완전 다중공선성이란 무엇인가요? (정의 및 예)
통계에서 다중 공선성은 두 개 이상의 예측 변수가 서로 높은 상관관계를 갖고 있어 회귀 모델에서 고유하거나 독립적인 정보를 제공하지 않을 때 발생합니다.
변수 간의 상관 정도가 충분히 높으면 회귀 모델을 피팅하고 해석할 때 문제가 발생할 수 있습니다.
다중공선성의 가장 극단적인 경우를 완전 다중공선성 이라고 합니다. 이는 두 개 이상의 예측 변수가 서로 정확한 선형 관계를 가질 때 발생합니다.
예를 들어 다음과 같은 데이터 세트가 있다고 가정해 보겠습니다.
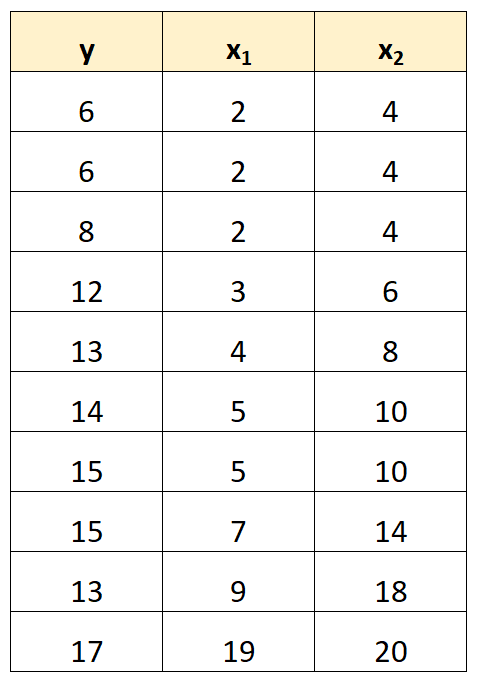
예측 변수 x 2 의 값은 단순히 x 1 의 값에 2를 곱한 값이라는 점에 유의하세요.
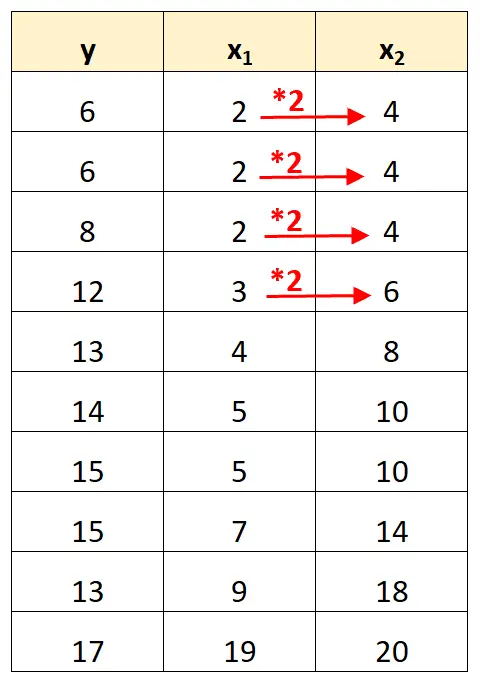
이는 완벽한 다중공선성의 예입니다.
완전 다중공선성의 문제
데이터 세트에 완벽한 다중 공선성이 있는 경우 일반 최소 제곱법은 회귀 계수 추정치를 생성할 수 없습니다.
실제로, 다른 예측 변수(x 2 )를 일정하게 유지하면서 응답 변수(y)에 대한 예측 변수(x 1 )의 한계 효과를 추정하는 것은 불가능합니다. 왜냐하면 x 1 이 움직일 때 항상 x 2 가 정확하게 움직이기 때문입니다.
즉, 완벽한 다중 공선성은 회귀 모델의 각 계수에 대한 값을 추정하는 것을 불가능하게 만듭니다.
완벽한 다중공선성을 다루는 방법
완벽한 다중공선성을 처리하는 가장 간단한 방법은 다른 변수와 정확한 선형 관계를 갖는 변수 중 하나를 제거하는 것입니다.
예를 들어 이전 데이터세트에서는 예측 변수인 x 2를 간단히 제거할 수 있었습니다.
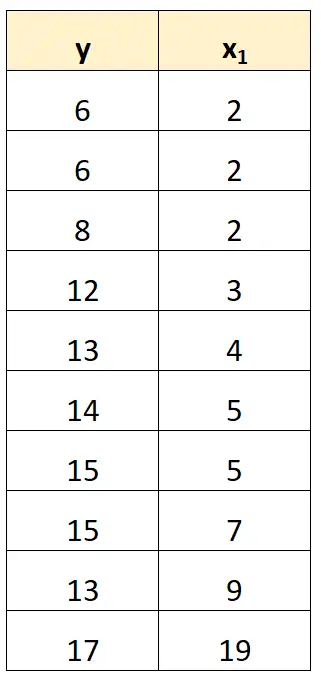
그런 다음 x 1을 예측 변수로 사용하고 y를 응답 변수로 사용하여 회귀 모델을 적합합니다.
완벽한 다중공선성의 예
다음 예에서는 실제로 완벽한 다중 공선성의 가장 일반적인 세 가지 시나리오를 보여줍니다.
1. 예측 변수는 다른 예측 변수의 배수입니다.
특정 종의 돌고래의 체중을 예측하기 위해 “센티미터 단위의 키”와 “미터 단위의 키”를 사용한다고 가정해 보겠습니다.
데이터 세트는 다음과 같습니다.
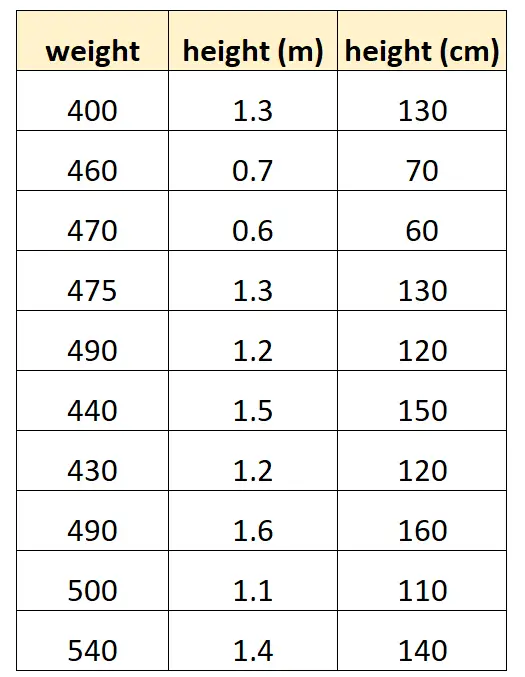
“센티미터 단위의 높이” 값은 단순히 “미터 단위의 높이”에 100을 곱한 값과 같습니다. 이는 완벽한 다중 공선성의 경우입니다.
이 데이터 세트를 사용하여 R에서 다중 선형 회귀 모델을 맞추려고 하면 예측 변수 “미터”에 대한 계수 추정치를 생성할 수 없습니다.
#define data df <- data. frame (weight=c(400, 460, 470, 475, 490, 440, 430, 490, 500, 540), m=c(1.3, .7, .6, 1.3, 1.2, 1.5, 1.2, 1.6, 1.1, 1.4), cm=c(130, 70, 60, 130, 120, 150, 120, 160, 110, 140)) #fit multiple linear regression model model <- lm(weight~m+cm, data=df) #view summary of model summary(model) Call: lm(formula = weight ~ m + cm, data = df) Residuals: Min 1Q Median 3Q Max -70,501 -25,501 5,183 19,499 68,590 Coefficients: (1 not defined because of singularities) Estimate Std. Error t value Pr(>|t|) (Intercept) 458,676 53,403 8,589 2.61e-05 *** m 9.096 43.473 0.209 0.839 cm NA NA NA NA --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 41.9 on 8 degrees of freedom Multiple R-squared: 0.005442, Adjusted R-squared: -0.1189 F-statistic: 0.04378 on 1 and 8 DF, p-value: 0.8395
2. 예측변수는 다른 예측변수의 변환된 버전입니다.
농구 선수의 등급을 예측하기 위해 “포인트”와 “조정 포인트”를 사용한다고 가정해 보겠습니다.
변수 “scaled points”가 다음과 같이 계산된다고 가정합니다.
스케일링된 포인트 = (포인트 – μ 포인트 ) / σ 포인트
데이터 세트는 다음과 같습니다.
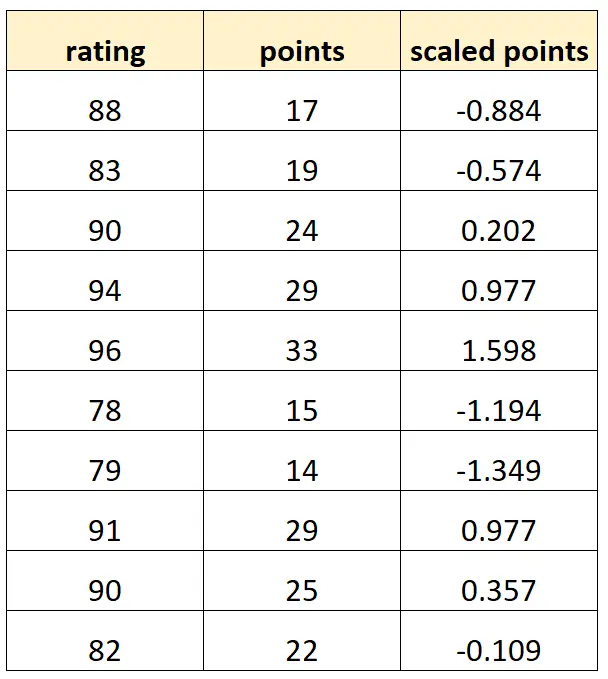
각 “조정된 포인트” 값은 단순히 “포인트”의 표준화된 버전입니다. 이는 완벽한 다중공선성의 경우입니다.
이 데이터 세트를 사용하여 R에서 다중 선형 회귀 모델을 맞추려고 하면 “조정된 점” 예측 변수에 대한 계수 추정치를 생성할 수 없습니다.
#define data df <- data. frame (rating=c(88, 83, 90, 94, 96, 78, 79, 91, 90, 82), pts=c(17, 19, 24, 29, 33, 15, 14, 29, 25, 22)) df$scaled_pts <- (df$pts - mean(df$pts)) / sd(df$pts) #fit multiple linear regression model model <- lm(rating~pts+scaled_pts, data=df) #view summary of model summary(model) Call: lm(formula = rating ~ pts + scaled_pts, data = df) Residuals: Min 1Q Median 3Q Max -4.4932 -1.3941 -0.2935 1.3055 5.8412 Coefficients: (1 not defined because of singularities) Estimate Std. Error t value Pr(>|t|) (Intercept) 67.4218 3.5896 18.783 6.67e-08 *** pts 0.8669 0.1527 5.678 0.000466 *** scaled_pts NA NA NA NA --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 2.953 on 8 degrees of freedom Multiple R-squared: 0.8012, Adjusted R-squared: 0.7763 F-statistic: 32.23 on 1 and 8 DF, p-value: 0.0004663
3. 더미변수 트랩
완벽한 다중 공선성이 발생할 수 있는 또 다른 시나리오는 더미 변수 트랩 으로 알려져 있습니다. 회귀 모델에서 범주형 변수를 가져와 이를 0, 1, 2 등의 값을 취하는 “더미 변수”로 변환하려는 경우입니다.
예를 들어, 소득을 예측하기 위해 예측 변수 “나이”와 “결혼 상태”를 사용한다고 가정해 보겠습니다.

“결혼 여부”를 예측변수로 사용하려면 먼저 이를 더미변수로 변환해야 합니다.
이렇게 하려면 가장 자주 발생하므로 “Single”을 기본 값으로 두고 다음과 같이 “Married” 및 “Divorce”에 0 또는 1의 값을 할당할 수 있습니다.

실수는 다음과 같이 세 개의 새로운 더미 변수를 만드는 것입니다.
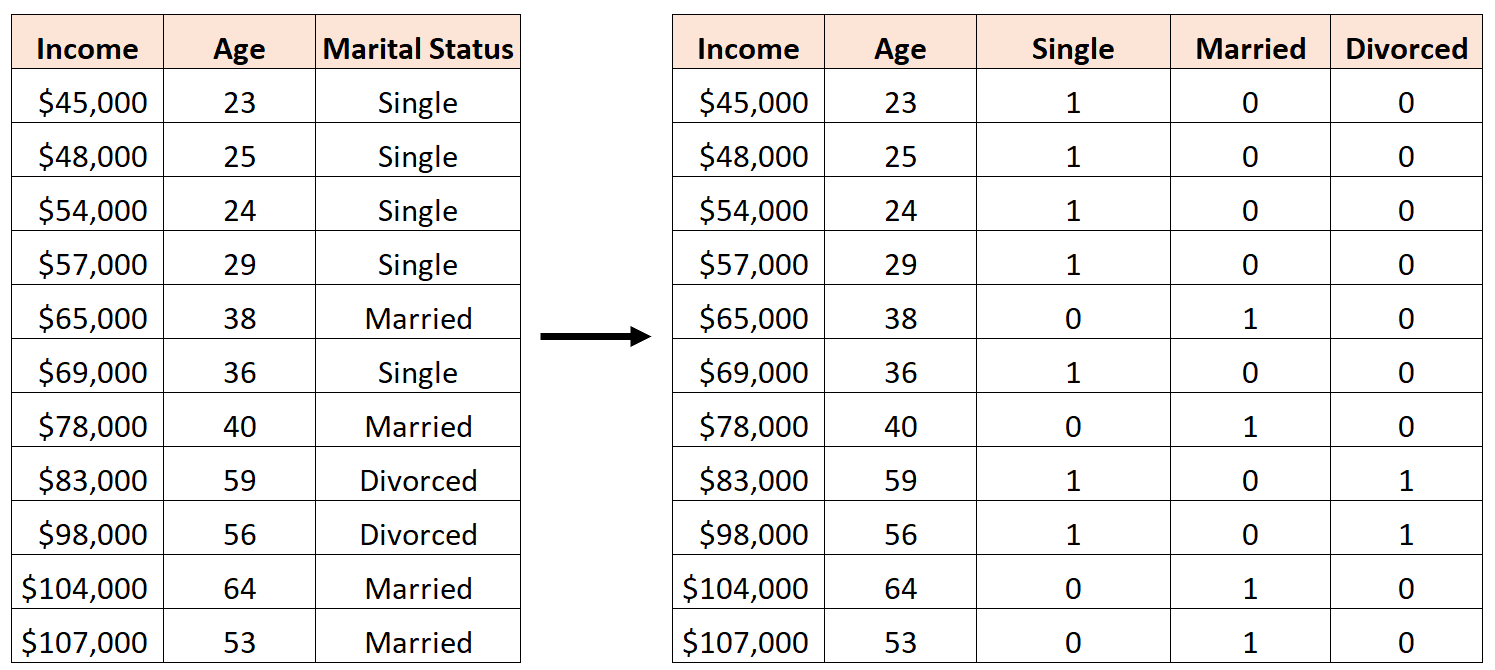
이 경우 “미혼” 변수는 “기혼” 변수와 “이혼” 변수의 완벽한 선형 조합입니다. 이는 완벽한 다중공선성의 예입니다.
이 데이터 세트를 사용하여 R에서 다중 선형 회귀 모델을 맞추려고 하면 각 예측 변수에 대한 계수 추정치를 생성할 수 없습니다.
#define data df <- data. frame (income=c(45, 48, 54, 57, 65, 69, 78, 83, 98, 104, 107), age=c(23, 25, 24, 29, 38, 36, 40, 59, 56, 64, 53), single=c(1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 0), married=c(0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1), divorced=c(0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0)) #fit multiple linear regression model model <- lm(income~age+single+married+divorced, data=df) #view summary of model summary(model) Call: lm(formula = income ~ age + single + married + divorced, data = df) Residuals: Min 1Q Median 3Q Max -9.7075 -5.0338 0.0453 3.3904 12.2454 Coefficients: (1 not defined because of singularities) Estimate Std. Error t value Pr(>|t|) (Intercept) 16.7559 17.7811 0.942 0.37739 age 1.4717 0.3544 4.152 0.00428 ** single -2.4797 9.4313 -0.263 0.80018 married NA NA NA NA divorced -8.3974 12.7714 -0.658 0.53187 --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 8.391 on 7 degrees of freedom Multiple R-squared: 0.9008, Adjusted R-squared: 0.8584 F-statistic: 21.2 on 3 and 7 DF, p-value: 0.0006865
추가 리소스
회귀 분석의 다중 공선성과 VIF에 대한 가이드
R에서 VIF를 계산하는 방법
Python에서 VIF를 계산하는 방법
Excel에서 VIF를 계산하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기