
Qu’est-ce qu’une distribution ouverte ?
En statistiques, une distribution ouverte est une distribution de fréquence dans laquelle une ou plusieurs classes (ou « bacs ») sont ouvertes.
Par exemple, la distribution de fréquence suivante représente une distribution ouverte dans laquelle la plus petite classe est ouverte :
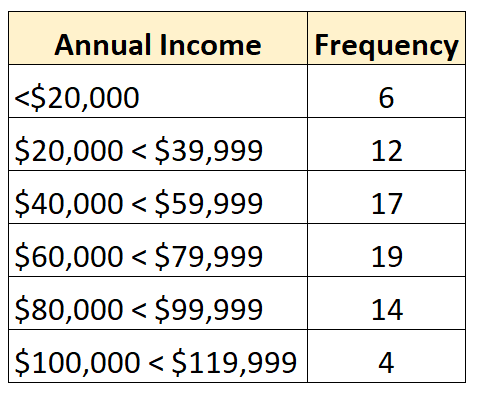
Et la distribution de fréquence suivante montre une distribution ouverte dans laquelle la plus grande classe est ouverte :
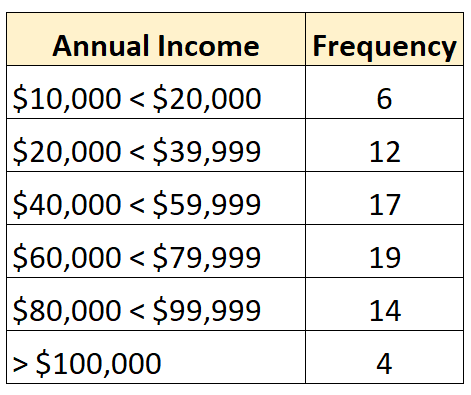
À l’inverse, une distribution fermée est une distribution dans laquelle chaque classe de la distribution de fréquences a une limite supérieure et inférieure, telle que la suivante :
Quelles sont les causes des distributions ouvertes ?
Les distributions ouvertes sont souvent le résultat du choix des chercheurs de collecter des données de telle manière que l’une des classes finit par être ouverte.
Par exemple, supposons qu’un chercheur interroge les habitants d’une certaine ville et leur pose des questions sur le revenu annuel de leur ménage.
Le chercheur peut choisir de donner la réponse la plus large possible « > 100 000 $ », car il sait que les résidents à revenu élevé peuvent ne pas être à l’aise de partager combien ils gagnent si celui-ci est nettement supérieur à 100 000 $.
À l’inverse, le chercheur peut choisir de donner la réponse la plus courte possible, car il sait que les résidents qui gagnent très peu ne seront pas non plus à l’aise de partager le peu qu’ils gagnent.
En un mot, les chercheurs incluent souvent des cours ouverts dans leurs enquêtes parce qu’ils souhaitent maximiser le nombre de personnes se sentant à l’aise pour répondre aux questions de l’enquête.
Le problème avec les distributions ouvertes
Le problème avec les distributions ouvertes est que les vraies données sont censurées . En d’autres termes, nous pouvons connaître le nombre de personnes qui gagnent plus de 100 000 $ dans une certaine ville, mais nous ne connaissons pas réellement leurs revenus annuels exacts.
Il est possible que certaines personnes gagnent 150 000 $, 250 000 $, 500 000 $ ou même plus, mais nous n’en avons aucune idée puisque chacune de ces personnes ne peut indiquer qu’elle gagne « > 100 000 $ » dans l’enquête.
Étant donné que les données sont censurées dans les distributions ouvertes, nous sommes également incapables de calculer la moyenne exacte et l’écart type des valeurs de l’ensemble de données puisque nous n’avons pas accès à toutes les valeurs des données brutes.
Comment analyser une distribution ouverte
Comme nous ne pouvons pas calculer la moyenne exacte d’une distribution ouverte, nous utilisons souvent la médiane comme mesure du « centre » de l’ensemble de données.
Rappelons que la médiane représente la valeur médiane de l’ensemble de données.
Lorsque nous travaillons avec des distributions ouvertes, nous pouvons utiliser la formule suivante pour trouver la meilleure estimation de la médiane :
Meilleure estimation de la médiane : L + ( (n/2 – F) / f ) * w
où:
- L : La limite inférieure du groupe médian
- n : Le nombre total d’observations
- F : La fréquence cumulée jusqu’au groupe médian
- f : La fréquence du groupe médian
- w : La largeur du groupe médian
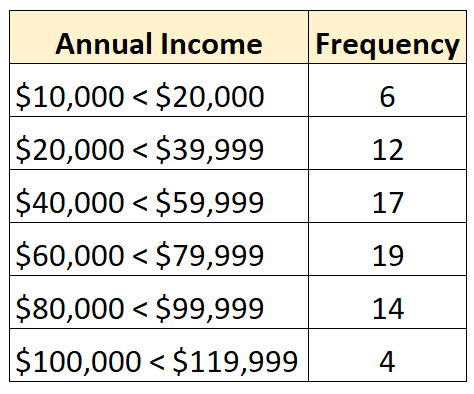
Par exemple, supposons que nous ayons la distribution ouverte suivante :
Il y a un total de 72 valeurs dans l’ensemble de données. Ainsi, nous savons que la valeur médiane sera située entre la valeur de la 36e et la 37e plus grande valeur de l’ensemble de données. Chacune de ces valeurs se situe dans la classe « 60 000 $ – 79 999 $ », nous savons donc que le revenu médian se situe dans cette fourchette.
Notre meilleure estimation de la médiane serait :
Médiane : 60 000 + ( (72/2 – 25) / 19 ) * 19 999 = 71 578 $
Cette valeur représente notre meilleure estimation du revenu annuel médian des individus figurant dans cet ensemble de données.
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus