
Ensemble de validation et ensemble de test : quelle est la différence ?
Chaque fois que nous adaptons un algorithme d’apprentissage automatique à un ensemble de données, nous divisons généralement l’ensemble de données en trois parties :
1. Ensemble de formation : utilisé pour entraîner le modèle.
2. Ensemble de validation : utilisé pour optimiser les paramètres du modèle.
3. Ensemble de tests : utilisé pour obtenir une estimation impartiale des performances finales du modèle.
Le diagramme suivant fournit une explication visuelle de ces trois différents types d’ensembles de données :
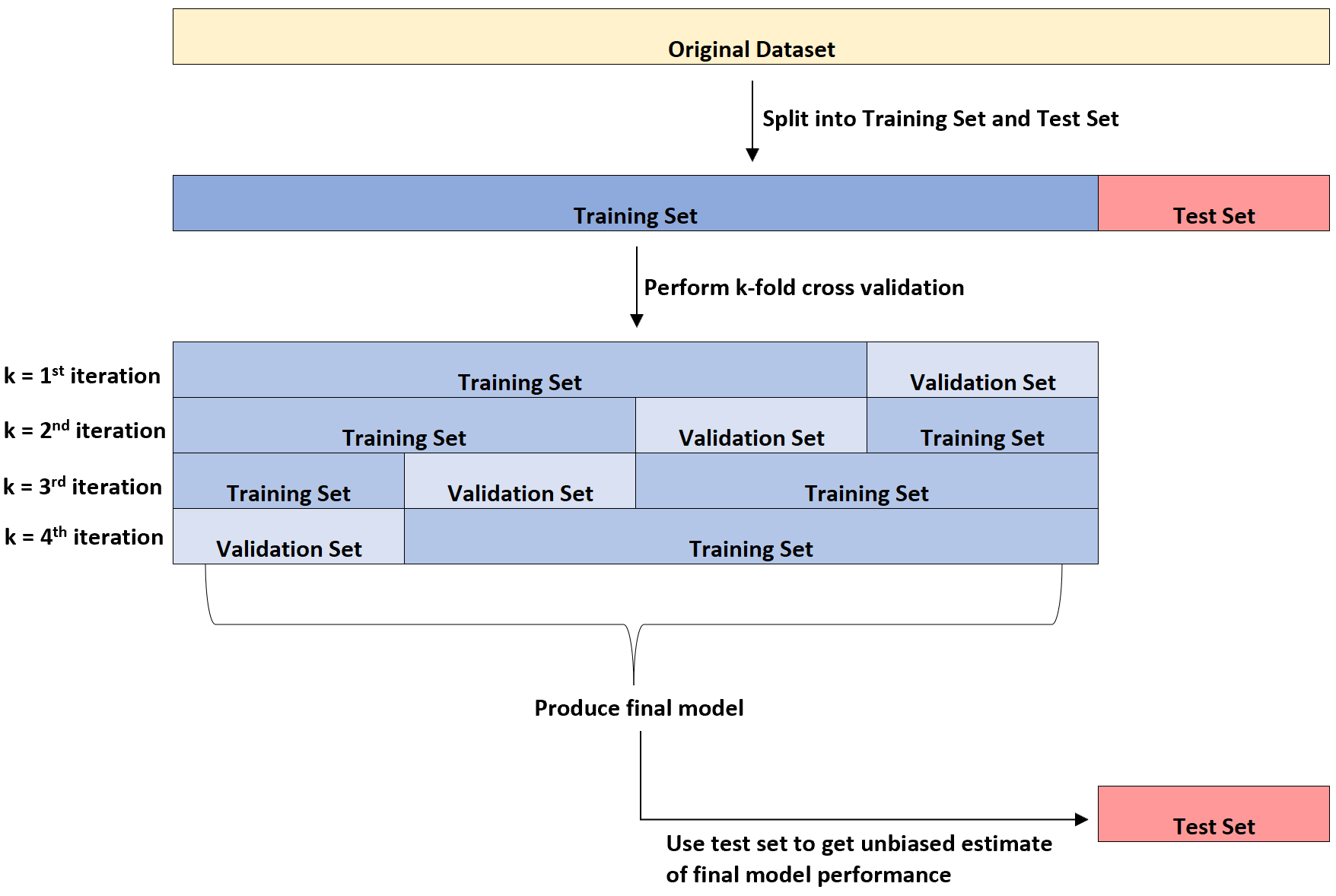
Un point de confusion pour les étudiants est la différence entre l’ensemble de validation et l’ensemble de test.
En termes simples, l’ ensemble de validation est utilisé pour optimiser les paramètres du modèle tandis que l’ ensemble de test est utilisé pour fournir une estimation impartiale du modèle final.
On peut montrer que le taux d’erreur tel que mesuré par la validation croisée k fois a tendance à sous-estimer le taux d’erreur réel une fois que le modèle est appliqué à un ensemble de données invisible.
Ainsi, nous ajustons le modèle final à l’ensemble de test pour obtenir une estimation impartiale de ce que sera le véritable taux d’erreur dans le monde réel.
L’exemple suivant illustre la différence entre un ensemble de validation et un ensemble de test dans la pratique.
Exemple : Comprendre la différence entre l’ensemble de validation et l’ensemble de test
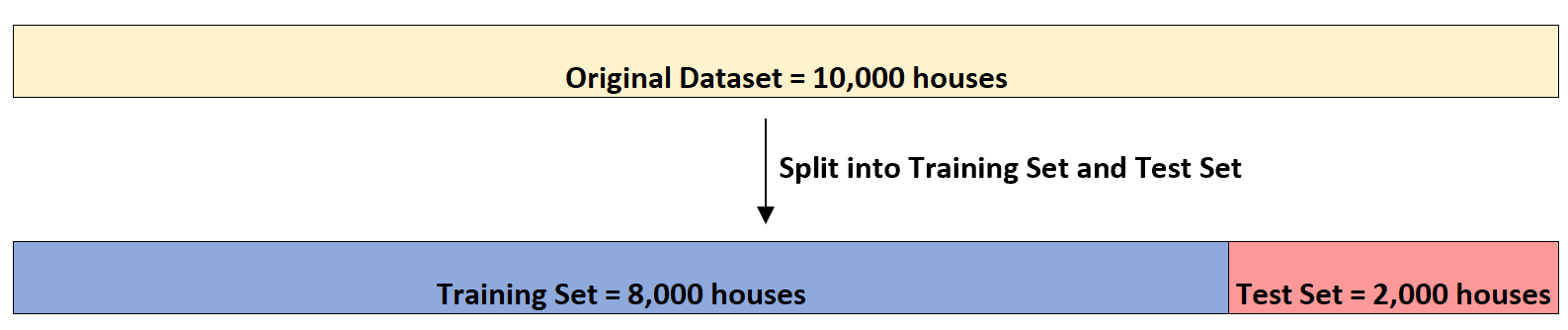
Supposons qu’un investisseur immobilier souhaite utiliser (1) le nombre de chambres, (2) le nombre total de pieds carrés et (3) le nombre de salles de bains pour prédire le prix de vente d’une maison donnée.
Supposons qu’il dispose d’un ensemble de données contenant ces informations sur 10 000 maisons. Tout d’abord, il divisera l’ensemble de données en un ensemble d’entraînement de 8 000 maisons et un ensemble de test de 2 000 maisons :
Ensuite, il ajustera quatre fois un modèle de régression linéaire multiple à l’ensemble de données. Il utilisera à chaque fois 6 000 maisons pour l’ensemble de formation et 2 000 maisons pour l’ensemble de validation.
C’est ce qu’on appelle la validation croisée k-fold.
L’ensemble de formation est utilisé pour entraîner le modèle et l’ensemble de validation est utilisé pour évaluer les performances du modèle. Il utilisera à chaque fois un groupe différent de 2 000 maisons pour l’ensemble de validation.
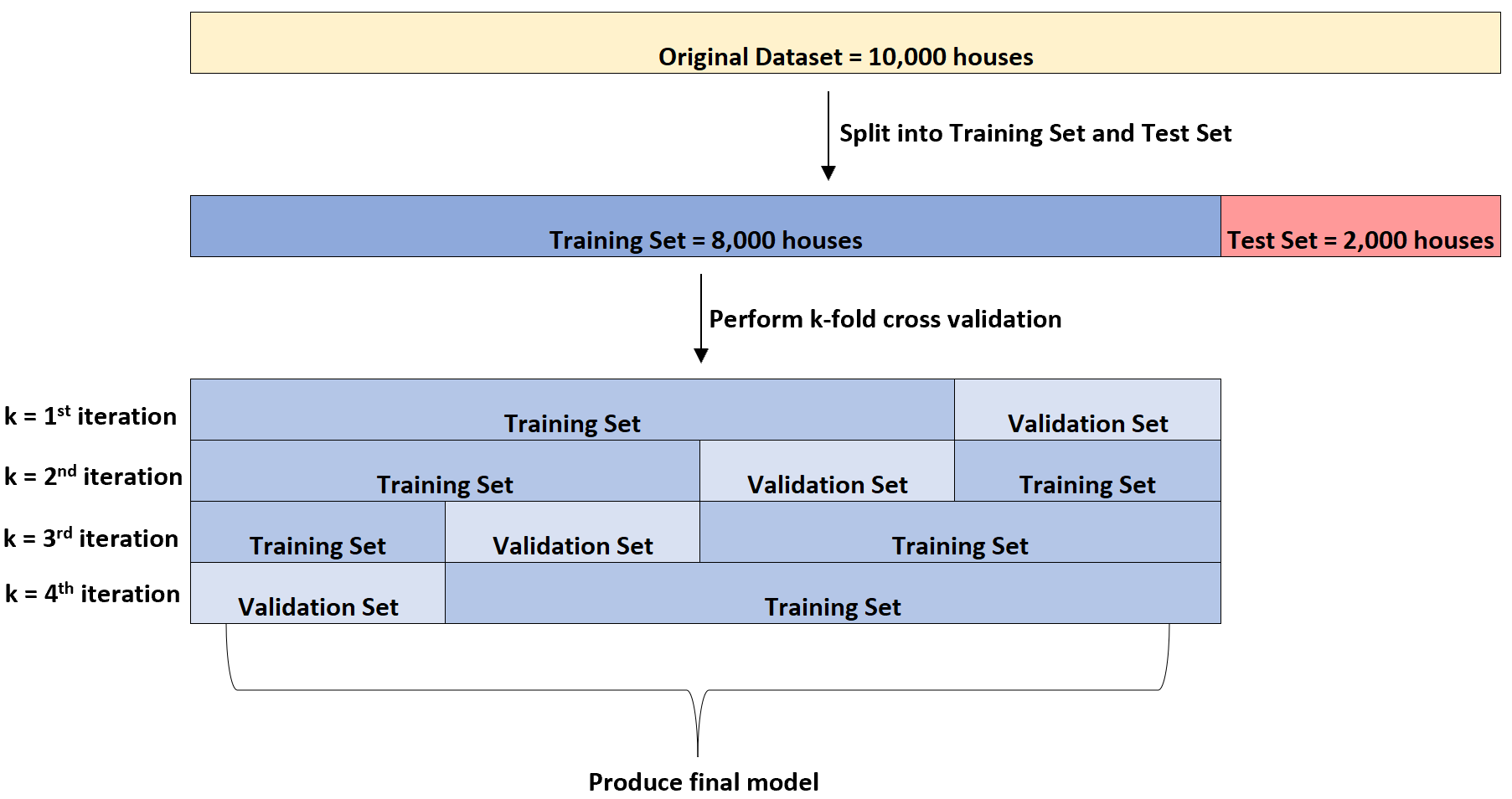
Il peut effectuer cette validation croisée k fois sur plusieurs types différents de modèles de régression pour identifier le modèle qui présente l’erreur la plus faible (c’est-à-dire identifier le modèle qui correspond le mieux à l’ensemble de données).
Ce n’est qu’une fois qu’il aura identifié le meilleur modèle qu’il utilisera l’ensemble de tests de 2 000 maisons qu’il a présenté au début pour obtenir une estimation impartiale des performances finales du modèle.
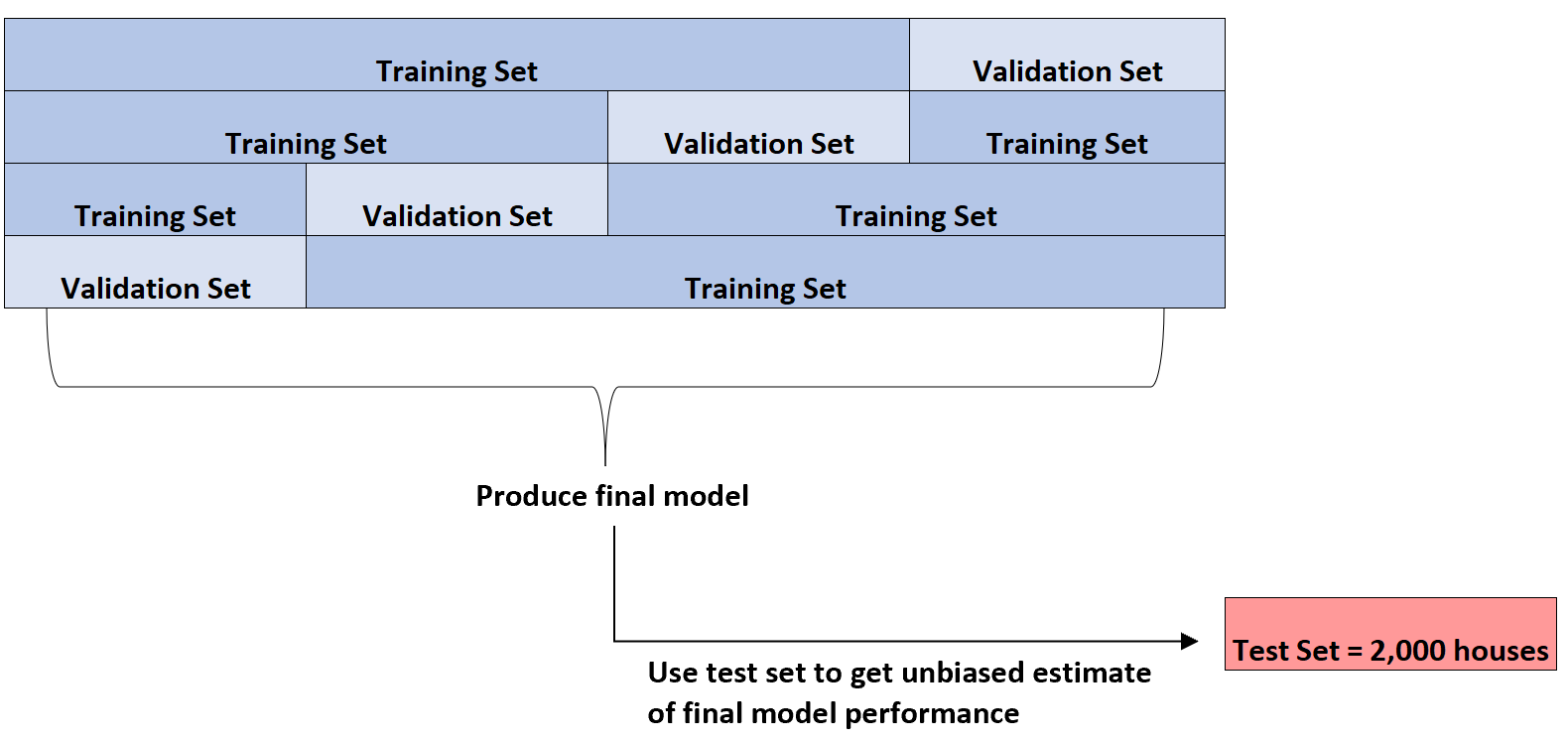
Par exemple, il pourrait identifier un type spécifique de modèle de régression dont l’erreur absolue moyenne est de 8 345 . Autrement dit, la différence absolue moyenne entre le prix prévu du logement et le prix réel du logement est de 8 345 $.
Il pourra ensuite adapter ce modèle de régression exact à l’ensemble test de 2 000 maisons qui n’a pas encore été utilisé et constater que l’erreur absolue moyenne du modèle est de 8 847 .
Ainsi, l’estimation impartiale de la véritable erreur absolue moyenne du modèle est de 8 847 $.
Ressources additionnelles
Un guide simple sur la validation croisée K-Fold
Comment effectuer une validation croisée K-Fold en Python
Comment effectuer une validation croisée K-Fold dans R
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus