
Comment extraire les résidus de la fonction lm() dans R
Vous pouvez utiliser la syntaxe suivante pour extraire les résidus de la fonction lm() dans R :
fit$residuals
Cet exemple suppose que nous avons utilisé la fonction lm() pour ajuster un modèle de régression linéaire et que nous avons nommé les résultats fit .
L’exemple suivant montre comment utiliser cette syntaxe dans la pratique.
Connexe : Comment extraire le R-Squared de la fonction lm() dans R
Exemple : Comment extraire les résidus de lm() dans R
Supposons que nous ayons le bloc de données suivant dans R qui contient des informations sur les minutes jouées, le nombre total de fautes et le total de points marqués par 10 joueurs de basket-ball :
#create data frame df <- data.frame(minutes=c(5, 10, 13, 14, 20, 22, 26, 34, 38, 40), fouls=c(5, 5, 3, 4, 2, 1, 3, 2, 1, 1), points=c(6, 8, 8, 7, 14, 10, 22, 24, 28, 30)) #view data frame df minutes fouls points 1 5 5 6 2 10 5 8 3 13 3 8 4 14 4 7 5 20 2 14 6 22 1 10 7 26 3 22 8 34 2 24 9 38 1 28 10 40 1 30
Supposons que nous souhaitions adapter le modèle de régression linéaire multiple suivant :
points = β 0 + β 1 (minutes) + β 2 (fautes)
Nous pouvons utiliser la fonction lm() pour ajuster ce modèle de régression :
#fit multiple linear regression model
fit <- lm(points ~ minutes + fouls, data=df)
On peut alors taper fit$residuals pour extraire les résidus du modèle :
#extract residuals from model
fit$residuals
1 2 3 4 5 6 7
2.0888729 -0.7982137 0.6371041 -3.5240982 1.9789676 -1.7920822 1.9306786
8 9 10
-1.7048752 0.5692404 0.6144057
Puisqu’il y avait 10 observations au total dans notre base de données, il y a 10 résidus – un pour chaque observation.
Par exemple:
- La première observation a une valeur résiduelle de 2,089 .
- La deuxième observation a une valeur résiduelle de -0,798 .
- La troisième observation a une valeur résiduelle de 0,637 .
Et ainsi de suite.
Nous pouvons ensuite créer un tracé des valeurs résiduelles par rapport aux valeurs ajustées si nous le souhaitons :
#store residuals in variable
res <- fit$residuals
#produce residual vs. fitted plot
plot(fitted(fit), res)
#add a horizontal line at 0
abline(0,0)
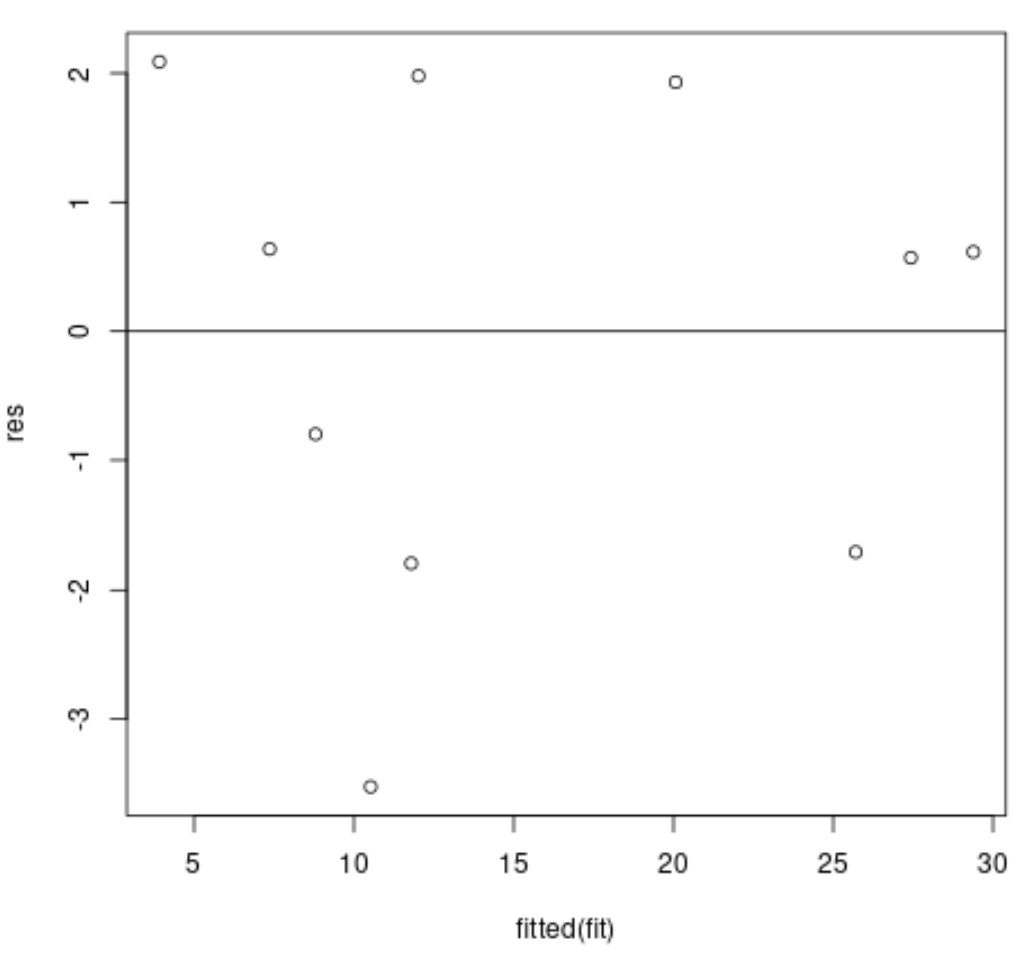
L’axe des x affiche les valeurs ajustées et l’axe des y affiche les résidus.
Idéalement, les résidus devraient être dispersés de manière aléatoire autour de zéro, sans motif clair, pour garantir que l’ hypothèse d’homoscédasticité soit respectée.
Dans le graphique des résidus ci-dessus, nous pouvons voir que les résidus semblent être dispersés de manière aléatoire autour de zéro sans motif clair, ce qui signifie que l’hypothèse d’homoscédasticité est probablement remplie.
Ressources additionnelles
Les didacticiels suivants expliquent comment effectuer d’autres tâches courantes dans R :
Comment effectuer une régression linéaire simple dans R
Comment effectuer une régression linéaire multiple dans R
Comment créer un tracé résiduel dans R
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus