Ridge & lasso 회귀를 사용해야 하는 경우
일반적인 다중 선형 회귀 에서는 p개의 예측 변수 세트와 응답 변수를 사용하여 다음 형식의 모델에 적합합니다.
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p
β 0 , β 1 , B 2 , …, β p 값은 잔차 제곱합(RSS)을 최소화하는 최소 제곱법을 사용하여 선택됩니다.
RSS = Σ(y i – ŷ i ) 2
금:
- Σ : 합계를 뜻하는 기호
- y i : i번째 관측값에 대한 실제 응답 값
- ŷ i : i 번째 관측치에 대한 예측 반응 값
회귀분석의 다중공선성 문제
다중 선형 회귀 분석에서 실제로 자주 발생하는 문제는 다중 공선성 입니다. 즉, 두 개 이상의 예측 변수가 서로 높은 상관 관계를 갖고 있어 회귀 모델에서 고유하거나 독립적인 정보를 제공하지 않는 경우입니다.
이로 인해 모델 계수 추정이 신뢰할 수 없게 되고 높은 분산이 나타날 수 있습니다. 즉, 이전에 본 적이 없는 새로운 데이터 세트에 모델을 적용하면 성능이 저하될 가능성이 높습니다.
다중 공선성 방지: Ridge & Lasso 회귀
이 다중 공선성 문제를 해결하는 데 사용할 수 있는 두 가지 방법은 능선 회귀 와 올가미 회귀 입니다.
능형 회귀는 다음을 최소화하려고 합니다.
- RSS + λΣβ j 2
올가미 회귀는 다음을 최소화하려고 합니다.
- RSS + λΣ|β j |
두 방정식 모두에서 두 번째 항을 인출 페널티 라고 합니다.
λ = 0인 경우 이 페널티 항은 효과가 없으며 능선 회귀 및 올가미 회귀는 최소 제곱과 동일한 계수 추정치를 생성합니다.
그러나 λ가 무한대에 접근하면 수축 패널티의 영향력이 커지고 모델에 가져올 수 없는 예측 변수는 0으로 감소합니다.
올가미 회귀를 사용하면 λ가 충분히 커지면 일부 계수가 완전히 0이 될 수 있습니다.
Ridge & Lasso 회귀 분석의 장점과 단점
최소 제곱 회귀에 비해 Ridge 및 Lasso 회귀의 장점 은 편향-분산 트레이드오프 입니다.
MSE(평균 제곱 오차)는 특정 모델의 정확도를 측정하는 데 사용할 수 있는 측정항목이며 다음과 같이 계산됩니다.
MSE = Var( f̂( x 0 )) + [바이어스( f̂( x 0 ))] 2 + Var(ε)
MSE = 분산 + 편향 2 + 비가역 오류
Ridge Regression과 Lasso Regression의 기본 아이디어는 작은 편향을 도입하여 분산을 크게 줄여 전체 MSE를 낮추는 것입니다.
이를 설명하기 위해 다음 그래프를 고려하십시오.

λ가 증가하면 편향이 아주 조금만 증가해도 분산이 크게 감소합니다. 그러나 특정 지점을 넘어서면 분산이 덜 빠르게 감소하고 계수가 감소하면 계수가 크게 과소평가되어 편향이 급격히 증가합니다.
그래프에서 편향과 분산 사이의 최적의 균형을 생성하는 λ 값을 선택할 때 테스트의 MSE가 가장 낮다는 것을 알 수 있습니다.
λ = 0인 경우 올가미 회귀 분석의 페널티 항은 효과가 없으므로 최소 제곱과 동일한 계수 추정값을 생성합니다. 그러나 λ를 특정 지점까지 증가시키면 테스트의 전체 MSE를 줄일 수 있습니다.
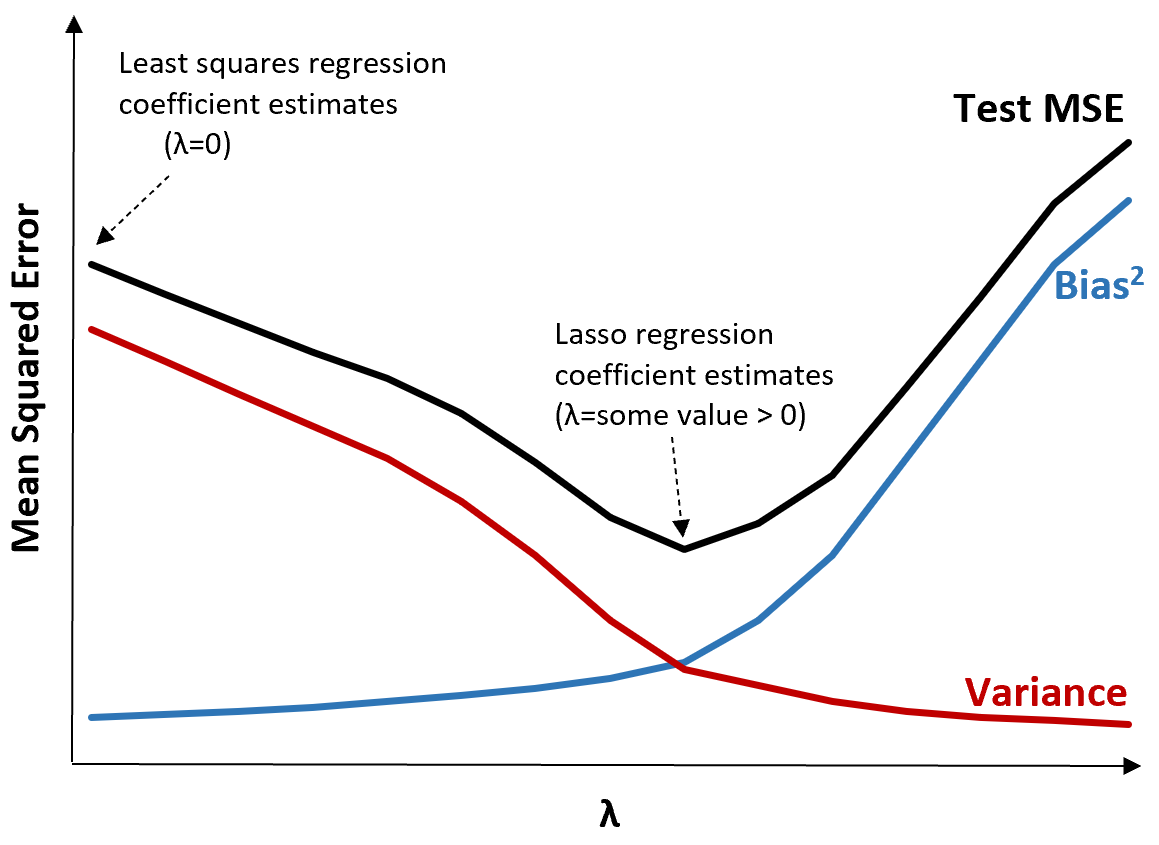
이는 능선 및 올가미 회귀에 의한 모델 피팅이 최소 제곱 회귀에 의한 모델 피팅보다 잠재적으로 더 작은 테스트 오류를 생성할 수 있음을 의미합니다.
Ridge and Lasso 회귀의 단점 은 최종 모델의 계수가 0으로 줄어들면서 해석하기가 어렵다는 것입니다.
따라서 추론보다는 예측 능력을 최적화하려는 경우 능형 및 올가미 회귀를 사용해야 합니다.
능선 대. 올가미 회귀: 각 사용 시기
L asso 회귀와 능형 회귀는 둘 다 RSS(잔차 제곱합)와 특정 페널티 항을 최소화하려고 시도하기 때문에 정규화 방법 으로 알려져 있습니다.
즉, 모델 계수의 추정치를 제한하거나 정규화합니다 .
이것은 자연스럽게 질문을 제기합니다: 능선 회귀 또는 올가미 회귀가 더 나은가요?
소수의 예측 변수만 유의미한 경우 올가미 회귀는 중요하지 않은 변수를 0으로 완전히 줄이고 모델에서 제거할 수 있기 때문에 더 잘 작동하는 경향이 있습니다.
그러나 많은 예측 변수가 모델에서 중요하고 해당 계수가 대략 동일한 경우 능선 회귀는 모델의 모든 예측 변수를 유지하므로 더 잘 작동하는 경향이 있습니다.
예측에 가장 적합한 모델을 결정하기 위해 일반적으로 k-겹 교차 검증을 수행하고 테스트 평균 제곱근 오차가 가장 낮은 모델을 선택합니다.
추가 리소스
다음 자습서에서는 Ridge Regression 및 Lasso Regression에 대해 소개합니다.
다음 자습서에서는 R 및 Python에서 두 가지 유형의 회귀를 수행하는 방법을 설명합니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기