de superficie en pieds carrés varient de 1 200 à 2 800.
Supposons que nous normalisions plutôt les données brutes :
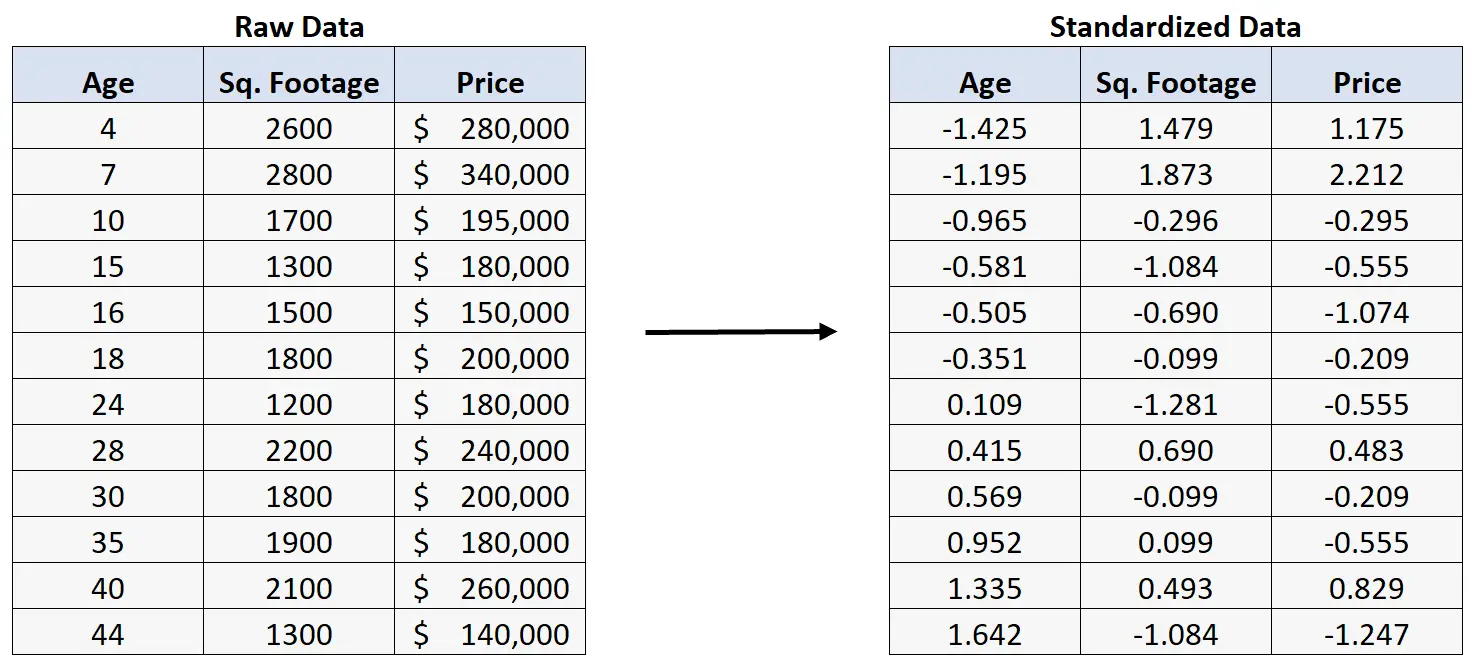
Si nous effectuons ensuite une régression linéaire multiple en utilisant les données standardisées, nous obtiendrons le résultat de régression suivant :

Les coefficients de régression de ce tableau sont standardisés , ce qui signifie qu’ils ont utilisé des données standardisées pour s’adapter à ce modèle de régression.
La façon d’interpréter les coefficients du tableau est la suivante :
- Une augmentation de l’ âge d’un écart type est associée à une diminution de 0,092 écart type du prix de l’immobilier, en supposant que la superficie en pieds carrés reste constante.
- Une augmentation d’un écart type de la superficie en pieds carrés est associée à une augmentation de 0,885 écart type du prix de l’immobilier, en supposant que l’âge reste constant.
Nous pouvons désormais constater que la superficie en pieds carrés a un effet beaucoup plus important sur le prix de l’immobilier que l’âge.
Remarque : Les valeurs p pour chaque variable prédictive sont exactement les mêmes que celles du modèle de régression précédent.
Au moment de décider du modèle final à utiliser, nous savons désormais que la superficie en pieds carrés est beaucoup plus importante pour prédire le prix d’une maison que son âge .
En fin de compte, nous devrons utiliser notre expertise en la matière pour déterminer les variables à inclure dans le modèle final, sur la base des connaissances existantes sur les prix de l’immobilier et de l’immobilier.
Ressources additionnelles
Les didacticiels suivants fournissent des informations supplémentaires sur les modèles de régression :
Comment lire et interpréter un tableau de régression
Comment interpréter les coefficients de régression
Comment interpréter les valeurs P dans la régression linéaire
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus