지도 및 비지도 학습에 대한 빠른 소개
기계 학습 분야에는 데이터를 이해하는 데 사용할 수 있는 방대한 알고리즘 세트가 포함되어 있습니다. 이러한 알고리즘은 다음 두 가지 범주 중 하나로 분류될 수 있습니다.
1. 지도 학습 알고리즘: 하나 이상의 입력을 기반으로 결과를 추정하거나 예측하는 모델을 구축하는 작업이 포함됩니다.
2. 비지도 학습 알고리즘: 입력에서 구조와 관계를 찾는 것이 포함됩니다. “감독” 출력은 없습니다.
이 튜토리얼에서는 이러한 두 가지 유형의 알고리즘 간의 차이점을 각각의 몇 가지 예와 함께 설명합니다.
지도 학습 알고리즘
지도 학습 알고리즘은 하나 이상의 설명 변수 ( X1 , 응답 변수 :
Y = f (X) + ε
여기서 f는 X가 Y에 대해 제공하는 체계적인 정보를 나타내고, ε은 평균이 0인 X와 독립적인 무작위 오류 항입니다.
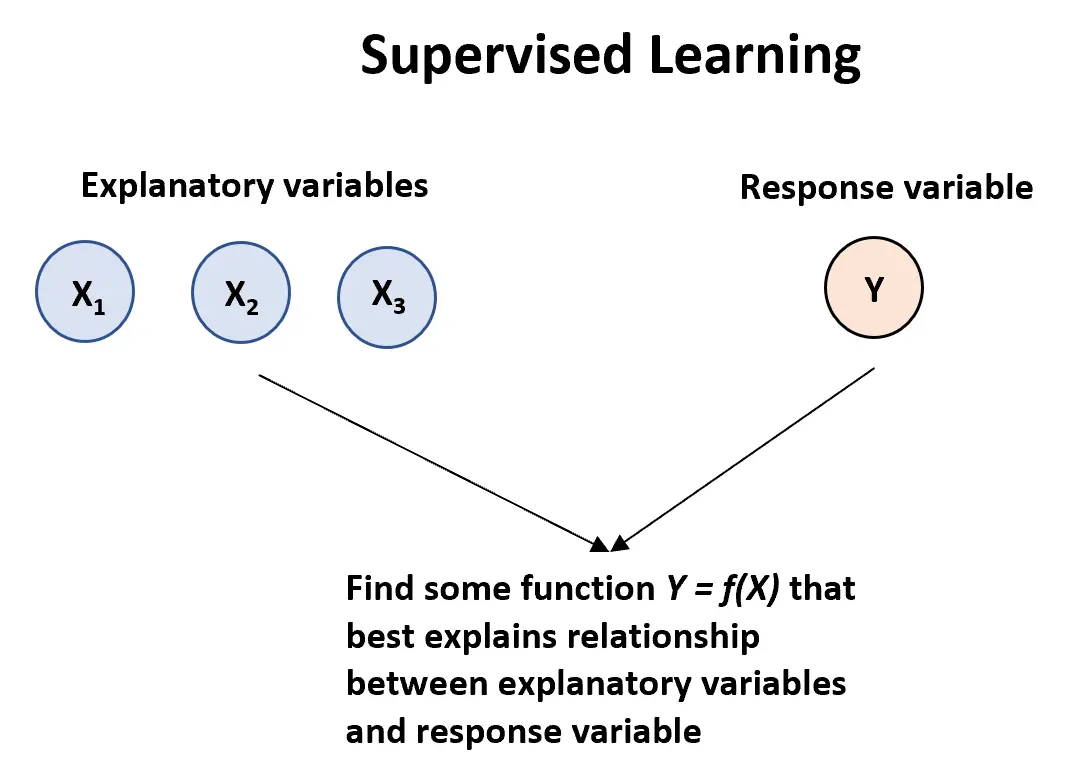
지도 학습 알고리즘에는 두 가지 주요 유형이 있습니다.
1. 회귀: 출력 변수는 연속적입니다(예: 체중, 키, 시간 등).
2. 분류: 출력 변수는 범주형입니다(예: 남성 또는 여성, 성공 또는 실패, 양성 또는 악성 등).
지도 학습 알고리즘을 사용하는 두 가지 주요 이유는 다음과 같습니다.
1. 예측: 우리는 반응 변수의 값을 예측하기 위해 일련의 설명 변수를 사용하는 경우가 많습니다(예: 주택 가격을 예측하기 위해 평방 피트 와 침실 수를 사용).
2. 추론: 설명 변수의 값이 변할 때 반응 변수가 어떻게 영향을 받는지 이해하는 데 관심이 있을 수 있습니다(예: 방 수가 하나 증가하면 부동산 가격은 평균 얼마나 오르나요?)
목표가 추론인지 예측인지(또는 둘의 혼합)인지에 따라 다양한 방법을 사용하여 함수 f 를 추정할 수 있습니다. 예를 들어, 선형 모델은 더 쉬운 해석을 제공하지만, 해석하기 어려운 비선형 모델은 더 정확한 예측을 제공할 수 있습니다.
다음은 가장 일반적으로 사용되는 지도 학습 알고리즘 목록입니다.
- 선형 회귀
- 로지스틱 회귀
- 선형 판별 분석
- 2차 판별 분석
- 의사결정 트리
- 나이브 베이즈
- 지원 벡터 머신
- 신경망
비지도 학습 알고리즘
비지도 학습 알고리즘은 변수 목록 ( X 1 , data.
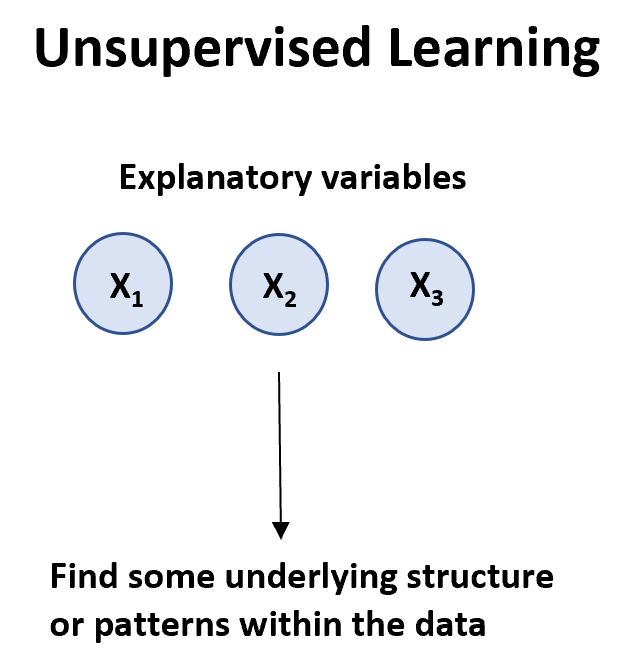
비지도 학습 알고리즘에는 두 가지 주요 유형이 있습니다.
1. 클러스터링: 이러한 유형의 알고리즘을 사용하여 데이터 세트에서 서로 유사한 관측값 의 “클러스터”를 찾으려고 합니다. 이는 기업이 유사한 구매 습관을 가진 고객 그룹을 식별하여 특정 고객 그룹을 대상으로 하는 특정 마케팅 전략을 만들려는 소매업에서 자주 사용됩니다.
2. 연관: 이러한 유형의 알고리즘을 사용하여 연관을 설정하는 데 사용할 수 있는 “규칙”을 찾으려고 노력합니다. 예를 들어, 소매업체는 “고객이 X 제품을 구매하면 Y 제품도 구매할 가능성이 매우 높다”는 것을 나타내는 연관 알고리즘을 개발할 수 있습니다.
다음은 가장 일반적으로 사용되는 비지도 학습 알고리즘 목록입니다.
- 주요 구성 요소 분석
- K-평균 클러스터링
- K-medoid의 그룹화
- 계층적 분류
- 선험적 알고리즘
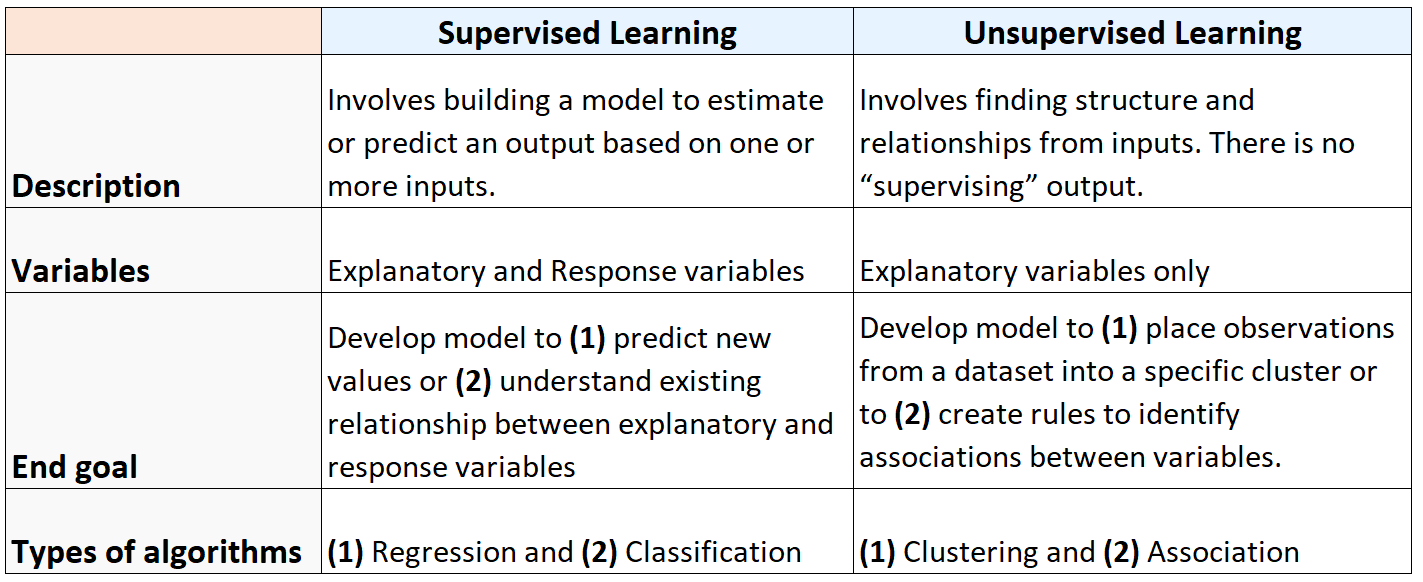
요약: 지도 학습 또는 비지도 학습
다음 표에는 지도 학습 알고리즘과 비지도 학습 알고리즘의 차이점이 요약되어 있습니다.
다음 다이어그램은 기계 학습 알고리즘의 유형을 요약합니다.

저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기