
Qu’est-ce que la fiabilité inter-évaluateurs ? (Définition & #038; Exemple)
En statistiques, la fiabilité inter-évaluateurs est un moyen de mesurer le niveau d’accord entre plusieurs évaluateurs ou juges.
Il est utilisé pour évaluer la fiabilité des réponses produites par différents éléments d’un test. Si un test a une fiabilité inter-évaluateurs plus faible, cela pourrait indiquer que les éléments du test sont confus, peu clairs ou même inutiles.
Il existe deux manières courantes de mesurer la fiabilité inter-évaluateurs :
1. Pourcentage d’accord
Le moyen simple de mesurer la fiabilité inter-évaluateurs consiste à calculer le pourcentage d’éléments sur lesquels les juges sont d’accord.
C’est ce qu’on appelle le pourcentage d’accord , qui se situe toujours entre 0 et 1, 0 indiquant l’absence d’accord entre les évaluateurs et 1 indiquant un accord parfait entre les évaluateurs.
Par exemple, supposons que deux juges soient invités à évaluer la difficulté de 10 éléments d’un test sur une échelle de 1 à 3. Les résultats sont présentés ci-dessous :
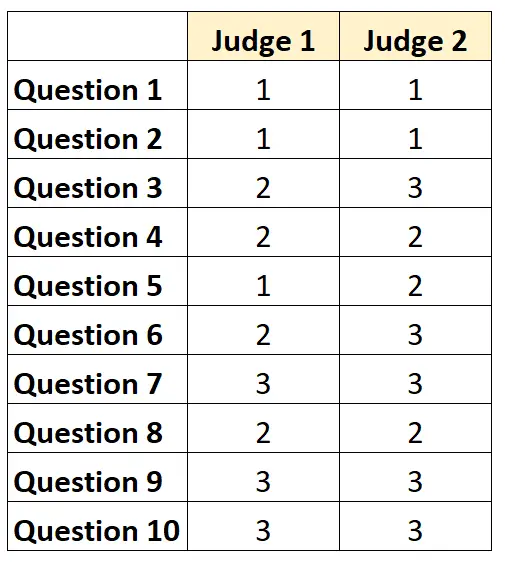
Pour chaque question, on peut écrire « 1 » si les deux juges sont d’accord et « 0 » s’ils ne sont pas d’accord.
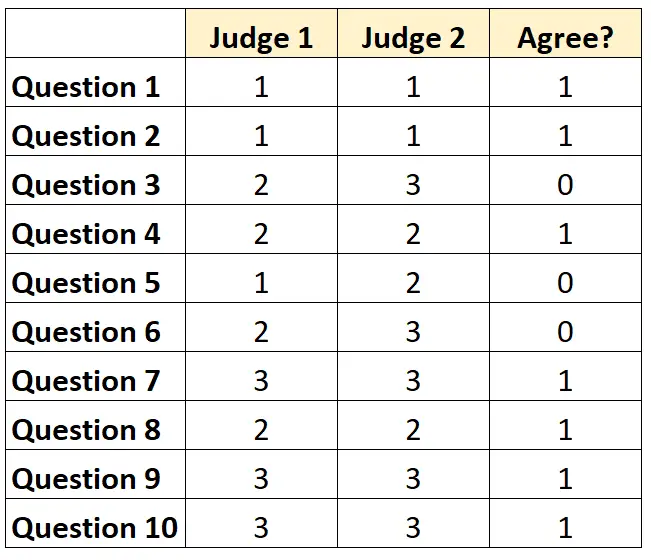
Le pourcentage de questions sur lesquelles les juges se sont mis d’accord était de 7/10 = 70 % .
2. Le Kappa de Cohen
La manière la plus difficile (et la plus rigoureuse) de mesurer la fiabilité inter-évaluateurs consiste à utiliser le Kappa de Cohen , qui calcule le pourcentage d’éléments sur lesquels les évaluateurs sont d’accord, tout en tenant compte du fait que les évaluateurs peuvent être d’accord sur certains éléments uniquement. par chance.
La formule du kappa de Cohen est calculée comme suit :
k = (p o – p e ) / (1 – p e )
où:
- p o : Accord relatif observé parmi les évaluateurs
- p e : Probabilité hypothétique d’accord fortuit
Le Kappa de Cohen se situe toujours entre 0 et 1, 0 indiquant l’absence d’accord entre les évaluateurs et 1 indiquant un accord parfait entre les évaluateurs.
Pour un exemple étape par étape de la façon de calculer le Kappa de Cohen, reportez-vous à ce didacticiel .
Comment interpréter la fiabilité inter-évaluateurs
Plus la fiabilité inter-évaluateurs est élevée, plus plusieurs juges évaluent de manière cohérente les éléments ou les questions d’un test avec des scores similaires.
En général, un accord inter-évaluateurs d’au moins 75 % est requis dans la plupart des domaines pour qu’un test soit considéré comme fiable. Toutefois, des fiabilités inter-évaluateurs plus élevées peuvent être nécessaires dans des domaines spécifiques.
Par exemple, une fiabilité inter-évaluateurs de 75 % peut être acceptable pour un test visant à déterminer dans quelle mesure une émission de télévision sera reçue.
D’un autre côté, une fiabilité inter-évaluateurs de 95 % peut être requise dans les contextes médicaux dans lesquels plusieurs médecins jugent si un certain traitement doit ou non être utilisé sur un patient donné.
Notez que dans la plupart des contextes universitaires et des domaines de recherche rigoureux, le Kappa de Cohen est utilisé pour calculer la fiabilité inter-évaluateurs.
Ressources additionnelles
Une introduction rapide à l’analyse de fiabilité
Qu’est-ce que la fiabilité divisée en deux ?
Qu’est-ce que la fiabilité test-retest ?
Qu’est-ce que la fiabilité des formulaires parallèles ?
Qu’est-ce qu’une erreur type de mesure ?
Calculateur Kappa de Cohen
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus