
Comment calculer les statistiques de levier dans R
En statistiques, une observation est considérée comme une valeur aberrante si sa valeur pour la variable de réponse est beaucoup plus grande que le reste des observations de l’ensemble de données.
De même, une observation est considérée comme ayant un effet de levier élevé si elle a une ou plusieurs valeurs pour les variables prédictives qui sont beaucoup plus extrêmes par rapport au reste des observations de l’ensemble de données.
L’une des premières étapes de tout type d’analyse consiste à examiner de plus près les observations qui ont un effet de levier élevé, car elles pourraient avoir un impact important sur les résultats d’un modèle donné.
Ce didacticiel montre un exemple étape par étape de la façon de calculer et de visualiser l’effet de levier pour chaque observation dans un modèle dans R.
Étape 1 : Créer un modèle de régression
Tout d’abord, nous allons créer un modèle de régression linéaire multiple à l’aide de l’ensemble de données mtcars intégré dans R :
#load the dataset data(mtcars) #fit a regression model model <- lm(mpg~disp+hp, data=mtcars) #view model summary summary(model) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 30.735904 1.331566 23.083 < 2e-16 *** disp -0.030346 0.007405 -4.098 0.000306 *** hp -0.024840 0.013385 -1.856 0.073679 . --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.127 on 29 degrees of freedom Multiple R-squared: 0.7482, Adjusted R-squared: 0.7309 F-statistic: 43.09 on 2 and 29 DF, p-value: 2.062e-09
Étape 2 : Calculez l’effet de levier pour chaque observation
Ensuite, nous utiliserons la fonction hatvalues() pour calculer l’effet de levier pour chaque observation du modèle :
#calculate leverage for each observation in the model hats <- as.data.frame(hatvalues(model)) #display leverage stats for each observation hats hatvalues(model) Mazda RX4 0.04235795 Mazda RX4 Wag 0.04235795 Datsun 710 0.06287776 Hornet 4 Drive 0.07614472 Hornet Sportabout 0.08097817 Valiant 0.05945972 Duster 360 0.09828955 Merc 240D 0.08816960 Merc 230 0.05102253 Merc 280 0.03990060 Merc 280C 0.03990060 Merc 450SE 0.03890159 Merc 450SL 0.03890159 Merc 450SLC 0.03890159 Cadillac Fleetwood 0.19443875 Lincoln Continental 0.16042361 Chrysler Imperial 0.12447530 Fiat 128 0.08346304 Honda Civic 0.09493784 Toyota Corolla 0.08732818 Toyota Corona 0.05697867 Dodge Challenger 0.06954069 AMC Javelin 0.05767659 Camaro Z28 0.10011654 Pontiac Firebird 0.12979822 Fiat X1-9 0.08334018 Porsche 914-2 0.05785170 Lotus Europa 0.08193899 Ford Pantera L 0.13831817 Ferrari Dino 0.12608583 Maserati Bora 0.49663919 Volvo 142E 0.05848459
En règle générale, nous examinons de plus près les observations dont la valeur de levier est supérieure à 2.
Un moyen simple de procéder consiste à trier les observations en fonction de leur valeur de levier, par ordre décroissant :
#sort observations by leverage, descending hats[order(-hats['hatvalues(model)']), ] [1] 0.49663919 0.19443875 0.16042361 0.13831817 0.12979822 0.12608583 [7] 0.12447530 0.10011654 0.09828955 0.09493784 0.08816960 0.08732818 [13] 0.08346304 0.08334018 0.08193899 0.08097817 0.07614472 0.06954069 [19] 0.06287776 0.05945972 0.05848459 0.05785170 0.05767659 0.05697867 [25] 0.05102253 0.04235795 0.04235795 0.03990060 0.03990060 0.03890159 [31] 0.03890159 0.03890159
Nous pouvons voir que la valeur de levier la plus élevée est de 0,4966 . Comme ce chiffre n’est pas supérieur à 2, nous savons qu’aucune des observations de notre ensemble de données n’a un effet de levier élevé.
Étape 3 : Visualisez l’effet de levier pour chaque observation
Enfin, nous pouvons créer un graphique rapide pour visualiser l’effet de levier pour chaque observation :
#plot leverage values for each observation plot(hatvalues(model), type = 'h')
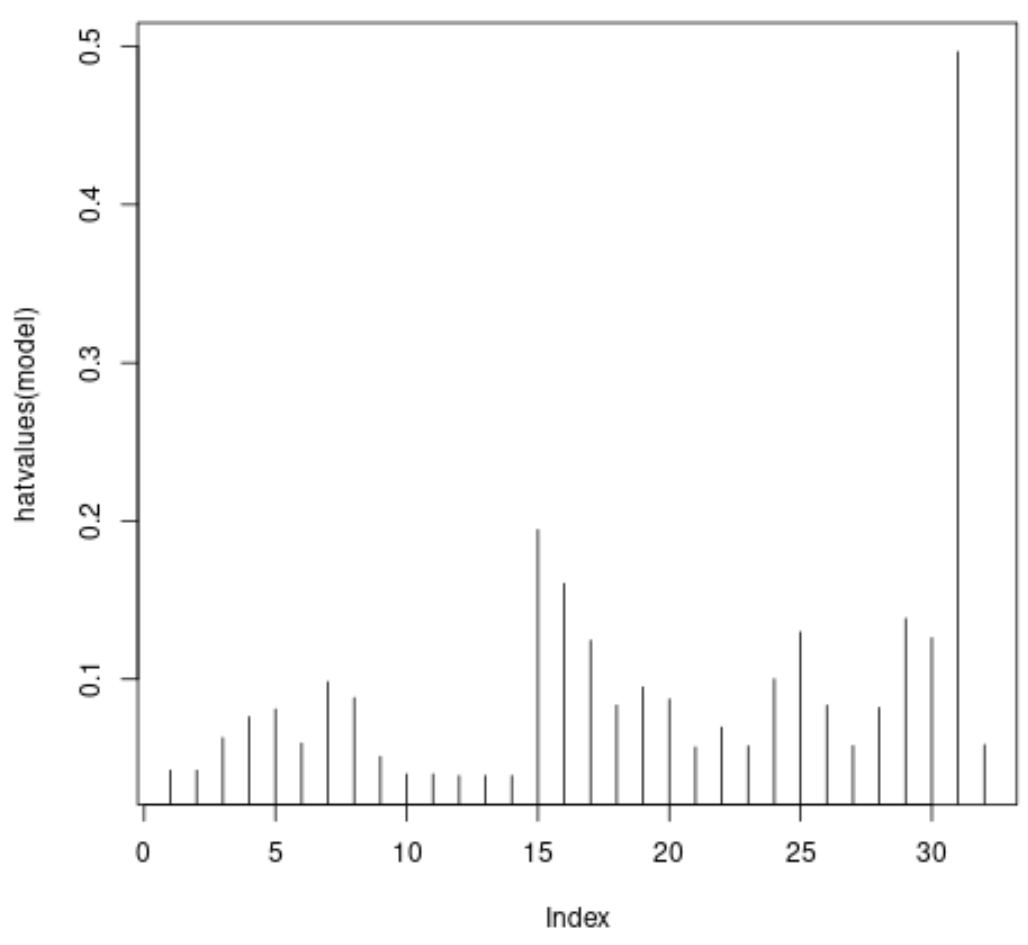
L’axe des x affiche l’indice de chaque observation dans l’ensemble de données et la valeur y affiche la statistique de levier correspondante pour chaque observation.
Ressources additionnelles
Comment effectuer une régression linéaire simple dans R
Comment effectuer une régression linéaire multiple dans R
Comment créer un tracé résiduel dans R
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus