
Un guide complet de l’ensemble de données Iris dans R
L’ensemble de données iris est un ensemble de données intégré dans R qui contient des mesures sur 4 attributs différents (en centimètres) pour 50 fleurs de 3 espèces différentes.
Ce didacticiel explique comment explorer et résumer un ensemble de données dans R, en utilisant l’ensemble de données iris comme exemple.
Connexe : Un guide complet de l’ensemble de données mtcars dans R
Charger l’ensemble de données Iris
Puisque l’ensemble de données iris est un ensemble de données intégré dans R, nous pouvons le charger en utilisant la commande suivante :
data(iris)
Nous pouvons jeter un œil aux six premières lignes de l’ensemble de données en utilisant la fonction head() :
#view first six rows of iris dataset
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
Résumer l’ensemble de données Iris
Nous pouvons utiliser la fonction summary() pour résumer rapidement chaque variable de l’ensemble de données :
#summarize iris dataset
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median :5.800 Median :3.000 Median :4.350 Median :1.300
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Species
setosa :50
versicolor:50
virginica :50
Pour chacune des variables numériques, nous pouvons voir les informations suivantes :
- Min : La valeur minimale.
- 1er Qu : La valeur du premier quartile (25ème centile).
- Médiane : La valeur médiane.
- Moyenne : La valeur moyenne.
- 3ème Qu : La valeur du troisième quartile (75ème centile).
- Max : La valeur maximale.
Pour la seule variable catégorielle de l’ensemble de données (Espèce), nous voyons un décompte de fréquence de chaque valeur :
- setosa : Cette espèce est présente 50 fois.
- versicolor : Cette espèce est présente 50 fois.
- virginica : Cette espèce est présente 50 fois.
Nous pouvons utiliser la fonction dim() pour obtenir les dimensions de l’ensemble de données en termes de nombre de lignes et de colonnes :
#display rows and columns
dim(iris)
[1] 150 5
Nous pouvons voir que l’ensemble de données comporte 150 lignes et 5 colonnes.
Nous pouvons également utiliser la fonction names() pour afficher les noms de colonnes du bloc de données :
#display column names
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
Visualisez l’ensemble de données Iris
Nous pouvons également créer des tracés pour visualiser les valeurs de l’ensemble de données.
Par exemple, nous pouvons utiliser la fonction hist() pour créer un histogramme des valeurs d’une certaine variable :
#create histogram of values for sepal length
hist(iris$Sepal.Length,
col='steelblue',
main='Histogram',
xlab='Length',
ylab='Frequency')
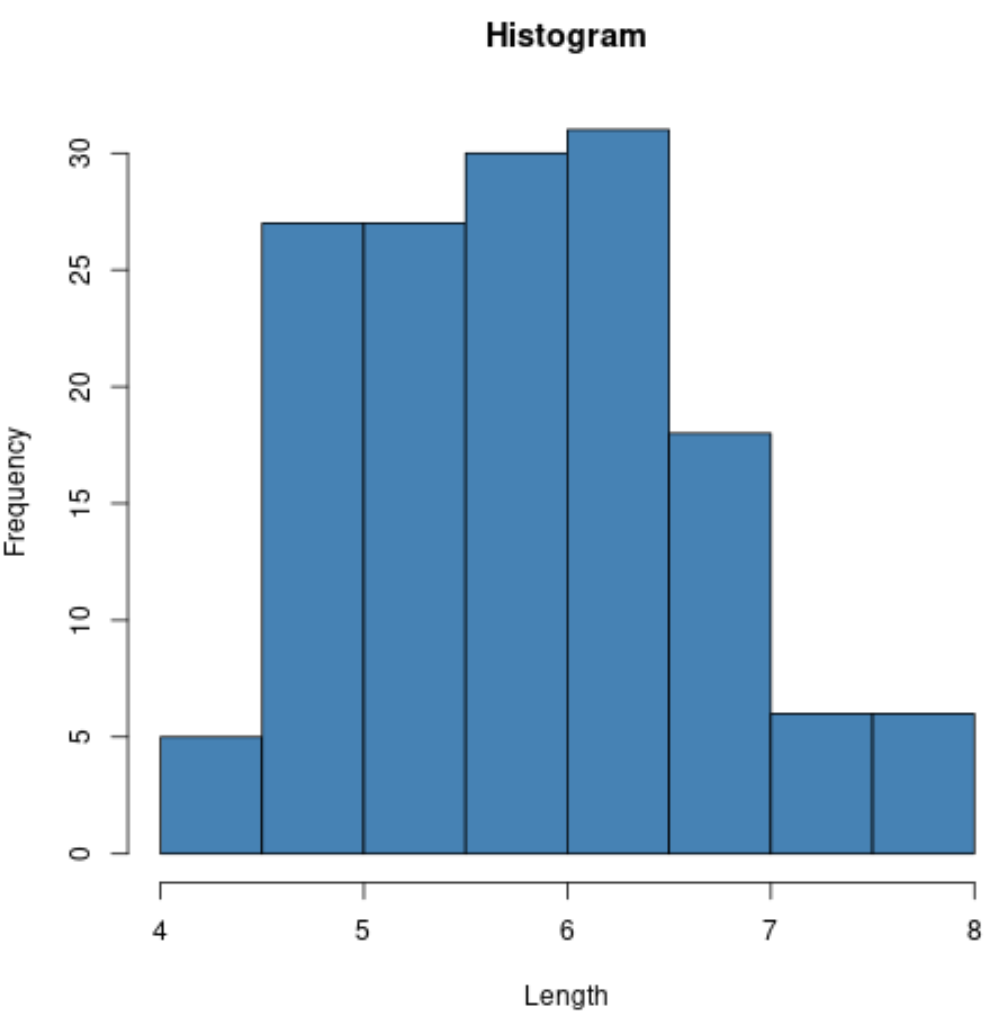
Nous pouvons également utiliser la fonction plot() pour créer un nuage de points de toute combinaison de variables par paires :
#create scatterplot of sepal width vs. sepal length
plot(iris$Sepal.Width, iris$Sepal.Length,
col='steelblue',
main='Scatterplot',
xlab='Sepal Width',
ylab='Sepal Length',
pch=19)
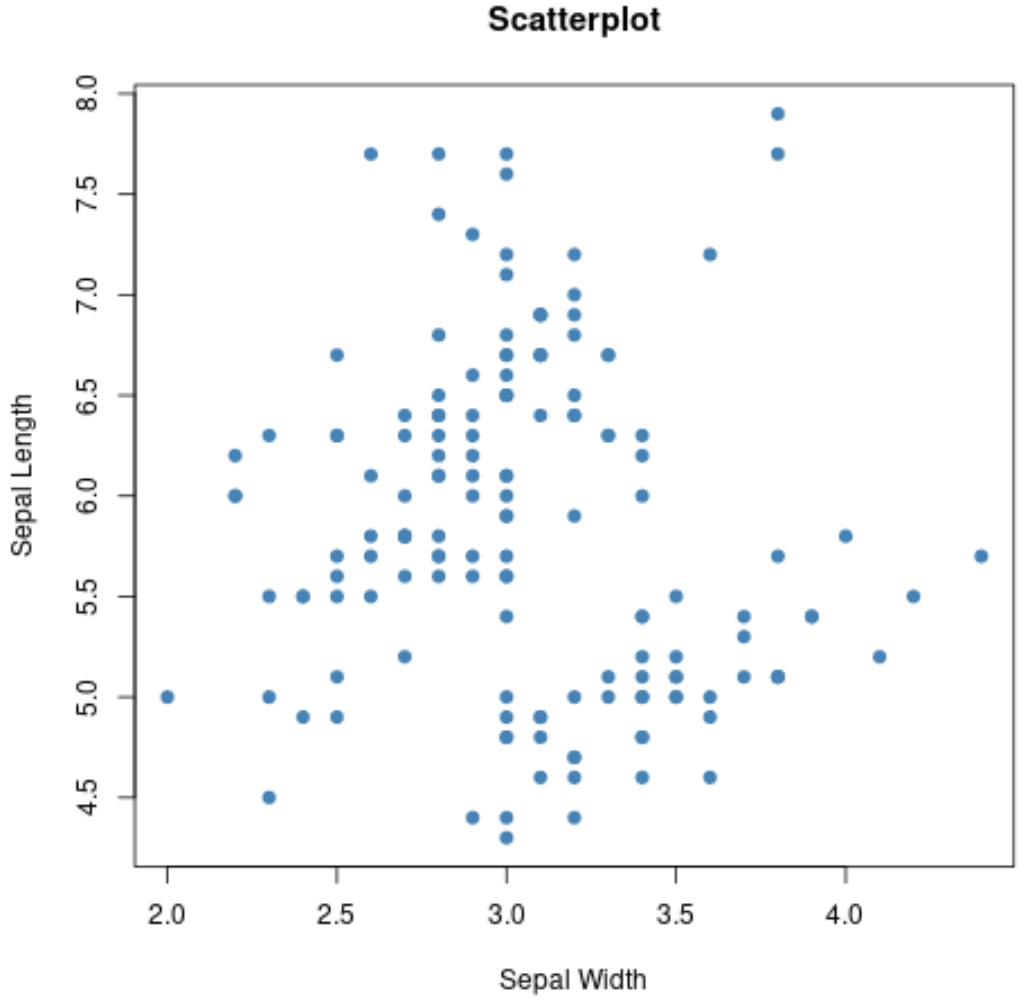
On peut également utiliser la fonction boxplot() pour créer un boxplot par groupe :
#create scatterplot of sepal width vs. sepal length
boxplot(Sepal.Length~Species,
data=iris,
main='Sepal Length by Species',
xlab='Species',
ylab='Sepal Length',
col='steelblue',
border='black')
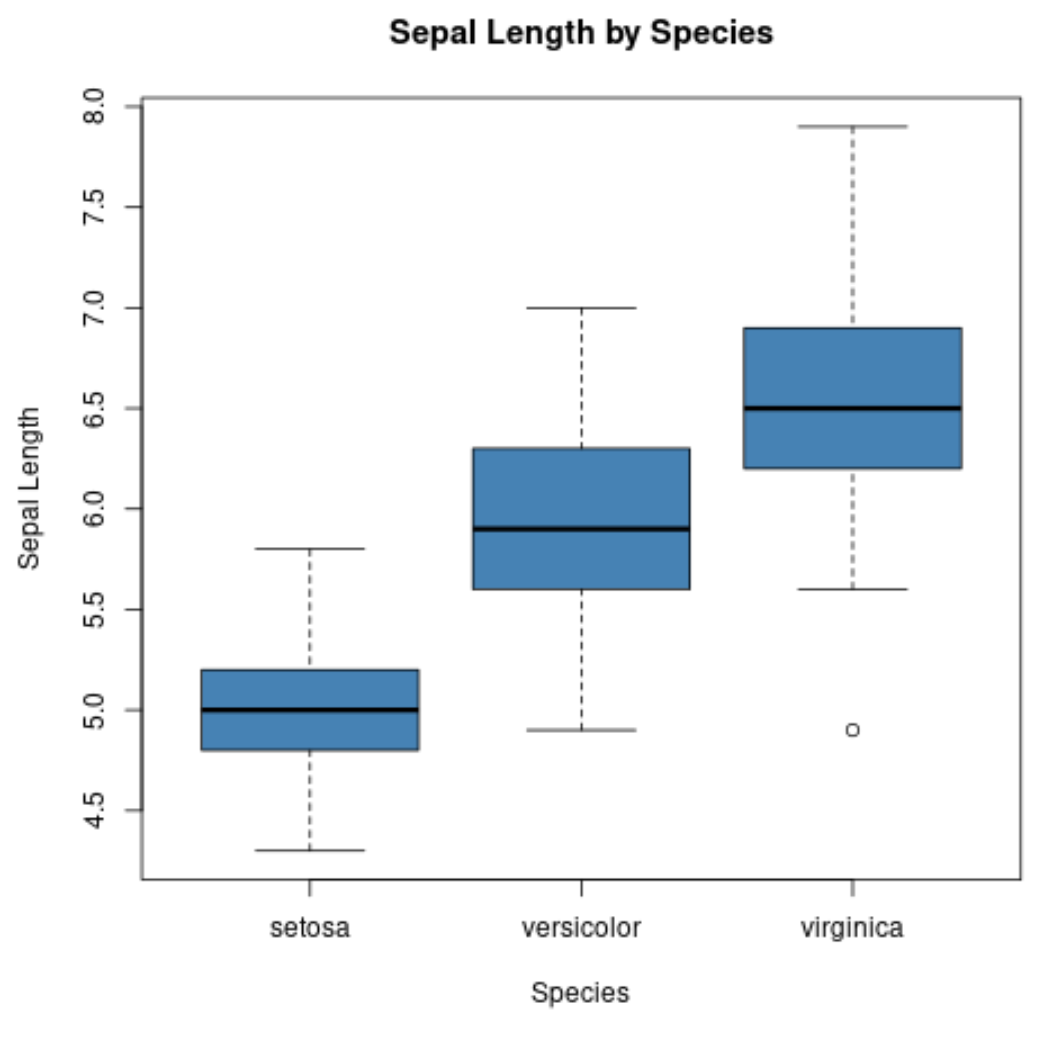
L’axe des x affiche les trois espèces et l’axe des y affiche la distribution des valeurs de longueur des sépales pour chaque espèce.
Ce type de tracé nous permet de constater rapidement que la longueur des sépales a tendance à être la plus grande pour l’espèce virginica et la plus petite pour l’espèce setosa.
Ressources additionnelles
Les didacticiels suivants expliquent plus en détail comment résumer des ensembles de données dans R :
Le moyen le plus simple de créer des tableaux récapitulatifs dans R
Comment calculer le résumé de cinq nombres dans R
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus