
Que sont les données de grande dimension ? (Définition & Exemples)
Les données de grande dimension font référence à un ensemble de données dans lequel le nombre d’entités p est supérieur au nombre d’ observations N , souvent écrit sous la forme p >> N .
Par exemple, un ensemble de données comportant p = 6 entités et seulement N = 3 observations serait considéré comme des données de grande dimension car le nombre d’entités est supérieur au nombre d’observations.
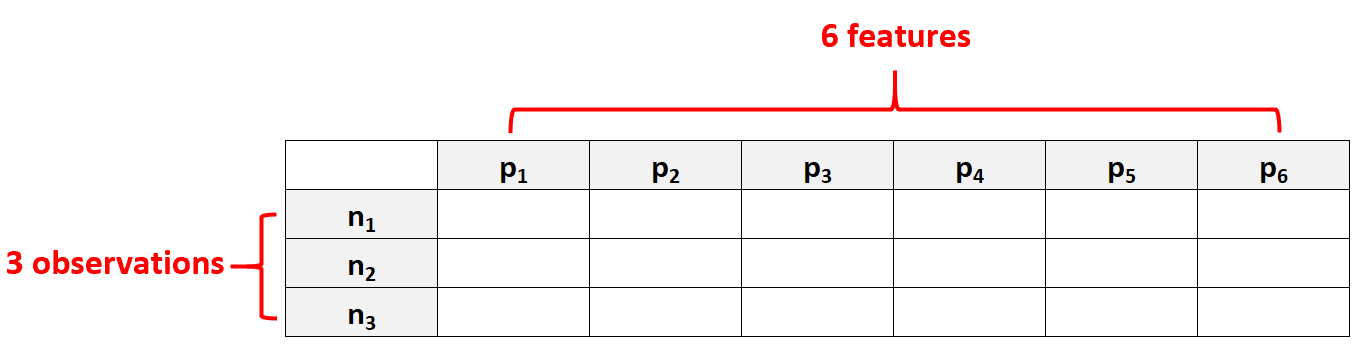
Une erreur courante que font les gens est de supposer que les « données de grande dimension » désignent simplement un ensemble de données comportant de nombreuses fonctionnalités. Cependant, c’est incorrect. Un ensemble de données peut contenir 10 000 entités, mais s’il contient 100 000 observations, il n’est pas de grande dimension.
Remarque : reportez-vous au chapitre 18 des éléments de l’apprentissage statistique pour une analyse approfondie des mathématiques sous-jacentes aux données de grande dimension.
Pourquoi les données de grande dimension constituent-elles un problème ?
Lorsque le nombre d’entités dans un ensemble de données dépasse le nombre d’observations, nous n’aurons jamais de réponse déterministe.
En d’autres termes, il devient impossible de trouver un modèle capable de décrire la relation entre les variables prédictives et la variable de réponse , car nous ne disposons pas de suffisamment d’observations sur lesquelles entraîner le modèle.
Exemples de données de grande dimension
Les exemples suivants illustrent des ensembles de données de grande dimension dans différents domaines.
Exemple 1 : Données de santé
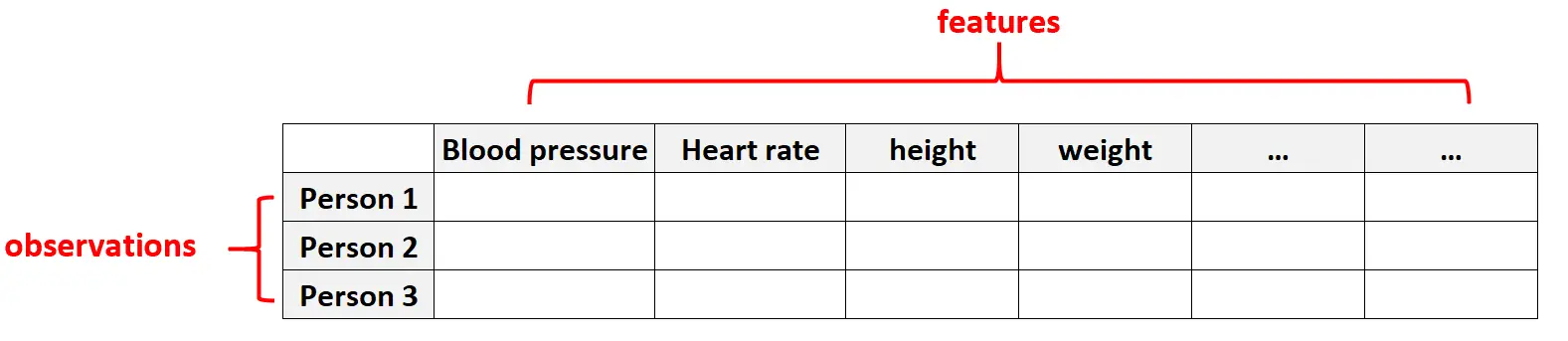
Les données de grande dimension sont courantes dans les ensembles de données de santé où le nombre de caractéristiques pour un individu donné peut être énorme (c’est-à-dire la tension artérielle, la fréquence cardiaque au repos, l’état du système immunitaire, les antécédents chirurgicaux, la taille, le poids, les conditions existantes, etc.).
Dans ces ensembles de données, il est courant que le nombre d’entités soit supérieur au nombre d’observations.
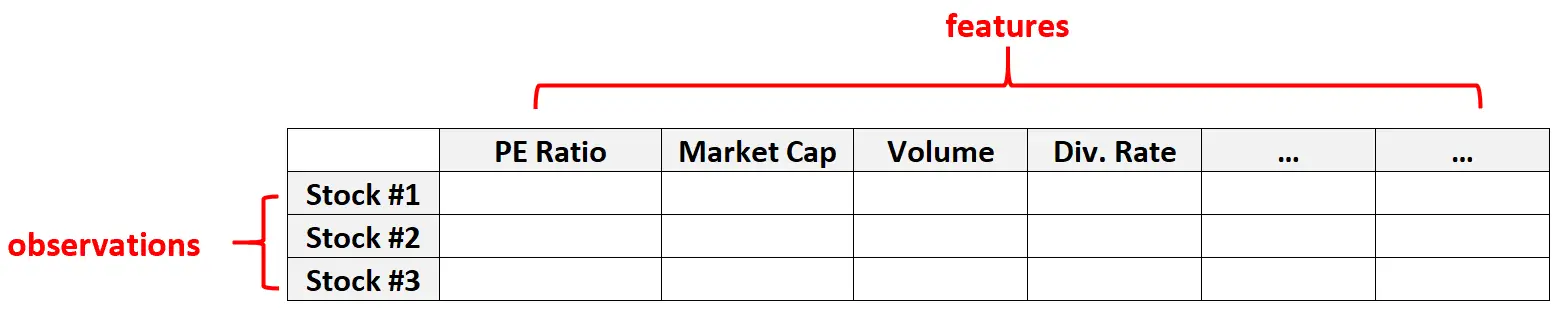
Exemple 2 : données financières
Les données de grande dimension sont également courantes dans les ensembles de données financières où le nombre de caractéristiques pour une action donnée peut être assez important (c’est-à-dire ratio PE, capitalisation boursière, volume des transactions, taux de dividende, etc.)
Dans ces types d’ensembles de données, il est courant que le nombre d’entités soit bien supérieur au nombre d’actions individuelles.
Exemple 3 : Génomique
Les données de grande dimension sont également fréquentes dans le domaine de la génomique, où le nombre de caractéristiques génétiques d’un individu donné peut être énorme.

Comment gérer les données de grande dimension
Il existe deux manières courantes de traiter des données de grande dimension :
1. Choisissez d’inclure moins de fonctionnalités.
Le moyen le plus évident d’éviter de traiter des données de grande dimension est simplement d’inclure moins d’entités dans l’ensemble de données.
Il existe plusieurs façons de décider quelles entités supprimer d’un ensemble de données, notamment :
- Supprimer les fonctionnalités avec de nombreuses valeurs manquantes : si une colonne donnée dans un ensemble de données comporte de nombreuses valeurs manquantes, vous pourrez peut-être la supprimer complètement sans perdre beaucoup d’informations.
- Supprimer les fonctionnalités à faible variance : si une colonne donnée dans un ensemble de données a des valeurs qui changent très peu, vous pourrez peut-être la supprimer car il est peu probable qu’elle offre autant d’informations utiles sur une variable de réponse que d’autres fonctionnalités.
- Supprimer les fonctionnalités ayant une faible corrélation avec la variable de réponse : si une certaine fonctionnalité n’est pas fortement corrélée avec la variable de réponse qui vous intéresse, vous pouvez probablement la supprimer de l’ensemble de données, car il est peu probable qu’elle soit une fonctionnalité utile dans un modèle.
2. Utilisez une méthode de régularisation.
Une autre façon de gérer des données de grande dimension sans supprimer des fonctionnalités de l’ensemble de données consiste à utiliser une technique de régularisation telle que :
- Analyse des composantes principales
- Régression des composantes principales
- Régression de crête
- Régression au lasso
Chacune de ces techniques peut être utilisée pour traiter efficacement des données de grande dimension.
Vous pouvez trouver une liste complète de tous les didacticiels d’apprentissage automatique sur la statologie sur cette page .
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus