
Comment calculer les DFFITS dans R
En statistiques, nous souhaitons souvent savoir quelle est l’influence des différentes observations dans les modèles de régression.
Une façon de calculer l’influence des observations consiste à utiliser une métrique connue sous le nom de DFFITS , qui signifie « différence d’ajustements ».
Cette métrique nous indique dans quelle mesure les prédictions faites par un modèle de régression changent lorsque nous omettons une observation individuelle.
Ce didacticiel montre un exemple étape par étape de la façon de calculer et de visualiser DFFITS pour chaque observation dans un modèle dans R.
Étape 1 : Créer un modèle de régression
Tout d’abord, nous allons créer un modèle de régression linéaire multiple à l’aide de l’ensemble de données mtcars intégré dans R :
#load the dataset data(mtcars) #fit a regression model model <- lm(mpg~disp+hp, data=mtcars) #view model summary summary(model) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 30.735904 1.331566 23.083 < 2e-16 *** disp -0.030346 0.007405 -4.098 0.000306 *** hp -0.024840 0.013385 -1.856 0.073679 . --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.127 on 29 degrees of freedom Multiple R-squared: 0.7482, Adjusted R-squared: 0.7309 F-statistic: 43.09 on 2 and 29 DF, p-value: 2.062e-09
Étape 2 : Calculer les DFFITS pour chaque observation
Ensuite, nous utiliserons la fonction intégrée dffits() pour calculer la valeur DFFITS pour chaque observation du modèle :
#calculate DFFITS for each observation in the model dffits <- as.data.frame(dffits(model)) #display DFFITS for each observation dffits dffits(model) Mazda RX4 -0.14633456 Mazda RX4 Wag -0.14633456 Datsun 710 -0.19956440 Hornet 4 Drive 0.11540062 Hornet Sportabout 0.32140303 Valiant -0.26586716 Duster 360 0.06282342 Merc 240D -0.03521572 Merc 230 -0.09780612 Merc 280 -0.22680622 Merc 280C -0.32763355 Merc 450SE -0.09682952 Merc 450SL -0.03841129 Merc 450SLC -0.17618948 Cadillac Fleetwood -0.15860270 Lincoln Continental -0.15567627 Chrysler Imperial 0.39098449 Fiat 128 0.60265798 Honda Civic 0.35544919 Toyota Corolla 0.78230167 Toyota Corona -0.25804885 Dodge Challenger -0.16674639 AMC Javelin -0.20965432 Camaro Z28 -0.08062828 Pontiac Firebird 0.67858692 Fiat X1-9 0.05951528 Porsche 914-2 0.09453310 Lotus Europa 0.55650363 Ford Pantera L 0.31169050 Ferrari Dino -0.29539098 Maserati Bora 0.76464932 Volvo 142E -0.24266054
En règle générale, nous examinons de plus près les observations dont les valeurs DFFITS sont supérieures à un seuil de 2√ p/n où :
- p : Nombre de variables prédictives utilisées dans le modèle
- n : Nombre d’observations utilisées dans le modèle
Dans cet exemple, le seuil serait de 0,5 :
#find number of predictors in model p <- length(model$coefficients)-1 #find number of observations n <- nrow(mtcars) #calculate DFFITS threshold value thresh <- 2*sqrt(p/n) thresh [1] 0.5
Nous pouvons trier les observations en fonction de leurs valeurs DFFITS pour voir si l’une d’entre elles dépasse le seuil :
#sort observations by DFFITS, descending dffits[order(-dffits['dffits(model)']), ] [1] 0.78230167 0.76464932 0.67858692 0.60265798 0.55650363 0.39098449 [7] 0.35544919 0.32140303 0.31169050 0.11540062 0.09453310 0.06282342 [13] 0.05951528 -0.03521572 -0.03841129 -0.08062828 -0.09682952 -0.09780612 [19] -0.14633456 -0.14633456 -0.15567627 -0.15860270 -0.16674639 -0.17618948 [25] -0.19956440 -0.20965432 -0.22680622 -0.24266054 -0.25804885 -0.26586716 [31] -0.29539098 -0.32763355
Nous pouvons voir que les cinq premières observations ont une valeur DFFITS supérieure à 0,5, ce qui signifie que nous souhaiterons peut-être étudier ces observations de plus près pour déterminer si elles ont une grande influence sur le modèle.
Étape 3 : Visualisez les DFFITS pour chaque observation
Enfin, nous pouvons créer un graphique rapide pour visualiser les DFFITS pour chaque observation :
#plot DFFITS values for each observation plot(dffits(model), type = 'h') #add horizontal lines at absolute values for threshold abline(h = thresh, lty = 2) abline(h = -thresh, lty = 2)
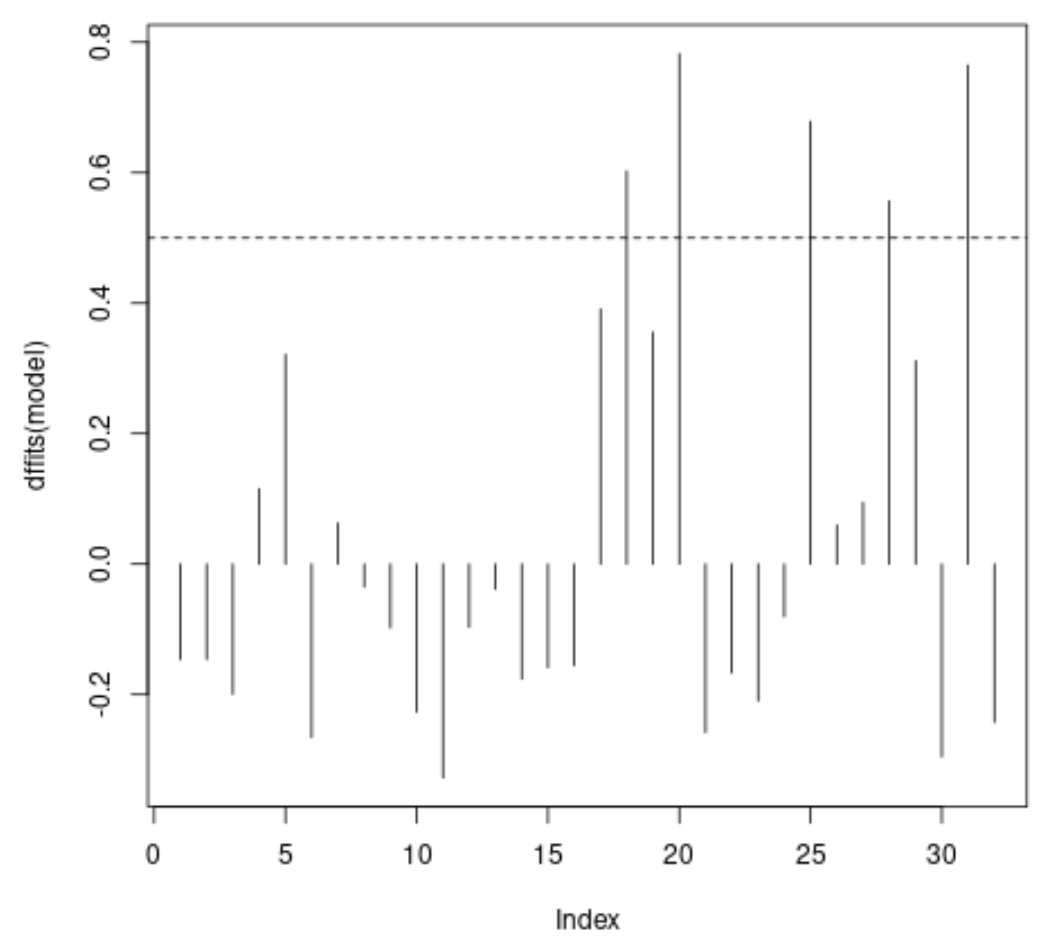
L’axe des x affiche l’indice de chaque observation dans l’ensemble de données et la valeur y affiche la valeur DFFITS correspondante pour chaque observation.
Ressources additionnelles
Comment effectuer une régression linéaire simple dans R
Comment effectuer une régression linéaire multiple dans R
Comment calculer les statistiques de levier dans R
Comment créer un tracé résiduel dans R
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus