
Qu’est-ce qui est considéré comme une donnée brute ? (Définition & Exemples)
En statistiques, les données brutes font référence aux données qui ont été collectées directement à partir d’une source primaire et qui n’ont été traitées d’aucune façon.
Dans tout type de projet d’analyse de données, la première étape consiste à collecter des données brutes. Une fois ces données collectées, elles peuvent ensuite être nettoyées, transformées, résumées et visualisées.
L’intérêt de collecter des données brutes est de pouvoir éventuellement les utiliser pour mieux comprendre certains phénomènes ou les utiliser pour construire un type de modèle prédictif.
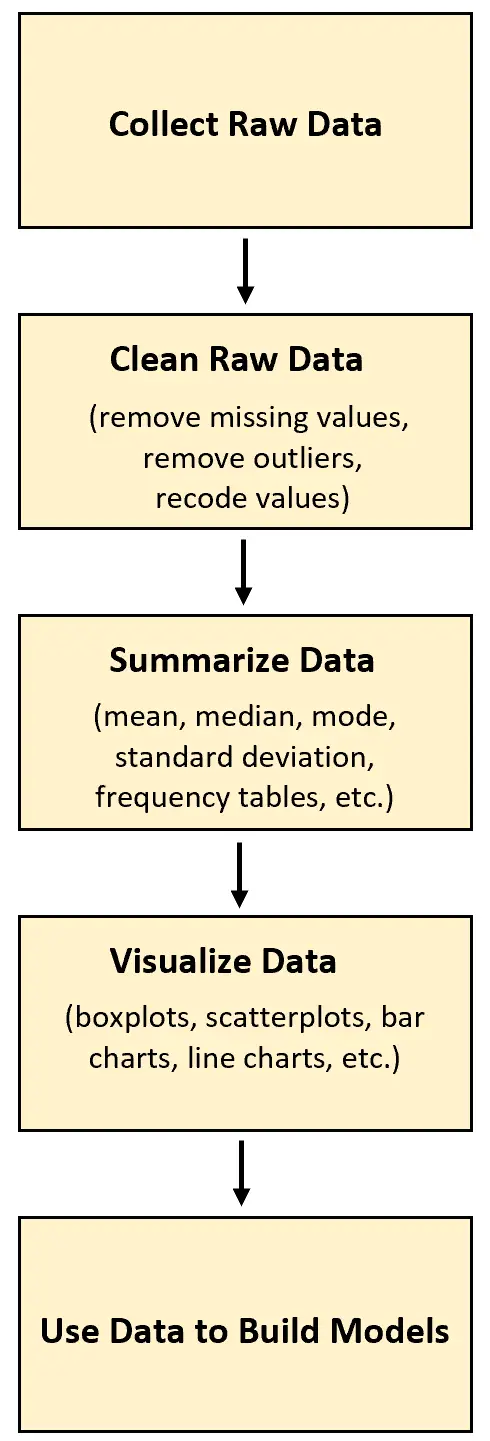
L’exemple suivant illustre comment les données brutes peuvent être collectées et utilisées dans la vie réelle.
Exemple : collecte et utilisation de données brutes
Le sport est un domaine dans lequel des données brutes sont souvent collectées. Par exemple, des données brutes peuvent être collectées pour diverses statistiques concernant les basketteurs professionnels.
Étape 1 : Collecter des données brutes
Imaginez qu’un recruteur de basket-ball collecte les données brutes suivantes pour 10 joueurs d’une équipe de basket-ball professionnelle : 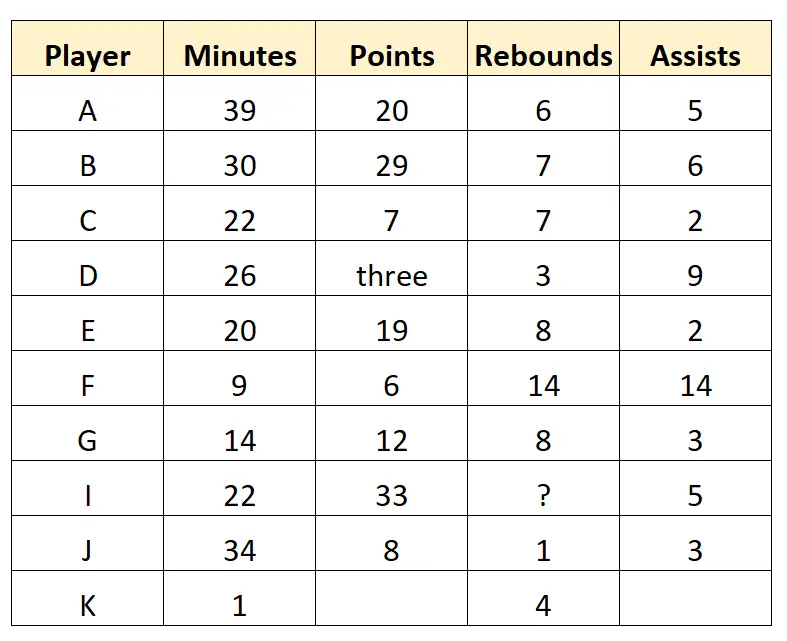
Cet ensemble de données représente les données brutes car elles sont collectées directement par le scout et n’ont été ni nettoyées ni traitées de quelque manière que ce soit.
Étape 2 : Nettoyer les données brutes
Avant d’utiliser ces données pour créer des tableaux récapitulatifs, des graphiques ou toute autre chose, l’éclaireur doit d’abord supprimer toutes les valeurs manquantes et nettoyer toutes les valeurs de données « sales ».
Par exemple, nous pouvons repérer plusieurs valeurs dans l’ensemble de données qui doivent être transformées ou supprimées :
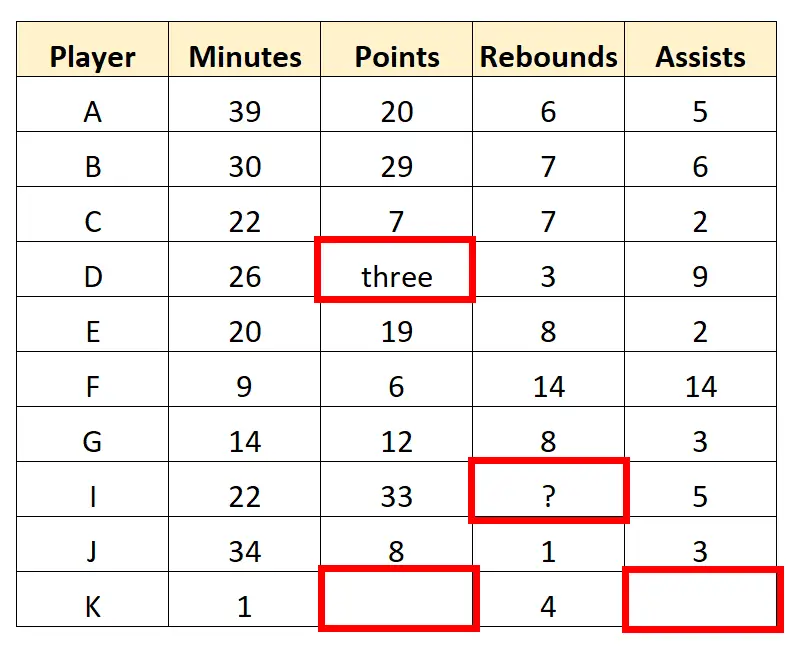
L’éclaireur peut décider de supprimer entièrement la dernière ligne car elle comporte plusieurs valeurs manquantes. Il peut ensuite nettoyer les valeurs des caractères dans l’ensemble de données pour obtenir les données « propres » suivantes :
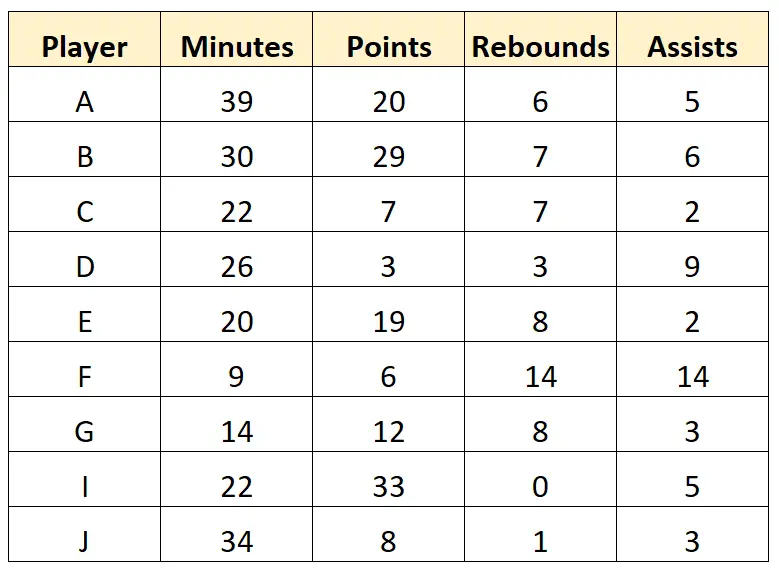
Étape 3 : Résumer les données
Une fois les données nettoyées, l’éclaireur peut alors résumer chaque variable de l’ensemble de données. Par exemple, il pourrait calculer les statistiques récapitulatives suivantes pour la variable « Minutes » :
- Moyenne : 24 minutes
- Médiane : 22 minutes
- Ecart type : 9,45 minutes
Étape 4 : Visualiser les données
Le scout peut ensuite visualiser les variables de l’ensemble de données pour mieux comprendre les valeurs des données.
Par exemple, il pourrait créer le diagramme à barres suivant pour visualiser le total des minutes jouées par chaque joueur :
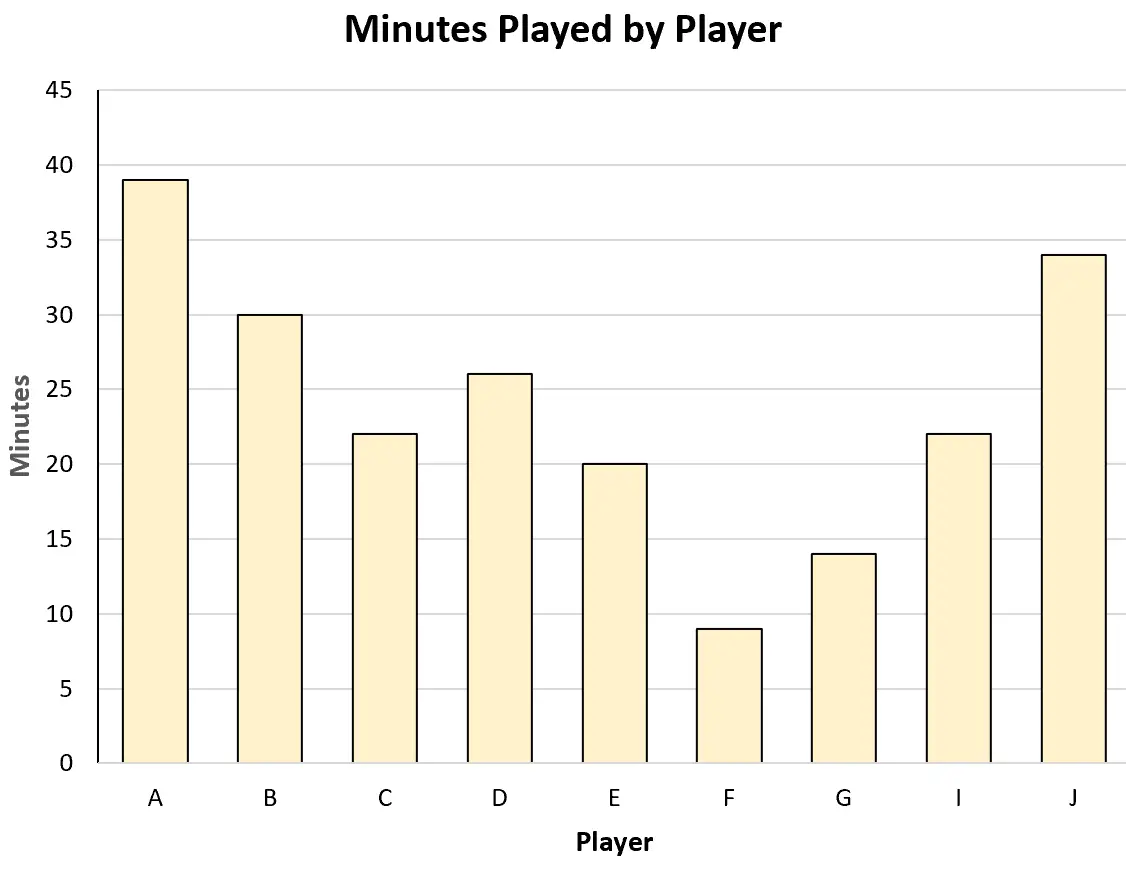
Ou il pourrait créer le nuage de points suivant pour visualiser la relation entre les minutes jouées et les points marqués :
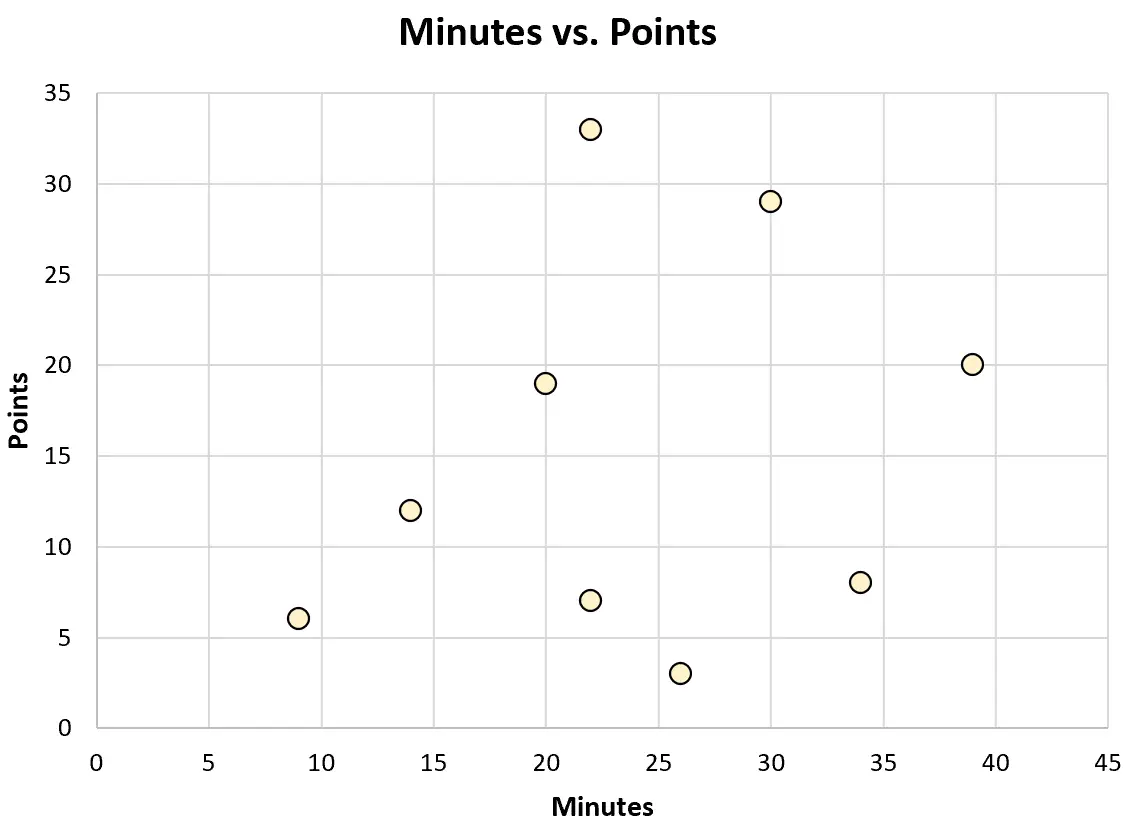
Chacun de ces types de graphiques peut l’aider à mieux comprendre les données.
Étape 5 : Utiliser les données pour créer un modèle
Enfin, une fois les données nettoyées, l’éclaireur peut décider d’adapter un certain type de modèle prédictif.
Par exemple, il peut adapter un modèle de régression linéaire simple et utiliser les minutes jouées pour prédire le total des points marqués par chaque joueur.
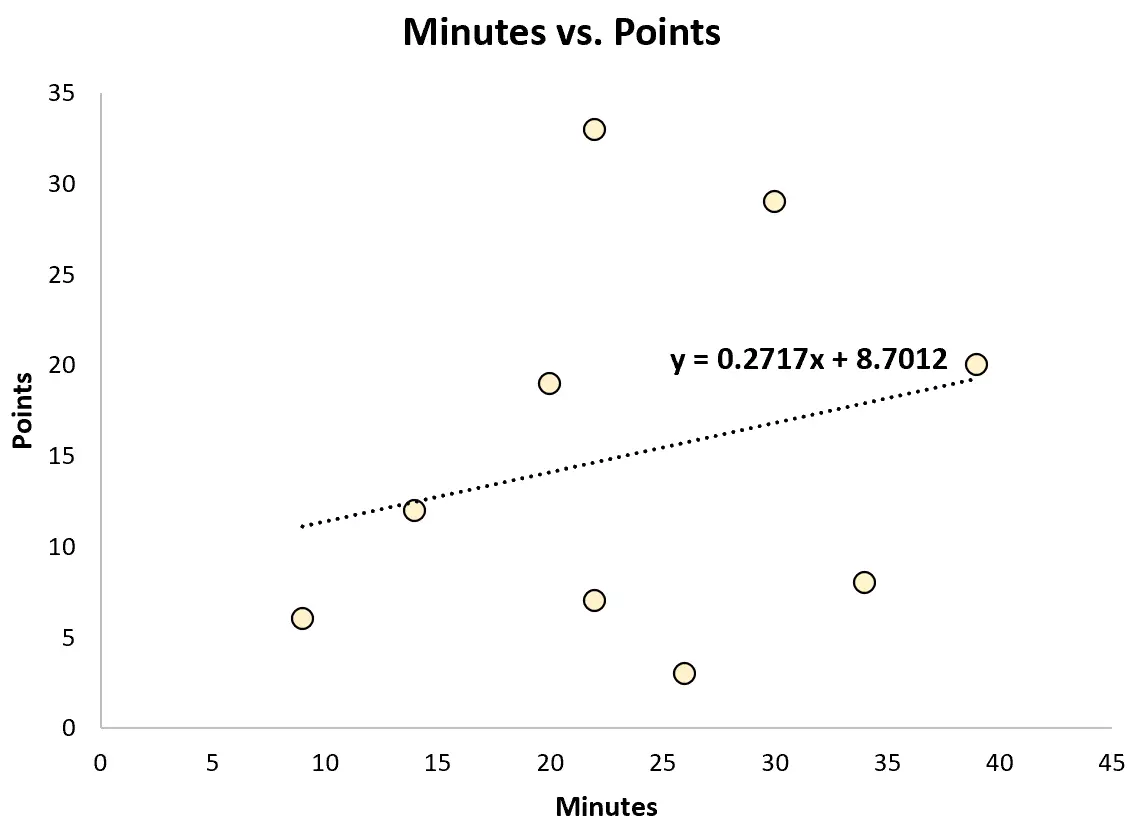
L’équation de régression ajustée est la suivante :
Points = 8,7012 + 0,2717*(minutes)
Le recruteur pourrait alors utiliser cette équation pour prédire le nombre de points qu’un joueur marquera en fonction du nombre de minutes jouées. Par exemple, un athlète qui joue 30 minutes devrait marquer 16,85 points :
Points = 8,7012 + 0,2717*(30) = 16,85
Ressources additionnelles
Pourquoi les statistiques sont-elles importantes ?
Pourquoi la taille de l’échantillon est-elle importante dans les statistiques ?
Qu’est-ce qu’une observation en statistique ?
Que sont les données tabulaires en statistiques ?
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus