
Un guide complet de l’ensemble de données sur les diamants dans R
L’ensemble de données sur les diamants est un ensemble de données intégré au package ggplot2 dans R.
Il contient des mesures sur 10 variables différentes (comme le prix, la couleur, la clarté, etc.) pour 53 940 diamants différents.
Ce didacticiel explique comment explorer, résumer et visualiser l’ensemble de données sur les diamants dans R.
Charger l’ensemble de données sur les diamants
Puisque l’ensemble de données sur les diamants est un ensemble de données intégré dans ggplot2, nous devons d’abord installer (si ce n’est pas déjà fait) et charger le package ggplot2 :
#install ggplot2 if not already installed
install.packages('ggplot2')
#load ggplot2
library(ggplot2)
Une fois que nous avons chargé ggplot2, nous pouvons utiliser la fonction data() pour charger l’ensemble de données sur les diamants :
data(diamonds)
Nous pouvons jeter un œil aux six premières lignes de l’ensemble de données en utilisant la fonction head() :
#view first six rows of diamonds dataset
head(diamonds)
carat cut color clarity depth table price x y z
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
Résumer l’ensemble de données sur les diamants
Nous pouvons utiliser la fonction summary() pour résumer rapidement chaque variable de l’ensemble de données :
#summarize diamonds dataset
summary(diamonds)
carat cut color clarity depth
Min. :0.2000 Fair : 1610 D: 6775 SI1 :13065 Min. :43.00
1st Qu.:0.4000 Good : 4906 E: 9797 VS2 :12258 1st Qu.:61.00
Median :0.7000 Very Good:12082 F: 9542 SI2 : 9194 Median :61.80
Mean :0.7979 Premium :13791 G:11292 VS1 : 8171 Mean :61.75
3rd Qu.:1.0400 Ideal :21551 H: 8304 VVS2 : 5066 3rd Qu.:62.50
Max. :5.0100 I: 5422 VVS1 : 3655 Max. :79.00
J: 2808 (Other): 2531
table price x y z
Min. :43.00 Min. : 326 Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.:56.00 1st Qu.: 950 1st Qu.: 4.710 1st Qu.: 4.720 1st Qu.: 2.910
Median :57.00 Median : 2401 Median : 5.700 Median : 5.710 Median : 3.530
Mean :57.46 Mean : 3933 Mean : 5.731 Mean : 5.735 Mean : 3.539
3rd Qu.:59.00 3rd Qu.: 5324 3rd Qu.: 6.540 3rd Qu.: 6.540 3rd Qu.: 4.040
Max. :95.00 Max. :18823 Max. :10.740 Max. :58.900 Max. :31.800
Pour chacune des variables numériques, nous pouvons voir les informations suivantes :
- Min : La valeur minimale.
- 1er Qu : La valeur du premier quartile (25ème centile).
- Médiane : La valeur médiane.
- Moyenne : La valeur moyenne.
- 3ème Qu : La valeur du troisième quartile (75ème centile).
- Max : La valeur maximale.
Pour les variables catégorielles de l’ensemble de données (coupe, couleur et clarté), nous voyons un décompte de fréquence de chaque valeur.
Par exemple, pour la variable cut :
- Fair : Cette valeur apparaît 1 610 fois.
- Bon : Cette valeur apparaît 4 906 fois.
- Très bon : cette valeur apparaît 12 082 fois.
- Premium : Cette valeur apparaît 13 791 fois.
- Idéal : Cette valeur apparaît 21 551 fois.
Nous pouvons utiliser la fonction dim() pour obtenir les dimensions de l’ensemble de données en termes de nombre de lignes et de colonnes :
#display rows and columns
dim(diamonds)
[1] 53940 10
Nous pouvons voir que l’ensemble de données comporte 53 940 lignes et 10 colonnes.
Nous pouvons également utiliser la fonction names() pour afficher les noms de colonnes du bloc de données :
#display column names
names(diamonds)
[1] "carat" "cut" "color" "clarity" "depth" "table" "price" "x"
[9] "y" "z"
Visualisez l’ensemble de données des diamants
Nous pouvons également créer des tracés pour visualiser les valeurs de l’ensemble de données.
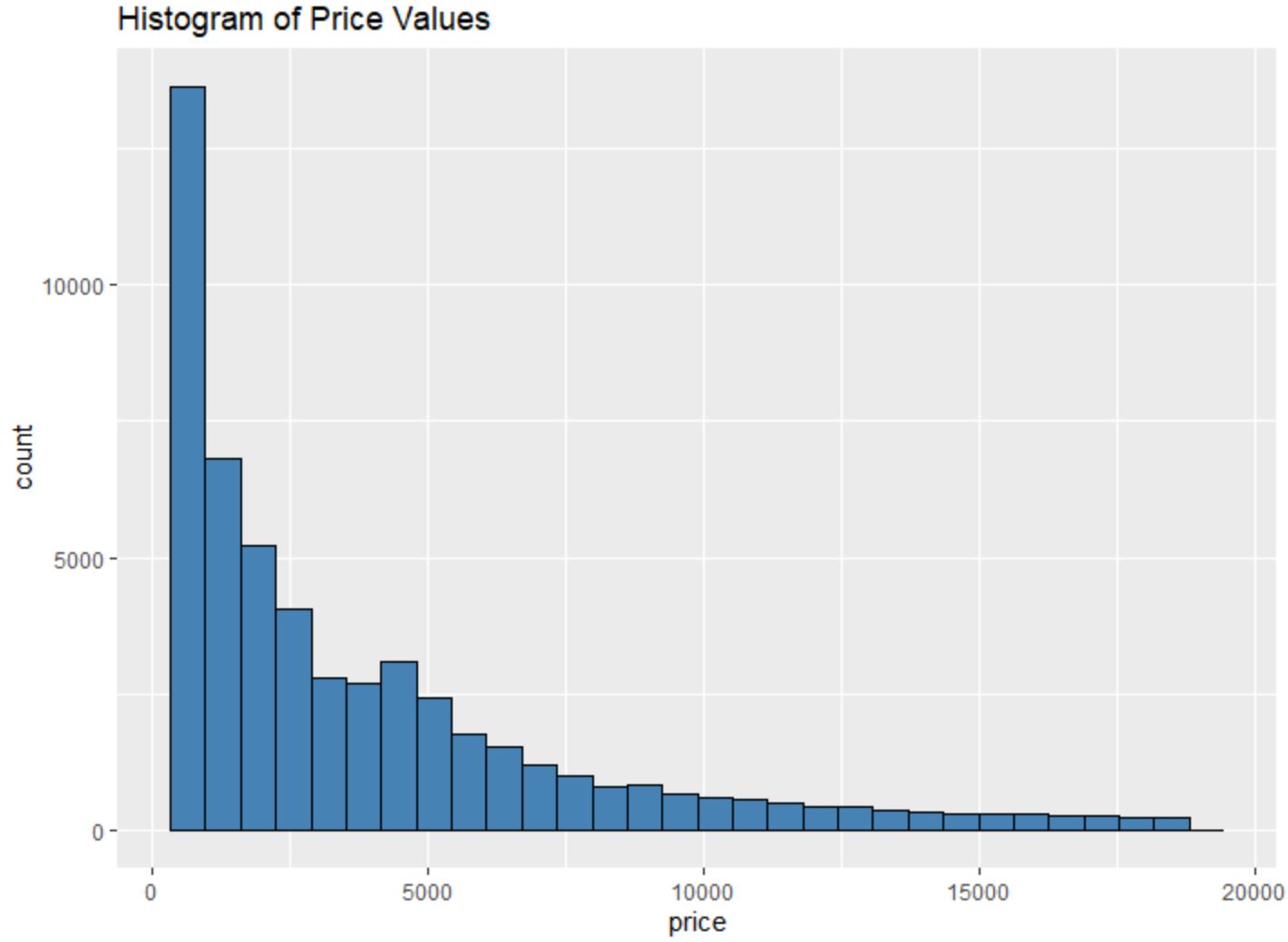
Par exemple, nous pouvons utiliser la fonction geom_histogram() pour créer un histogramme des valeurs d’une certaine variable :
#create histogram of values for price
ggplot(data=diamonds, aes(x=price)) +
geom_histogram(fill="steelblue", color="black") +
ggtitle("Histogram of Price Values")
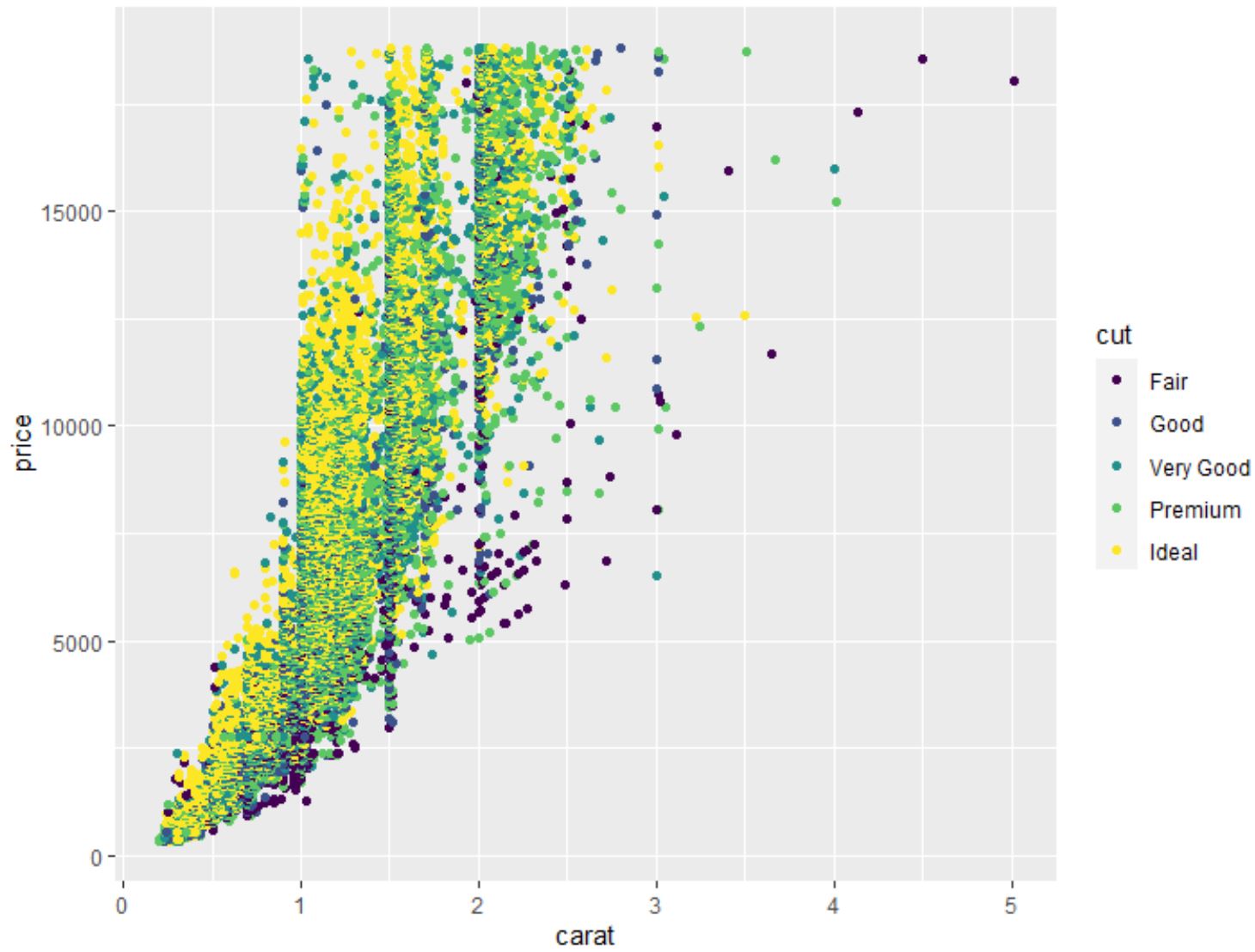
Nous pouvons également utiliser la fonction geom_point() pour créer un nuage de points de toute combinaison de variables par paires :
#create scatterplot of carat vs. price, using cut as color variable
ggplot(data=diamonds, aes(x=carat, y=price, color=cut)) +
geom_point()
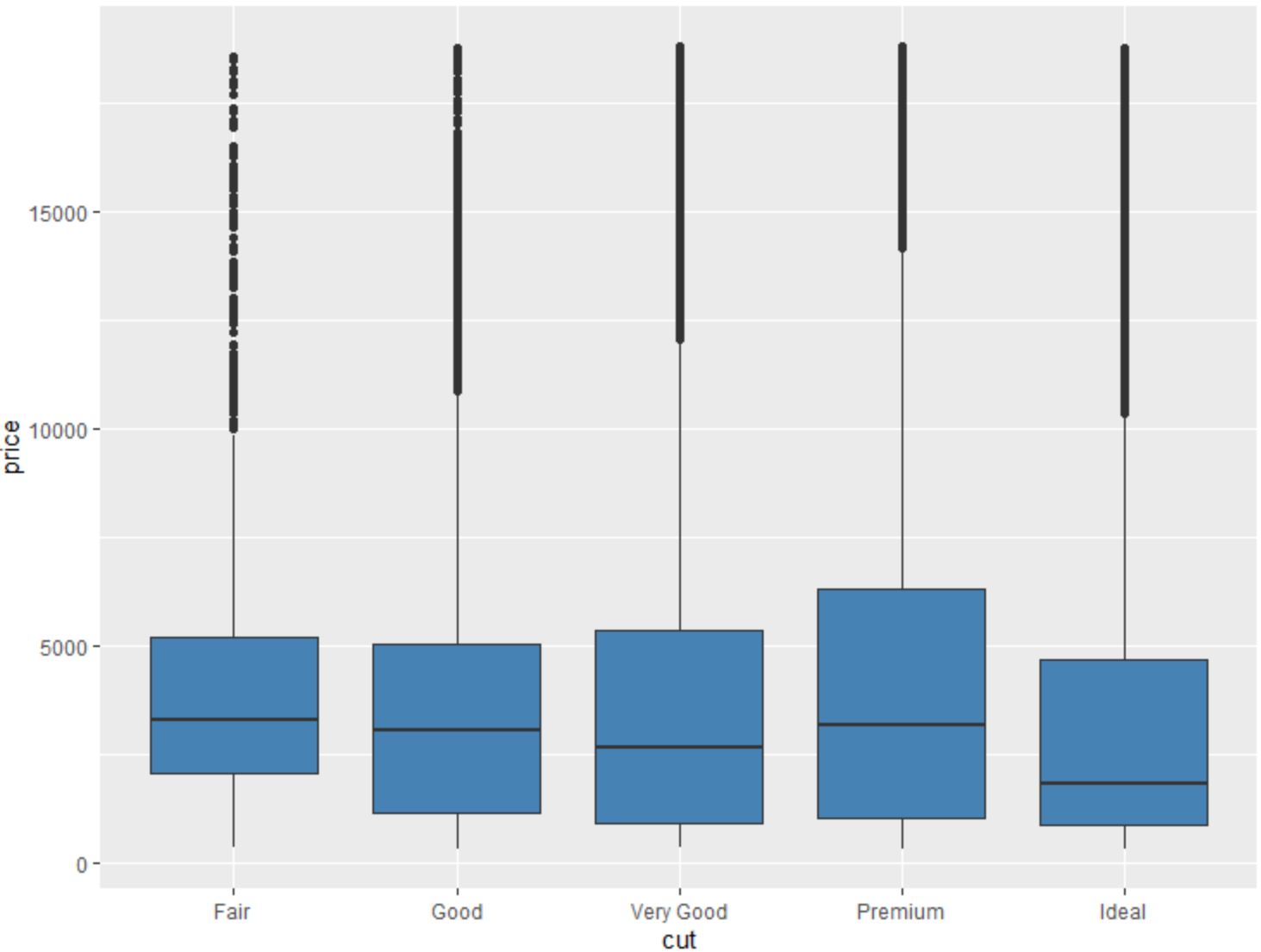
Nous pouvons également utiliser la fonction geom_boxplot() pour créer un boxplot d’une variable regroupée par une autre variable :
#create scatterplot of price, grouped by cut
ggplot(data=diamonds, aes(x=cut, y=price)) +
geom_boxplot(fill="steelblue")
En utilisant ces fonctions de ggplot2, nous pouvons en apprendre beaucoup sur les variables de l’ensemble de données sur les diamants .
Ressources additionnelles
Les didacticiels suivants expliquent comment explorer d’autres ensembles de données dans R :
Un guide complet de l’ensemble de données Iris dans R
Un guide complet de l’ensemble de données mtcars dans R
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus